 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Visible: Disocclusion-Aware Editing via Proxy Dynamic Graphs
Dec 16, 2025



We address image-to-video generation with explicit user control over the final frame's disoccluded regions. Current image-to-video pipelines produce plausible motion but struggle to generate predictable, articulated motions while enforcing user-specified content in newly revealed areas. Our key idea is to separate motion specification from appearance synthesis: we introduce a lightweight, user-editable Proxy Dynamic Graph (PDG) that deterministically yet approximately drives part motion, while a frozen diffusion prior is used to synthesize plausible appearance that follows that motion. In our training-free pipeline, the user loosely annotates and reposes a PDG, from which we compute a dense motion flow to leverage diffusion as a motion-guided shader. We then let the user edit appearance in the disoccluded areas of the image, and exploit the visibility information encoded by the PDG to perform a latent-space composite that reconciles motion with user intent in these areas. This design yields controllable articulation and user control over disocclusions without fine-tuning. We demonstrate clear advantages against state-of-the-art alternatives towards images turned into short videos of articulated objects, furniture, vehicles, and deformables. Our method mixes generative control, in the form of loose pose and structure, with predictable controls, in the form of appearance specification in the final frame in the disoccluded regions, unlocking a new image-to-video workflow. Code will be released on acceptance. Project page: https://anranqi.github.io/beyond-visible.github.io/
FontCLIP: A Semantic Typography Visual-Language Model for Multilingual Font Applications
Mar 11, 2024Acquiring the desired font for various design tasks can be challenging and requires professional typographic knowledge. While previous font retrieval or generation works have alleviated some of these difficulties, they often lack support for multiple languages and semantic attributes beyond the training data domains. To solve this problem, we present FontCLIP: a model that connects the semantic understanding of a large vision-language model with typographical knowledge. We integrate typography-specific knowledge into the comprehensive vision-language knowledge of a pretrained CLIP model through a novel finetuning approach. We propose to use a compound descriptive prompt that encapsulates adaptively sampled attributes from a font attribute dataset focusing on Roman alphabet characters. FontCLIP's semantic typographic latent space demonstrates two unprecedented generalization abilities. First, FontCLIP generalizes to different languages including Chinese, Japanese, and Korean (CJK), capturing the typographical features of fonts across different languages, even though it was only finetuned using fonts of Roman characters. Second, FontCLIP can recognize the semantic attributes that are not presented in the training data. FontCLIP's dual-modality and generalization abilities enable multilingual and cross-lingual font retrieval and letter shape optimization, reducing the burden of obtaining desired fonts.
PersonalTailor: Personalizing 2D Pattern Design from 3D Garment Point Clouds
Mar 17, 2023



