 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaDSE: A Few-shot Meta-learning Framework for Cross-workload CPU Design Space Exploration
Apr 18, 2025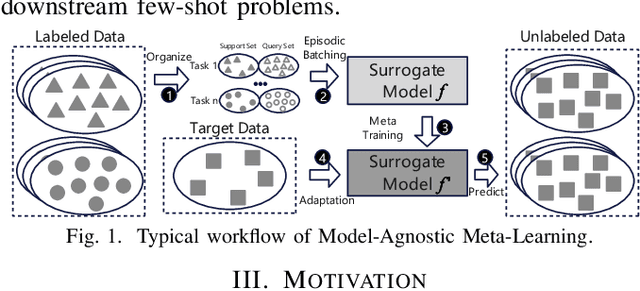
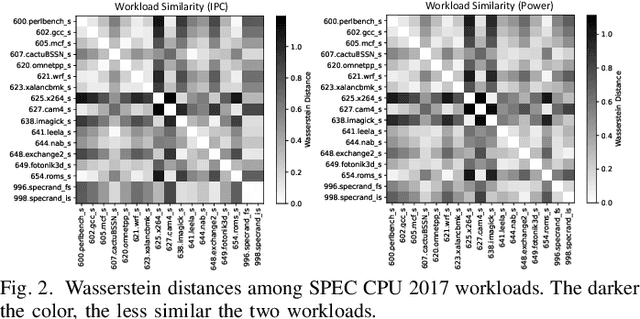
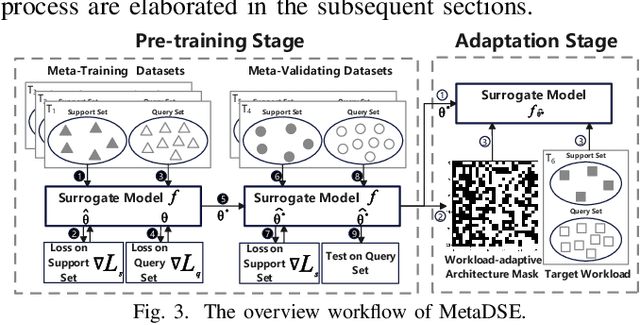
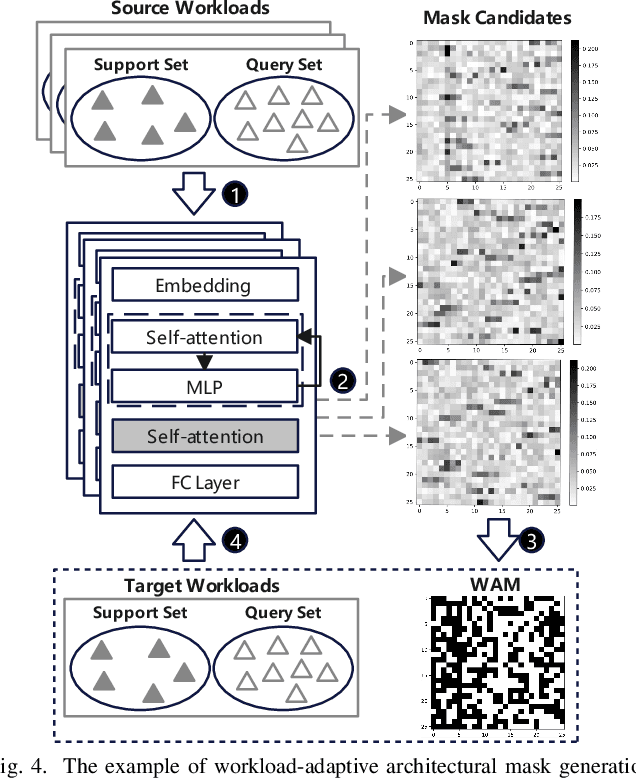
Cross-workload design space exploration (DSE) is crucial in CPU architecture design. Existing DSE methods typically employ the transfer learning technique to leverage knowledge from source workloads, aiming to minimize the requirement of target workload simulation. However, these methods struggle with overfitting, data ambiguity, and workload dissimilarity. To address these challenges, we reframe the cross-workload CPU DSE task as a few-shot meta-learning problem and further introduce MetaDSE. By leveraging model agnostic meta-learning, MetaDSE swiftly adapts to new target workloads, greatly enhancing the efficiency of cross-workload CPU DSE. Additionally, MetaDSE introduces a novel knowledge transfer method called the workload-adaptive architectural mask algorithm, which uncovers the inherent properties of the architecture. Experiments on SPEC CPU 2017 demonstrate that MetaDSE significantly reduces prediction error by 44.3\% compared to the state-of-the-art. MetaDSE is open-sourced and available at this \href{https://anonymous.4open.science/r/Meta_DSE-02F8}{anonymous GitHub.}
Multi-objective Optimization in CPU Design Space Exploration: Attention is All You Need
Oct 24, 2024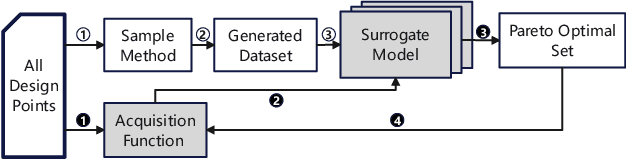
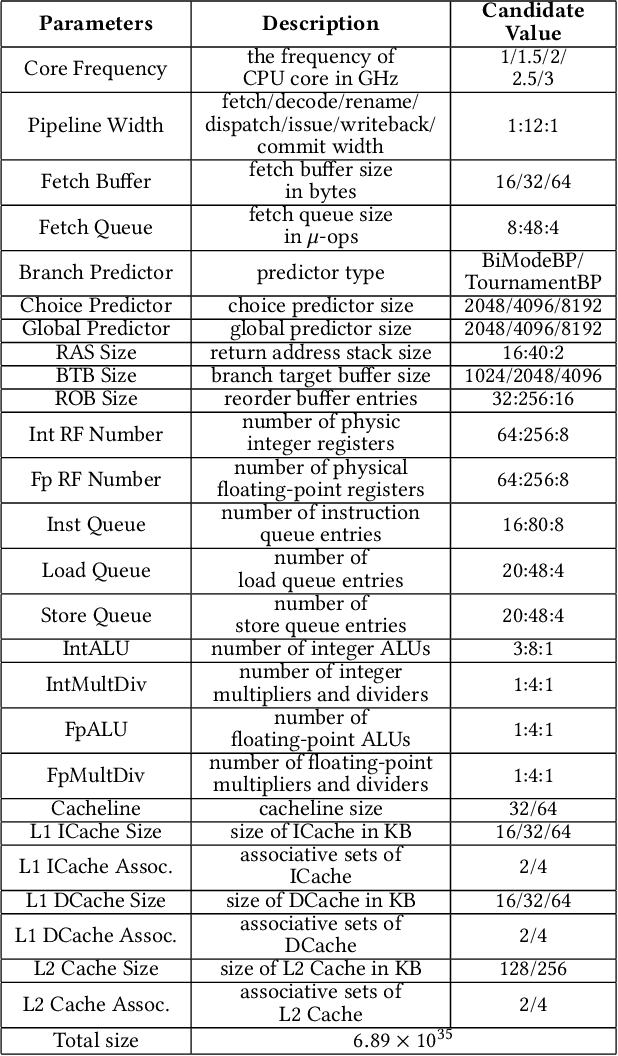
