 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAU: A SpatioTemporal-Aware Unit for Video Prediction and Beyond
Paper and Code
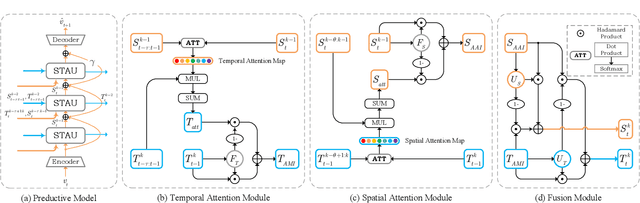


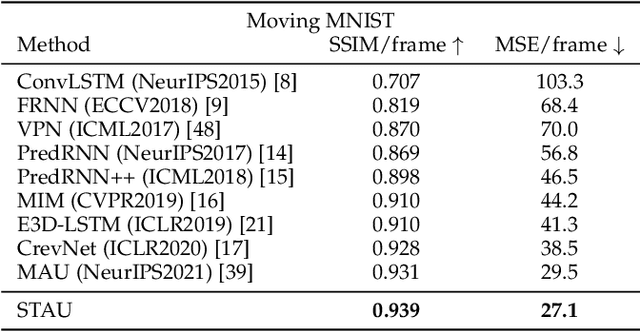
Video prediction aims to predict future frames by modeling the complex spatiotemporal dynamics in videos. However, most of the existing methods only model the temporal information and the spatial information for videos in an independent manner but haven't fully explored the correlations between both terms. In this paper, we propose a SpatioTemporal-Aware Unit (STAU) for video prediction and beyond by exploring the significant spatiotemporal correlations in videos. On the one hand, the motion-aware attention weights are learned from the spatial states to help aggregate the temporal states in the temporal domain. On the other hand, the appearance-aware attention weights are learned from the temporal states to help aggregate the spatial states in the spatial domain. In this way, the temporal information and the spatial information can be greatly aware of each other in both domains, during which, the spatiotemporal receptive field can also be greatly broadened for more reliable spatiotemporal modeling. Experiments are not only conducted on traditional video prediction tasks but also other tasks beyond video prediction, including the early action recognition and object detection tasks. Experimental results show that our STAU can outperform other methods on all tasks in terms of performance and computation efficiency.