Garment pattern design aims to convert a 3D garment to the corresponding 2D panels and their sewing structure. Existing methods rely either on template fitting with heuristics and prior assumptions, or on model learning with complicated shape parameterization. Importantly, both approaches do not allow for personalization of the output garment, which today has increasing demands. To fill this demand, we introduce PersonalTailor: a personalized 2D pattern design method, where the user can input specific constraints or demands (in language or sketch) for personal 2D panel fabrication from 3D point clouds. PersonalTailor first learns a multi-modal panel embeddings based on unsupervised cross-modal association and attentive fusion. It then predicts a binary panel masks individually using a transformer encoder-decoder framework. Extensive experiments show that our PersonalTailor excels on both personalized and standard pattern fabrication tasks.
How Far Can I Go ? : A Self-Supervised Approach for Deterministic Video Depth Forecasting
Jul 08, 2022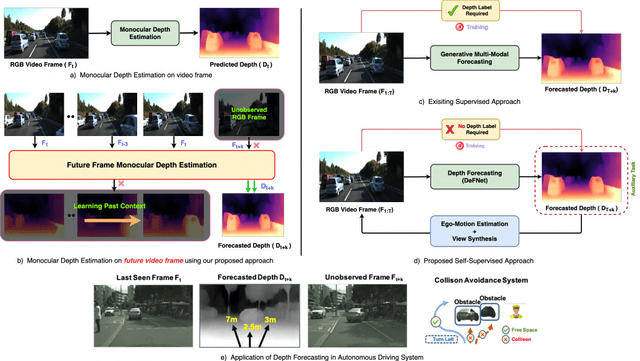
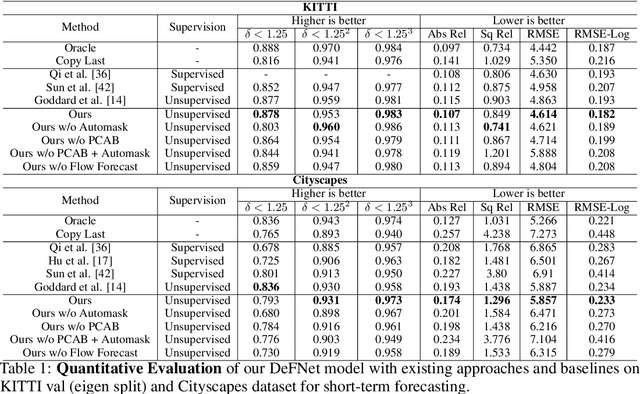
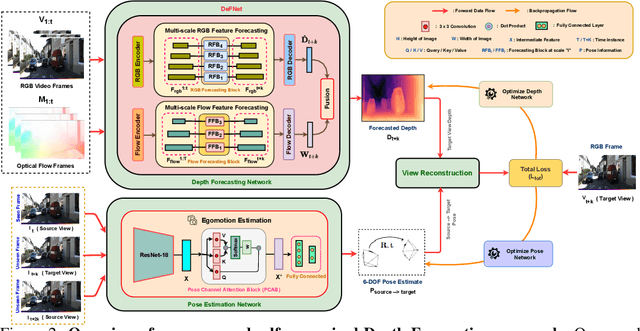
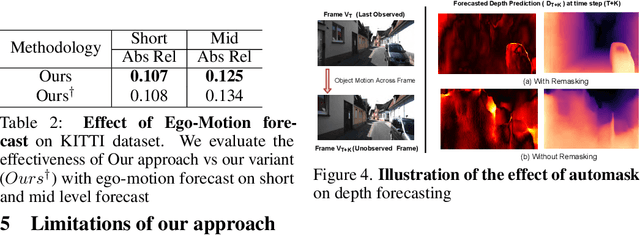
In this paper we present a novel self-supervised method to anticipate the depth estimate for a future, unobserved real-world urban scene. This work is the first to explore self-supervised learning for estimation of monocular depth of future unobserved frames of a video. Existing works rely on a large number of annotated samples to generate the probabilistic prediction of depth for unseen frames. However, this makes it unrealistic due to its requirement for large amount of annotated depth samples of video. In addition, the probabilistic nature of the case, where one past can have multiple future outcomes often leads to incorrect depth estimates. Unlike previous methods, we model the depth estimation of the unobserved frame as a view-synthesis problem, which treats the depth estimate of the unseen video frame as an auxiliary task while synthesizing back the views using learned pose. This approach is not only cost effective - we do not use any ground truth depth for training (hence practical) but also deterministic (a sequence of past frames map to an immediate future). To address this task we first develop a novel depth forecasting network DeFNet which estimates depth of unobserved future by forecasting latent features. Second, we develop a channel-attention based pose estimation network that estimates the pose of the unobserved frame. Using this learned pose, estimated depth map is reconstructed back into the image domain, thus forming a self-supervised solution. Our proposed approach shows significant improvements in Abs Rel metric compared to state-of-the-art alternatives on both short and mid-term forecasting setting, benchmarked on KITTI and Cityscapes. Code is available at https://github.com/sauradip/depthForecasting
One Sketch for All: One-Shot Personalized Sketch Segmentation
Dec 20, 2021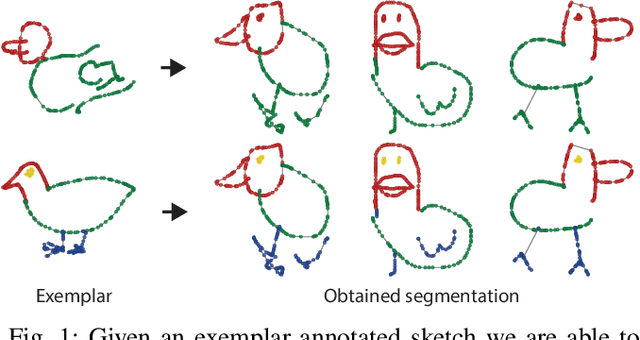
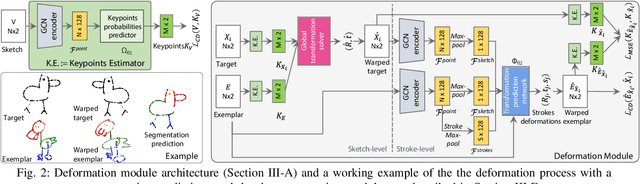
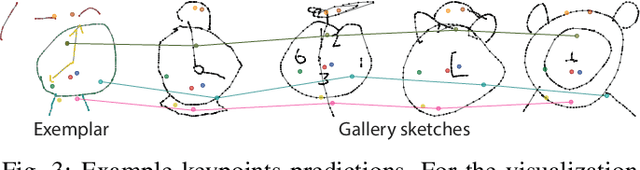

We present the first one-shot personalized sketch segmentation method. We aim to segment all sketches belonging to the same category provisioned with a single sketch with a given part annotation while (i) preserving the parts semantics embedded in the exemplar, and (ii) being robust to input style and abstraction. We refer to this scenario as personalized. With that, we importantly enable a much-desired personalization capability for downstream fine-grained sketch analysis tasks. To train a robust segmentation module, we deform the exemplar sketch to each of the available sketches of the same category. Our method generalizes to sketches not observed during training. Our central contribution is a sketch-specific hierarchical deformation network. Given a multi-level sketch-strokes encoding obtained via a graph convolutional network, our method estimates rigid-body transformation from the reference to the exemplar, on the upper level. Finer deformation from the exemplar to the globally warped reference sketch is further obtained through stroke-wise deformations, on the lower level. Both levels of deformation are guided by mean squared distances between the keypoints learned without supervision, ensuring that the stroke semantics are preserved. We evaluate our method against the state-of-the-art segmentation and perceptual grouping baselines re-purposed for the one-shot setting and against two few-shot 3D shape segmentation methods. We show that our method outperforms all the alternatives by more than 10% on average. Ablation studies further demonstrate that our method is robust to personalization: changes in input part semantics and style differences.