 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReSkill: Reconciling Skill Creation with Policy Optimization in Agentic RL
Jun 01, 2026Agentic reinforcement learning (RL) enables LLM agents to improve continuously from environment rewards, yet the resulting policies do not systematically accumulate reusable strategies that generalize across tasks. Modular skills can provide such reusable strategies, yet existing skill-augmented RL methods decouple skill creation from policy optimization, risking adopting skills that conflict with the evolving policy. Inspired by Anthropic's Skill Creator, we introduce ReSkill, an RL-in-the-loop skill creation framework that reconciles skill evolution with policy learning. ReSkill exploits the group-wise structure of GRPO to naturally embed three mechanisms with only marginal additional overhead: (1) an assertion-driven skill creator that diagnoses failures from past experience and proposes conditional, trigger-based skill revisions; (2) within-group rollout sampling that enables controlled comparison of skill versions, capturing which version best supports the policy's ongoing learning; and (3) Thompson Sampling with adaptive discounting to balance exploration and exploitation in skill version selection as the policy evolves. Across several domains, ReSkill consistently outperforms existing memory and skill-based RL methods, with the largest gains on unseen tasks. Analysis of the skill lifecycle shows skills being automatically created, tested, refined, and pruned as the policy improves, demonstrating reconciled skill-policy co-evolution.
SenTSR-Bench: Thinking with Injected Knowledge for Time-Series Reasoning
Feb 23, 2026Time-series diagnostic reasoning is essential for many applications, yet existing solutions face a persistent gap: general reasoning large language models (GRLMs) possess strong reasoning skills but lack the domain-specific knowledge to understand complex time-series patterns. Conversely, fine-tuned time-series LLMs (TSLMs) understand these patterns but lack the capacity to generalize reasoning for more complicated questions. To bridge this gap, we propose a hybrid knowledge-injection framework that injects TSLM-generated insights directly into GRLM's reasoning trace, thereby achieving strong time-series reasoning with in-domain knowledge. As collecting data for knowledge injection fine-tuning is costly, we further leverage a reinforcement learning-based approach with verifiable rewards (RLVR) to elicit knowledge-rich traces without human supervision, then transfer such an in-domain thinking trace into GRLM for efficient knowledge injection. We further release SenTSR-Bench, a multivariate time-series-based diagnostic reasoning benchmark collected from real-world industrial operations. Across SenTSR-Bench and other public datasets, our method consistently surpasses TSLMs by 9.1%-26.1% and GRLMs by 7.9%-22.4%, delivering robust, context-aware time-series diagnostic insights.
Harnessing Vision-Language Models for Time Series Anomaly Detection
Jun 07, 2025



Time-series anomaly detection (TSAD) has played a vital role in a variety of fields, including healthcare, finance, and industrial monitoring. Prior methods, which mainly focus on training domain-specific models on numerical data, lack the visual-temporal reasoning capacity that human experts have to identify contextual anomalies. To fill this gap, we explore a solution based on vision language models (VLMs). Recent studies have shown the ability of VLMs for visual reasoning tasks, yet their direct application to time series has fallen short on both accuracy and efficiency. To harness the power of VLMs for TSAD, we propose a two-stage solution, with (1) ViT4TS, a vision-screening stage built on a relatively lightweight pretrained vision encoder, which leverages 2-D time-series representations to accurately localize candidate anomalies; (2) VLM4TS, a VLM-based stage that integrates global temporal context and VLM reasoning capacity to refine the detection upon the candidates provided by ViT4TS. We show that without any time-series training, VLM4TS outperforms time-series pretrained and from-scratch baselines in most cases, yielding a 24.6 percent improvement in F1-max score over the best baseline. Moreover, VLM4TS also consistently outperforms existing language-model-based TSAD methods and is on average 36 times more efficient in token usage.
