 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextShift: A Controlled Benchmark for Context Dependence in Object Detection
Jun 08, 2026Modern object detectors achieve strong performance on standard benchmarks, yet their robustness to contextual variation remains insufficiently understood. Prior evaluations largely rely on aggregate metrics such as AP on uncontrolled distribution shifts, which can obscure how performance degrades under context change. We introduce ContextShift, a controlled benchmark that systematically manipulates object--context relationships while preserving object appearance. Built on COCO 2017, it isolates context as an independent variable through geometric transformations and synthetic and natural background substitutions, including a continuous compatibility axis based on normalized pointwise mutual information (NPMI). Across diverse detector architectures, we observe a consistent degradation pattern: false negatives increase by up to 227% and prediction volume decreases by up to 44%, while false positives remain stable or decline. This suppression behavior is not captured by aggregate metrics such as AP, which can mask substantial recall loss and changes in prediction dynamics. Further analysis suggests that degradation is driven less by reduced confidence than by a reduced formation of valid detection candidates. Moreover, performance along the statistical compatibility axis is non-monotonic, peaking at intermediate NPMI and degrading toward both extremes, indicating that statistical co-occurrence does not correlate linearly with effective visual context. Finally, we show that context-aware augmentation improves robustness: every augmented variant outperforms the dataset-only baseline on both original and manipulated test images, partially recovering performance lost to prediction-suppression failures by exposing models to object--context decoupling during training.
EMAG: Differentiable 4D Gaussian Mixture Splatting for EEG Spatial Super-Resolution
May 28, 2026High-density electroencephalography (HD-EEG) enables fine-grained measurement of cortical activity but requires expensive hardware and lengthy setup times, limiting its clinical and research accessibility. We propose EMAG (EEG Mixture of Anisotropic Gaussians), a differentiable framework that reconstructs HD-EEG signals from a sparse subset of low-density (LD) electrodes by representing brain electrical sources as a mixture of anisotropic 4D space-time Gaussians. EMAG places a mixture of multiple Gaussians at each point of a spherical brain grid, each parameterized by a full 4 x 4 precision matrix, enabling anisotropic spatial spreads and explicit coupling between spatial and temporal dimensions. The forward model renders scalp EEG via differentiable Gaussian field contributions at electrode locations, enabling end-to-end training without explicit source localization supervision. We evaluate EMAG on three public EEG benchmarks (Localize-MI, SEED, and SEED-IV) at super-resolution factors of 2x through 8/16x. EMAG outperforms the current state-of-the-art EEG super-resolution method at most super-resolution factors on three standard benchmarks (Localize-MI, SEED, SEED-IV). The explicit Gaussian parameterization further enables direct visualization and interpretability of learned brain source configurations, potentially opening avenues for clinical and neuroscientific applications, such as source localization or biomarker discovery.
The Missing GAP: From Solving Square Jigsaw Puzzles to Handling Real World Archaeological Fragments
May 12, 2026Jigsaw puzzle solving has been an increasingly popular task in the computer vision research community. Recent works have utilized cutting-edge architectures and computational approaches to reassemble groups of pieces into a coherent image, while achieving increasingly good results on well established datasets. However, most of these approaches share a common, restricting setting: operating solely on strictly square puzzle pieces. In this work, we introduce GAP, a set of novel jigsaw puzzles datasets containing synthetic, heavily eroded pieces of unrestricted shapes, generated by a learned distribution of real-world archaeological fragments. We also introduce PuzzleFlow, a novel ViT and Flow-Matching based framework for jigsaw puzzle solving, capable of handling complex puzzle pieces and demonstrating superior performance on GAP when compared to both classic and recent prominent works in this domain.
Seq2Seq Models Reconstruct Visual Jigsaw Puzzles without Seeing Them
Nov 09, 2025Jigsaw puzzles are primarily visual objects, whose algorithmic solutions have traditionally been framed from a visual perspective. In this work, however, we explore a fundamentally different approach: solving square jigsaw puzzles using language models, without access to raw visual input. By introducing a specialized tokenizer that converts each puzzle piece into a discrete sequence of tokens, we reframe puzzle reassembly as a sequence-to-sequence prediction task. Treated as "blind" solvers, encoder-decoder transformers accurately reconstruct the original layout by reasoning over token sequences alone. Despite being deliberately restricted from accessing visual input, our models achieve state-of-the-art results across multiple benchmarks, often outperforming vision-based methods. These findings highlight the surprising capability of language models to solve problems beyond their native domain, and suggest that unconventional approaches can inspire promising directions for puzzle-solving research.