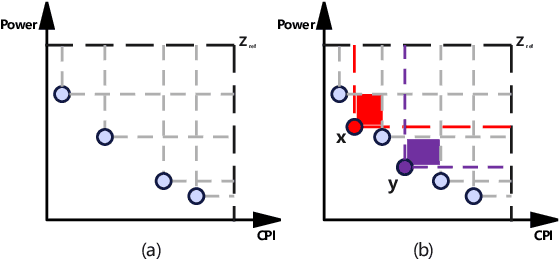

Design space exploration (DSE) enables architects to systematically evaluate various design options, guiding decisions on the most suitable configurations to meet specific objectives such as optimizing performance, power, and area. However, the growing complexity of modern CPUs has dramatically increased the number of micro-architectural parameters and expanded the overall design space, making DSE more challenging and time-consuming. Existing DSE frameworks struggle in large-scale design spaces due to inaccurate models and limited insights into parameter impact, hindering efficient identification of optimal micro-architectures within tight timeframes. In this work, we introduce AttentionDSE. Its key idea is to use the attention mechanism to establish a direct mapping of micro-architectural parameters to their contributions to predicted performance. This approach enhances both the prediction accuracy and interpretability of the performance model. Furthermore, the weights are dynamically adjusted, enabling the model to respond to design changes and effectively pinpoint the key micro-architectural parameters/components responsible for performance bottlenecks. Thus, AttentionDSE accurately, purposefully, and rapidly discovers optimal designs. Experiments on SPEC 2017 demonstrate that AttentionDSE significantly reduces exploration time by over 80\% and achieves 3.9\% improvement in Pareto Hypervolume compared to state-of-the-art DSE frameworks while maintaining superior prediction accuracy and efficiency with an increasing number of parameters.