 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Efficiency and Redundancy in Training Large-scale Graphs
Paper and Code
Sep 02, 2022
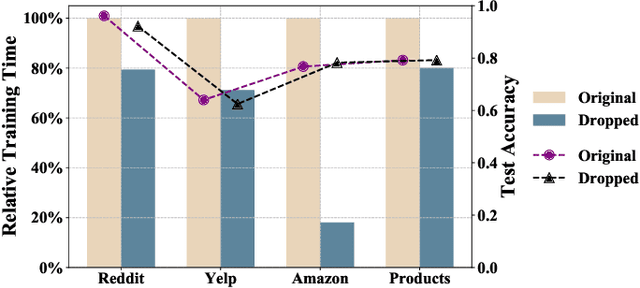
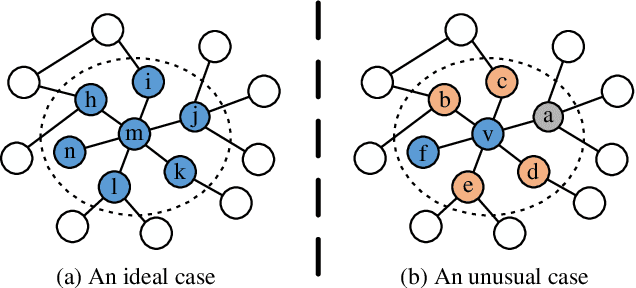
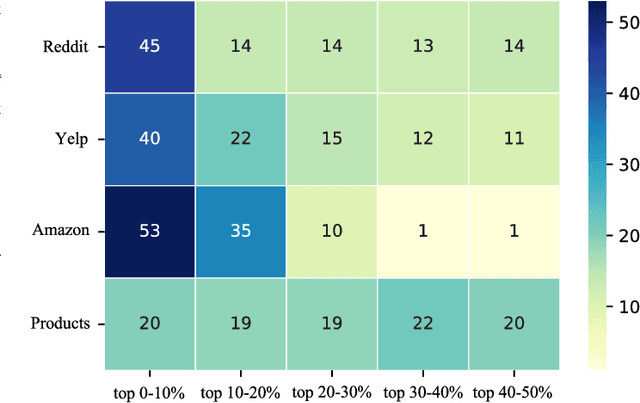
Large-scale graphs are ubiquitous in real-world scenarios and can be trained by Graph Neural Networks (GNNs) to generate representation for downstream tasks. Given the abundant information and complex topology of a large-scale graph, we argue that redundancy exists in such graphs and will degrade the training efficiency. Unfortunately, the model scalability severely restricts the efficiency of training large-scale graphs via vanilla GNNs. Despite recent advances in sampling-based training methods, sampling-based GNNs generally overlook the redundancy issue. It still takes intolerable time to train these models on large-scale graphs. Thereby, we propose to drop redundancy and improve efficiency of training large-scale graphs with GNNs, by rethinking the inherent characteristics in a graph. In this paper, we pioneer to propose a once-for-all method, termed DropReef, to drop the redundancy in large-scale graphs. Specifically, we first conduct preliminary experiments to explore potential redundancy in large-scale graphs. Next, we present a metric to quantify the neighbor heterophily of all nodes in a graph. Based on both experimental and theoretical analysis, we reveal the redundancy in a large-scale graph, i.e., nodes with high neighbor heterophily and a great number of neighbors. Then, we propose DropReef to detect and drop the redundancy in large-scale graphs once and for all, helping reduce the training time while ensuring no sacrifice in the model accuracy. To demonstrate the effectiveness of DropReef, we apply it to recent state-of-the-art sampling-based GNNs for training large-scale graphs, owing to the high precision of such models. With DropReef leveraged, the training efficiency of models can be greatly promoted. DropReef is highly compatible and is offline performed, benefiting the state-of-the-art sampling-based GNNs in the present and future to a significant extent.