Solving Convex Partition Visual Jigsaw Puzzles
Nov 06, 2025Jigsaw puzzle solving requires the rearrangement of unordered pieces into their original pose in order to reconstruct a coherent whole, often an image, and is known to be an intractable problem. While the possible impact of automatic puzzle solvers can be disruptive in various application domains, most of the literature has focused on developing solvers for square jigsaw puzzles, severely limiting their practical use. In this work, we significantly expand the types of puzzles handled computationally, focusing on what is known as Convex Partitions, a major subset of polygonal puzzles whose pieces are convex. We utilize both geometrical and pictorial compatibilities, introduce a greedy solver, and report several performance measures next to the first benchmark dataset of such puzzles.
Recognizing Artistic Style of Archaeological Image Fragments Using Deep Style Extrapolation
Jan 01, 2025Ancient artworks obtained in archaeological excavations usually suffer from a certain degree of fragmentation and physical degradation. Often, fragments of multiple artifacts from different periods or artistic styles could be found on the same site. With each fragment containing only partial information about its source, and pieces from different objects being mixed, categorizing broken artifacts based on their visual cues could be a challenging task, even for professionals. As classification is a common function of many machine learning models, the power of modern architectures can be harnessed for efficient and accurate fragment classification. In this work, we present a generalized deep-learning framework for predicting the artistic style of image fragments, achieving state-of-the-art results for pieces with varying styles and geometries.
Re-assembling the past: The RePAIR dataset and benchmark for real world 2D and 3D puzzle solving
Oct 31, 2024



This paper proposes the RePAIR dataset that represents a challenging benchmark to test modern computational and data driven methods for puzzle-solving and reassembly tasks. Our dataset has unique properties that are uncommon to current benchmarks for 2D and 3D puzzle solving. The fragments and fractures are realistic, caused by a collapse of a fresco during a World War II bombing at the Pompeii archaeological park. The fragments are also eroded and have missing pieces with irregular shapes and different dimensions, challenging further the reassembly algorithms. The dataset is multi-modal providing high resolution images with characteristic pictorial elements, detailed 3D scans of the fragments and meta-data annotated by the archaeologists. Ground truth has been generated through several years of unceasing fieldwork, including the excavation and cleaning of each fragment, followed by manual puzzle solving by archaeologists of a subset of approx. 1000 pieces among the 16000 available. After digitizing all the fragments in 3D, a benchmark was prepared to challenge current reassembly and puzzle-solving methods that often solve more simplistic synthetic scenarios. The tested baselines show that there clearly exists a gap to fill in solving this computationally complex problem.
Multi-Phase Relaxation Labeling for Square Jigsaw Puzzle Solving
