 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaDSE: A Few-shot Meta-learning Framework for Cross-workload CPU Design Space Exploration
Apr 18, 2025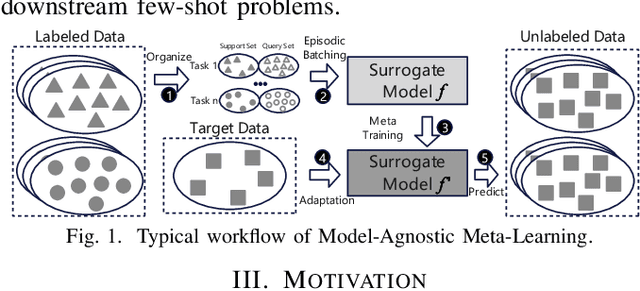
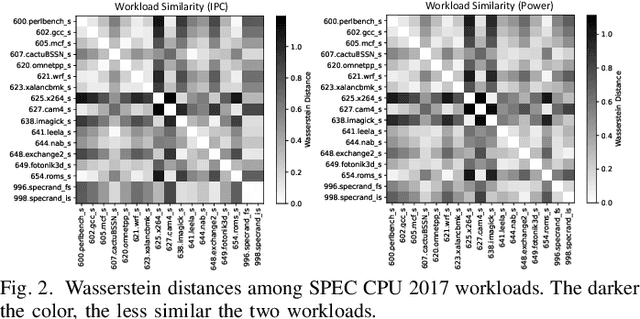
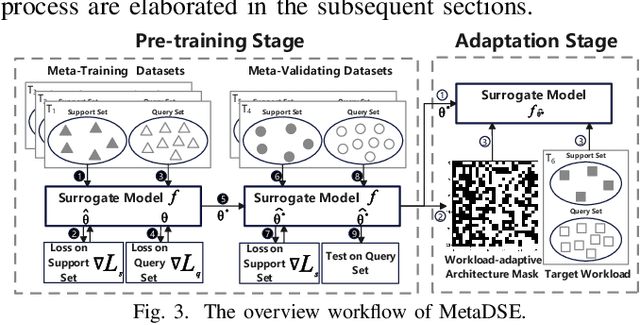
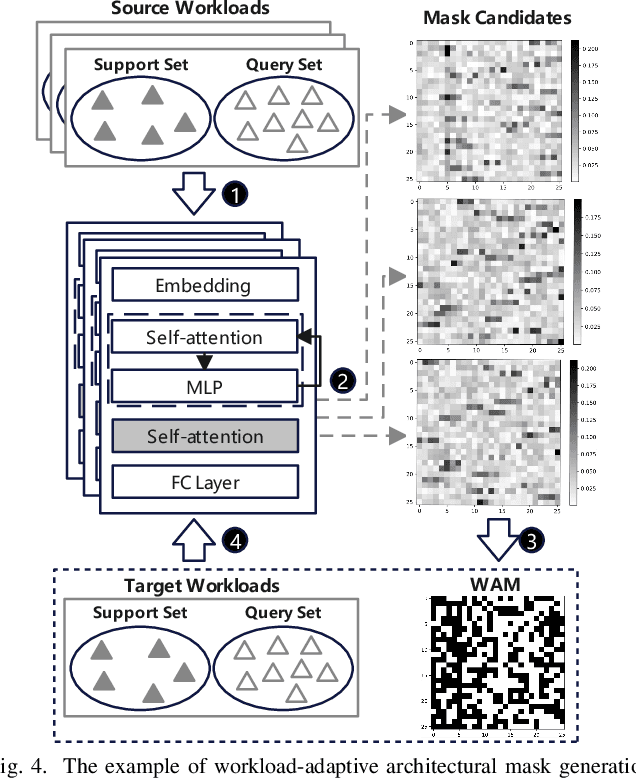
Cross-workload design space exploration (DSE) is crucial in CPU architecture design. Existing DSE methods typically employ the transfer learning technique to leverage knowledge from source workloads, aiming to minimize the requirement of target workload simulation. However, these methods struggle with overfitting, data ambiguity, and workload dissimilarity. To address these challenges, we reframe the cross-workload CPU DSE task as a few-shot meta-learning problem and further introduce MetaDSE. By leveraging model agnostic meta-learning, MetaDSE swiftly adapts to new target workloads, greatly enhancing the efficiency of cross-workload CPU DSE. Additionally, MetaDSE introduces a novel knowledge transfer method called the workload-adaptive architectural mask algorithm, which uncovers the inherent properties of the architecture. Experiments on SPEC CPU 2017 demonstrate that MetaDSE significantly reduces prediction error by 44.3\% compared to the state-of-the-art. MetaDSE is open-sourced and available at this \href{https://anonymous.4open.science/r/Meta_DSE-02F8}{anonymous GitHub.}
Multi-objective Optimization in CPU Design Space Exploration: Attention is All You Need
Oct 24, 2024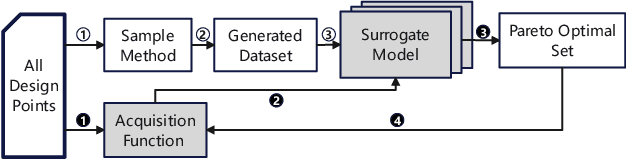
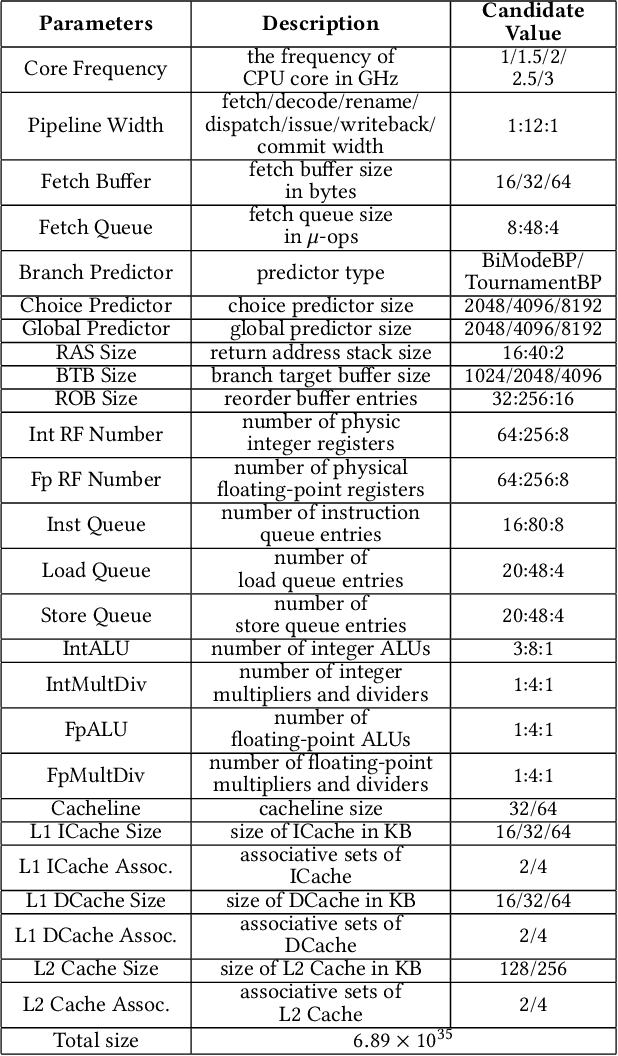