M$^2$AD: Multi-Sensor Multi-System Anomaly Detection through Global Scoring and Calibrated Thresholding
Apr 21, 2025



With the widespread availability of sensor data across industrial and operational systems, we frequently encounter heterogeneous time series from multiple systems. Anomaly detection is crucial for such systems to facilitate predictive maintenance. However, most existing anomaly detection methods are designed for either univariate or single-system multivariate data, making them insufficient for these complex scenarios. To address this, we introduce M$^2$AD, a framework for unsupervised anomaly detection in multivariate time series data from multiple systems. M$^2$AD employs deep models to capture expected behavior under normal conditions, using the residuals as indicators of potential anomalies. These residuals are then aggregated into a global anomaly score through a Gaussian Mixture Model and Gamma calibration. We theoretically demonstrate that this framework can effectively address heterogeneity and dependencies across sensors and systems. Empirically, M$^2$AD outperforms existing methods in extensive evaluations by 21% on average, and its effectiveness is demonstrated on a large-scale real-world case study on 130 assets in Amazon Fulfillment Centers. Our code and results are available at https://github.com/sarahmish/M2AD.
The Effect of Personalization in FedProx: A Fine-grained Analysis on Statistical Accuracy and Communication Efficiency
Oct 11, 2024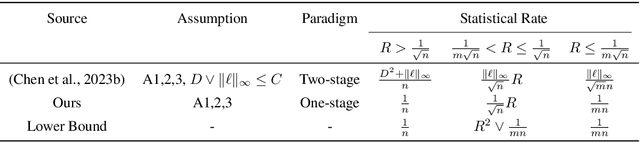
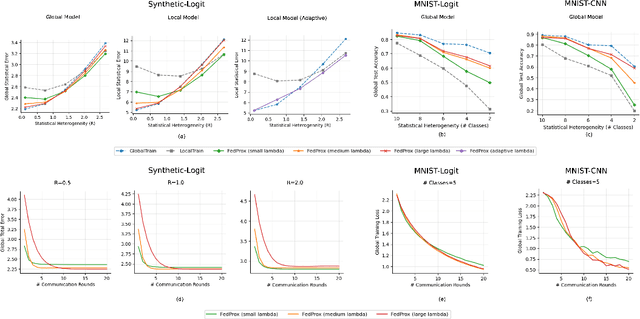

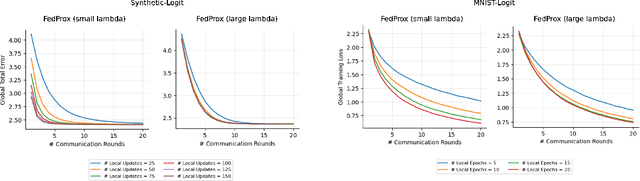
FedProx is a simple yet effective federated learning method that enables model personalization via regularization. Despite remarkable success in practice, a rigorous analysis of how such a regularization provably improves the statistical accuracy of each client's local model hasn't been fully established. Setting the regularization strength heuristically presents a risk, as an inappropriate choice may even degrade accuracy. This work fills in the gap by analyzing the effect of regularization on statistical accuracy, thereby providing a theoretical guideline for setting the regularization strength for achieving personalization. We prove that by adaptively choosing the regularization strength under different statistical heterogeneity, FedProx can consistently outperform pure local training and achieve a nearly minimax-optimal statistical rate. In addition, to shed light on resource allocation, we design an algorithm, provably showing that stronger personalization reduces communication complexity without increasing the computation cost overhead. Finally, our theory is validated on both synthetic and real-world datasets and its generalizability is verified in a non-convex setting.
TransFusion: Covariate-Shift Robust Transfer Learning for High-Dimensional Regression
Apr 01, 2024



The main challenge that sets transfer learning apart from traditional supervised learning is the distribution shift, reflected as the shift between the source and target models and that between the marginal covariate distributions. In this work, we tackle model shifts in the presence of covariate shifts in the high-dimensional regression setting. Specifically, we propose a two-step method with a novel fused-regularizer that effectively leverages samples from source tasks to improve the learning performance on a target task with limited samples. Nonasymptotic bound is provided for the estimation error of the target model, showing the robustness of the proposed method to covariate shifts. We further establish conditions under which the estimator is minimax-optimal. Additionally, we extend the method to a distributed setting, allowing for a pretraining-finetuning strategy, requiring just one round of communication while retaining the estimation rate of the centralized version. Numerical tests validate our theory, highlighting the method's robustness to covariate shifts.
