 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTIP: A SpatioTemporal Information-Preserving and Perception-Augmented Model for High-Resolution Video Prediction
Paper and Code
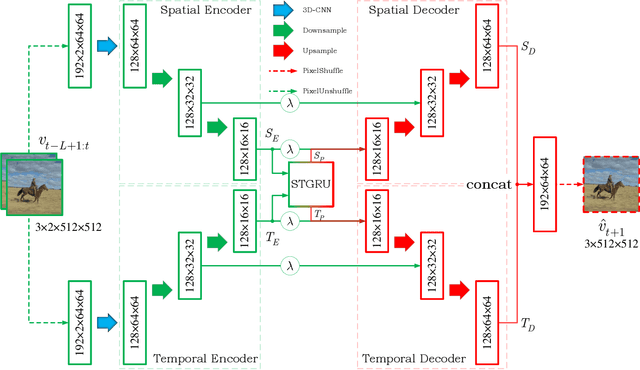
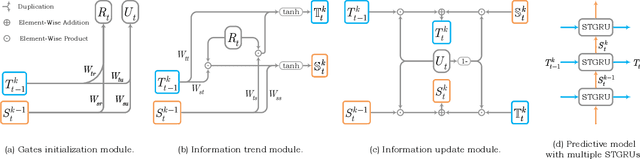


Although significant achievements have been achieved by recurrent neural network (RNN) based video prediction methods, their performance in datasets with high resolutions is still far from satisfactory because of the information loss problem and the perception-insensitive mean square error (MSE) based loss functions. In this paper, we propose a Spatiotemporal Information-Preserving and Perception-Augmented Model (STIP) to solve the above two problems. To solve the information loss problem, the proposed model aims to preserve the spatiotemporal information for videos during the feature extraction and the state transitions, respectively. Firstly, a Multi-Grained Spatiotemporal Auto-Encoder (MGST-AE) is designed based on the X-Net structure. The proposed MGST-AE can help the decoders recall multi-grained information from the encoders in both the temporal and spatial domains. In this way, more spatiotemporal information can be preserved during the feature extraction for high-resolution videos. Secondly, a Spatiotemporal Gated Recurrent Unit (STGRU) is designed based on the standard Gated Recurrent Unit (GRU) structure, which can efficiently preserve spatiotemporal information during the state transitions. The proposed STGRU can achieve more satisfactory performance with a much lower computation load compared with the popular Long Short-Term (LSTM) based predictive memories. Furthermore, to improve the traditional MSE loss functions, a Learned Perceptual Loss (LP-loss) is further designed based on the Generative Adversarial Networks (GANs), which can help obtain a satisfactory trade-off between the objective quality and the perceptual quality. Experimental results show that the proposed STIP can predict videos with more satisfactory visual quality compared with a variety of state-of-the-art methods. Source code has been available at \url{https://github.com/ZhengChang467/STIPHR}.