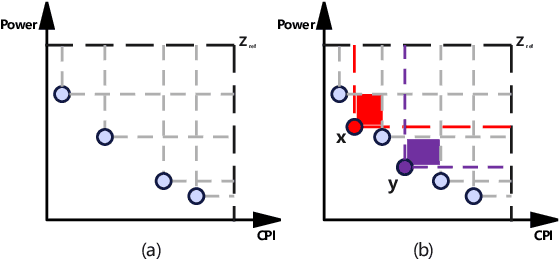

Design space exploration (DSE) enables architects to systematically evaluate various design options, guiding decisions on the most suitable configurations to meet specific objectives such as optimizing performance, power, and area. However, the growing complexity of modern CPUs has dramatically increased the number of micro-architectural parameters and expanded the overall design space, making DSE more challenging and time-consuming. Existing DSE frameworks struggle in large-scale design spaces due to inaccurate models and limited insights into parameter impact, hindering efficient identification of optimal micro-architectures within tight timeframes. In this work, we introduce AttentionDSE. Its key idea is to use the attention mechanism to establish a direct mapping of micro-architectural parameters to their contributions to predicted performance. This approach enhances both the prediction accuracy and interpretability of the performance model. Furthermore, the weights are dynamically adjusted, enabling the model to respond to design changes and effectively pinpoint the key micro-architectural parameters/components responsible for performance bottlenecks. Thus, AttentionDSE accurately, purposefully, and rapidly discovers optimal designs. Experiments on SPEC 2017 demonstrate that AttentionDSE significantly reduces exploration time by over 80\% and achieves 3.9\% improvement in Pareto Hypervolume compared to state-of-the-art DSE frameworks while maintaining superior prediction accuracy and efficiency with an increasing number of parameters.