Mar 26, 2023We present a novel method for solving square jigsaw puzzles based on global optimization. The method is fully automatic, assumes no prior information, and can handle puzzles with known or unknown piece orientation. At the core of the optimization process is nonlinear relaxation labeling, a well-founded approach for deducing global solutions from local constraints, but unlike the classical scheme here we propose a multi-phase approach that guarantees convergence to feasible puzzle solutions. Next to the algorithmic novelty, we also present a new compatibility function for the quantification of the affinity between adjacent puzzle pieces. Competitive results and the advantage of the multi-phase approach are demonstrated on standard datasets.
* 10 pages, 7 figures. Published in Proceedings of the 18th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications - Volume 4 VISAPP: VISAPP, 785-795, 2023
Lazy caterer jigsaw puzzles: Models, properties, and a mechanical system-based solver
Aug 17, 2020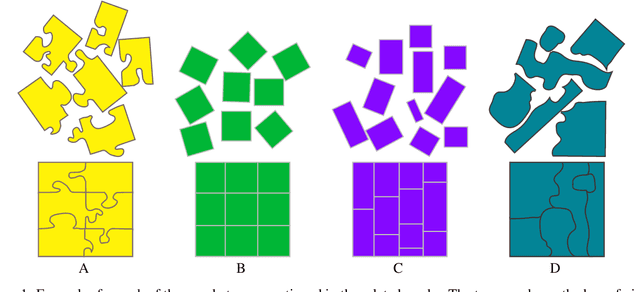
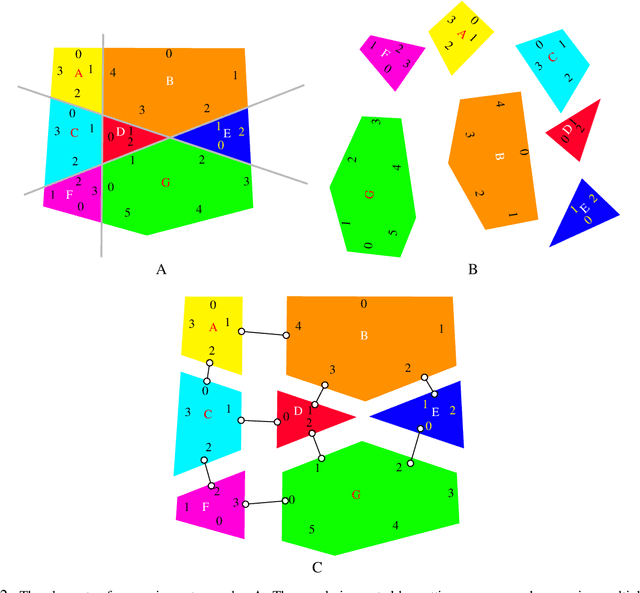
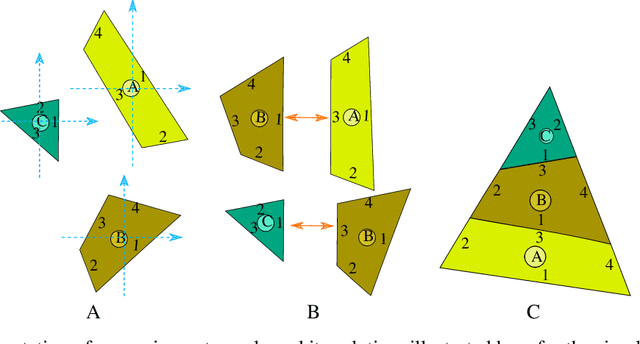
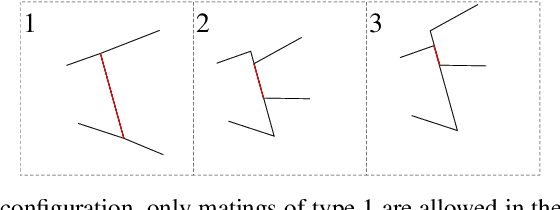
Jigsaw puzzle solving, the problem of constructing a coherent whole from a set of non-overlapping unordered fragments, is fundamental to numerous applications, and yet most of the literature has focused thus far on less realistic puzzles whose pieces are identical squares. Here we formalize a new type of jigsaw puzzle where the pieces are general convex polygons generated by cutting through a global polygonal shape with an arbitrary number of straight cuts, a generation model inspired by the celebrated Lazy caterer's sequence. We analyze the theoretical properties of such puzzles, including the inherent challenges in solving them once pieces are contaminated with geometrical noise. To cope with such difficulties and obtain tractable solutions, we abstract the problem as a multi-body spring-mass dynamical system endowed with hierarchical loop constraints and a layered reconstruction process. We define evaluation metrics and present experimental results to indicate that such puzzles are solvable completely automatically.
NTIRE 2020 Challenge on Spectral Reconstruction from an RGB Image
May 07, 2020
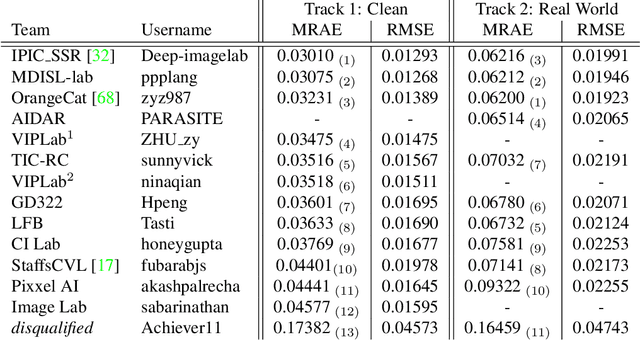

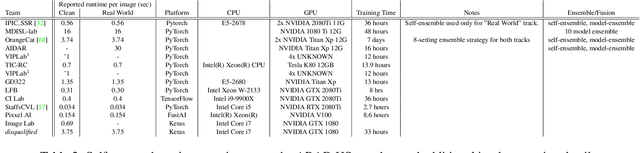
This paper reviews the second challenge on spectral reconstruction from RGB images, i.e., the recovery of whole-scene hyperspectral (HS) information from a 3-channel RGB image. As in the previous challenge, two tracks were provided: (i) a "Clean" track where HS images are estimated from noise-free RGBs, the RGB images are themselves calculated numerically using the ground-truth HS images and supplied spectral sensitivity functions (ii) a "Real World" track, simulating capture by an uncalibrated and unknown camera, where the HS images are recovered from noisy JPEG-compressed RGB images. A new, larger-than-ever, natural hyperspectral image data set is presented, containing a total of 510 HS images. The Clean and Real World tracks had 103 and 78 registered participants respectively, with 14 teams competing in the final testing phase. A description of the proposed methods, alongside their challenge scores and an extensive evaluation of top performing methods is also provided. They gauge the state-of-the-art in spectral reconstruction from an RGB image.