AdaTrans: Feature-wise and Sample-wise Adaptive Transfer Learning for High-dimensional Regression
Mar 20, 2024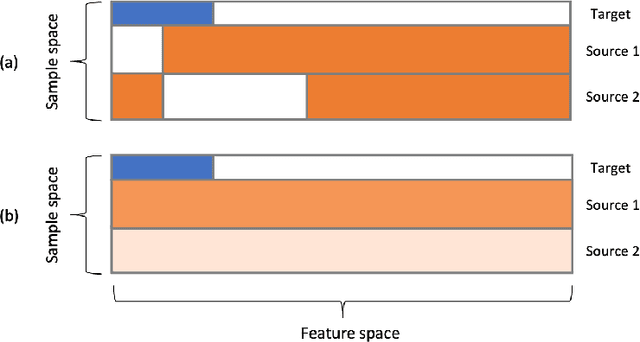
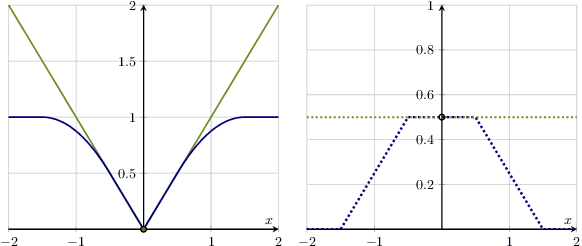
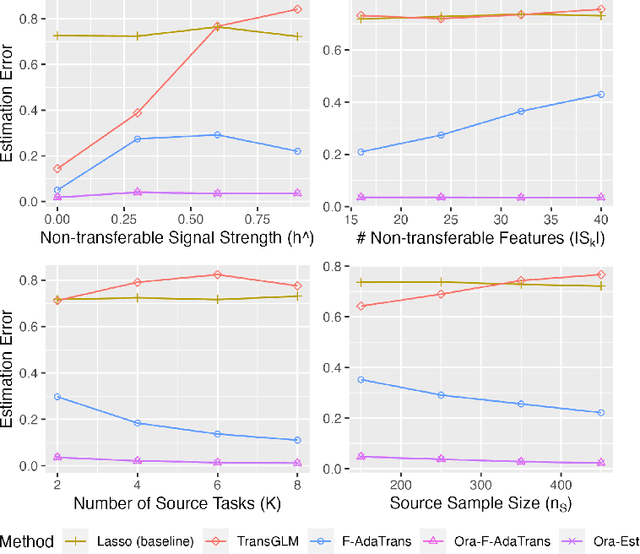
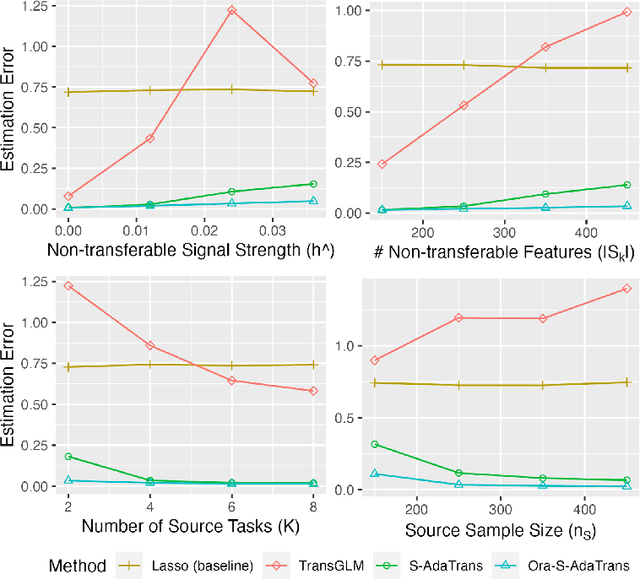
We consider the transfer learning problem in the high dimensional setting, where the feature dimension is larger than the sample size. To learn transferable information, which may vary across features or the source samples, we propose an adaptive transfer learning method that can detect and aggregate the feature-wise (F-AdaTrans) or sample-wise (S-AdaTrans) transferable structures. We achieve this by employing a novel fused-penalty, coupled with weights that can adapt according to the transferable structure. To choose the weight, we propose a theoretically informed, data-driven procedure, enabling F-AdaTrans to selectively fuse the transferable signals with the target while filtering out non-transferable signals, and S-AdaTrans to obtain the optimal combination of information transferred from each source sample. The non-asymptotic rates are established, which recover existing near-minimax optimal rates in special cases. The effectiveness of the proposed method is validated using both synthetic and real data.