 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKVT: k-NN Attention for Boosting Vision Transformers
Paper and Code
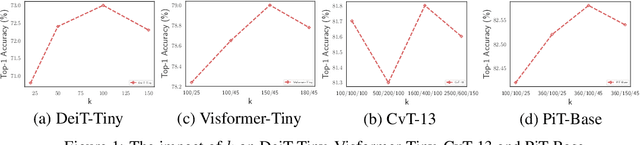
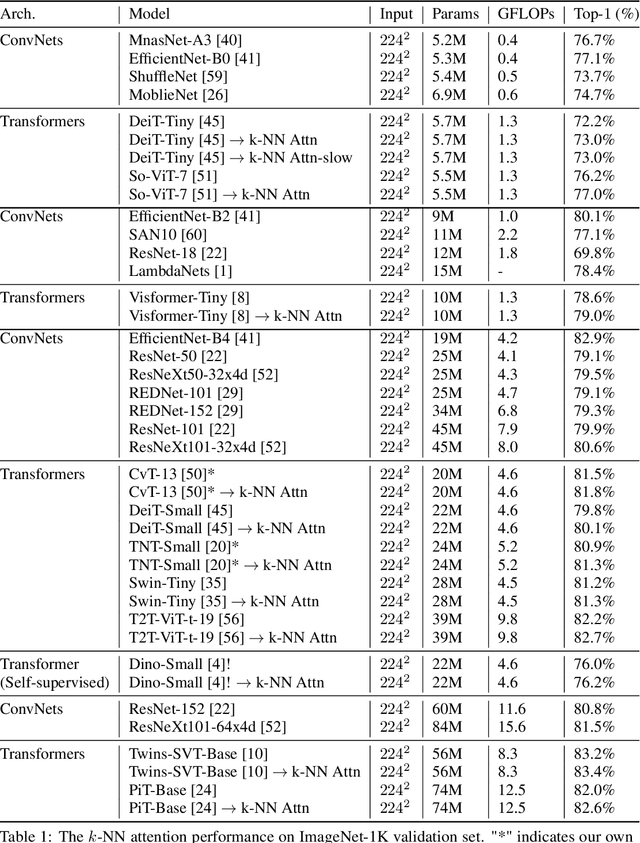
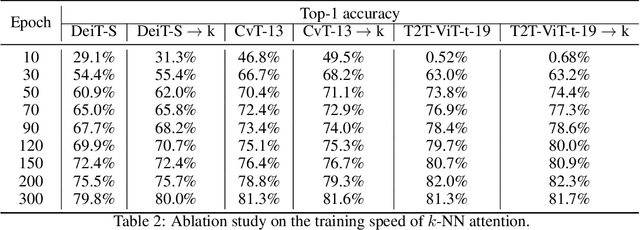
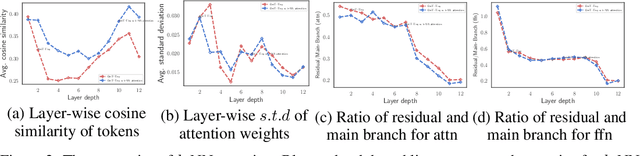
Convolutional Neural Networks (CNNs) have dominated computer vision for years, due to its ability in capturing locality and translation invariance. Recently, many vision transformer architectures have been proposed and they show promising performance. A key component in vision transformers is the fully-connected self-attention which is more powerful than CNNs in modelling long range dependencies. However, since the current dense self-attention uses all image patches (tokens) to compute attention matrix, it may neglect locality of images patches and involve noisy tokens (e.g., clutter background and occlusion), leading to a slow training process and potentially degradation of performance. To address these problems, we propose a sparse attention scheme, dubbed k-NN attention, for boosting vision transformers. Specifically, instead of involving all the tokens for attention matrix calculation, we only select the top-k similar tokens from the keys for each query to compute the attention map. The proposed k-NN attention naturally inherits the local bias of CNNs without introducing convolutional operations, as nearby tokens tend to be more similar than others. In addition, the k-NN attention allows for the exploration of long range correlation and at the same time filter out irrelevant tokens by choosing the most similar tokens from the entire image. Despite its simplicity, we verify, both theoretically and empirically, that $k$-NN attention is powerful in distilling noise from input tokens and in speeding up training. Extensive experiments are conducted by using ten different vision transformer architectures to verify that the proposed k-NN attention can work with any existing transformer architectures to improve its prediction performance.