SiHGNN: Leveraging Properties of Semantic Graphs for Efficient HGNN Acceleration
Aug 27, 2024Heterogeneous Graph Neural Networks (HGNNs) have expanded graph representation learning to heterogeneous graph fields. Recent studies have demonstrated their superior performance across various applications, including medical analysis and recommendation systems, often surpassing existing methods. However, GPUs often experience inefficiencies when executing HGNNs due to their unique and complex execution patterns. Compared to traditional Graph Neural Networks, these patterns further exacerbate irregularities in memory access. To tackle these challenges, recent studies have focused on developing domain-specific accelerators for HGNNs. Nonetheless, most of these efforts have concentrated on optimizing the datapath or scheduling data accesses, while largely overlooking the potential benefits that could be gained from leveraging the inherent properties of the semantic graph, such as its topology, layout, and generation. In this work, we focus on leveraging the properties of semantic graphs to enhance HGNN performance. First, we analyze the Semantic Graph Build (SGB) stage and identify significant opportunities for data reuse during semantic graph generation. Next, we uncover the phenomenon of buffer thrashing during the Graph Feature Processing (GFP) stage, revealing potential optimization opportunities in semantic graph layout. Furthermore, we propose a lightweight hardware accelerator frontend for HGNNs, called SiHGNN. This accelerator frontend incorporates a tree-based Semantic Graph Builder for efficient semantic graph generation and features a novel Graph Restructurer for optimizing semantic graph layouts. Experimental results show that SiHGNN enables the state-of-the-art HGNN accelerator to achieve an average performance improvement of 2.95$\times$.
Rethinking Efficiency and Redundancy in Training Large-scale Graphs
Sep 02, 2022
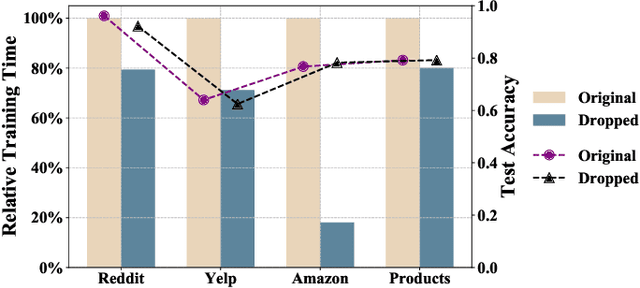
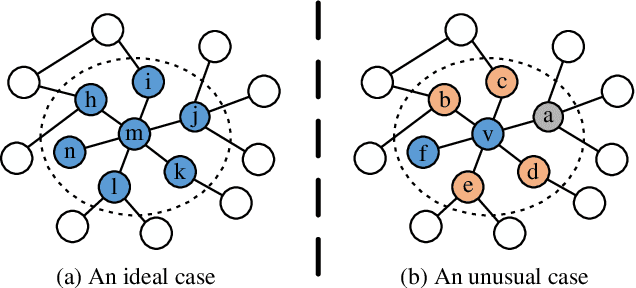
Large-scale graphs are ubiquitous in real-world scenarios and can be trained by Graph Neural Networks (GNNs) to generate representation for downstream tasks. Given the abundant information and complex topology of a large-scale graph, we argue that redundancy exists in such graphs and will degrade the training efficiency. Unfortunately, the model scalability severely restricts the efficiency of training large-scale graphs via vanilla GNNs. Despite recent advances in sampling-based training methods, sampling-based GNNs generally overlook the redundancy issue. It still takes intolerable time to train these models on large-scale graphs. Thereby, we propose to drop redundancy and improve efficiency of training large-scale graphs with GNNs, by rethinking the inherent characteristics in a graph. In this paper, we pioneer to propose a once-for-all method, termed DropReef, to drop the redundancy in large-scale graphs. Specifically, we first conduct preliminary experiments to explore potential redundancy in large-scale graphs. Next, we present a metric to quantify the neighbor heterophily of all nodes in a graph. Based on both experimental and theoretical analysis, we reveal the redundancy in a large-scale graph, i.e., nodes with high neighbor heterophily and a great number of neighbors. Then, we propose DropReef to detect and drop the redundancy in large-scale graphs once and for all, helping reduce the training time while ensuring no sacrifice in the model accuracy. To demonstrate the effectiveness of DropReef, we apply it to recent state-of-the-art sampling-based GNNs for training large-scale graphs, owing to the high precision of such models. With DropReef leveraged, the training efficiency of models can be greatly promoted. DropReef is highly compatible and is offline performed, benefiting the state-of-the-art sampling-based GNNs in the present and future to a significant extent.