 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Method of Query Graph Reranking for Knowledge Base Question Answering
Apr 27, 2022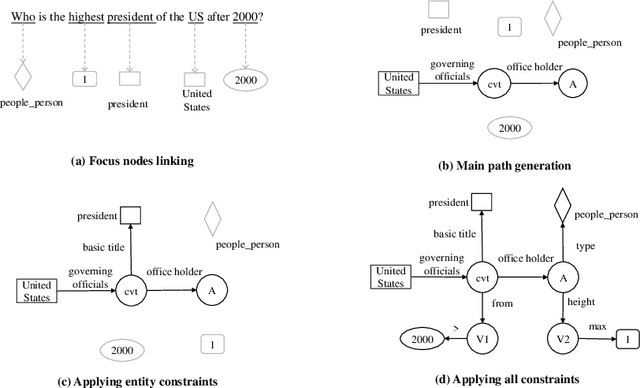

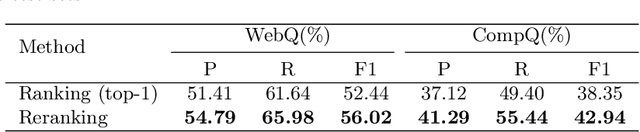
This paper presents a novel reranking method to better choose the optimal query graph, a sub-graph of knowledge graph, to retrieve the answer for an input question in Knowledge Base Question Answering (KBQA). Existing methods suffer from a severe problem that there is a significant gap between top-1 performance and the oracle score of top-n results. To address this problem, our method divides the choosing procedure into two steps: query graph ranking and query graph reranking. In the first step, we provide top-n query graphs for each question. Then we propose to rerank the top-n query graphs by combining with the information of answer type. Experimental results on two widely used datasets show that our proposed method achieves the best results on the WebQuestions dataset and the second best on the ComplexQuestions dataset.
Better Query Graph Selection for Knowledge Base Question Answering
Apr 27, 2022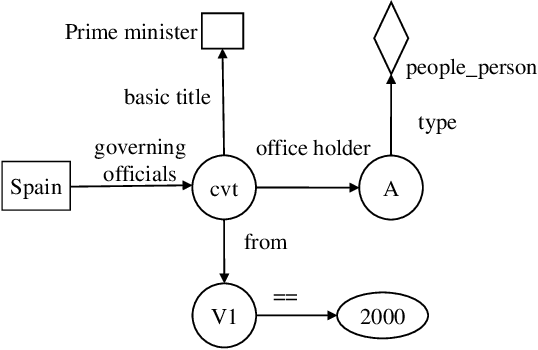


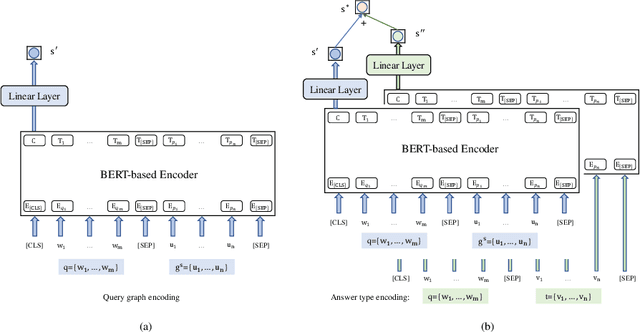
This paper presents a novel approach based on semantic parsing to improve the performance of Knowledge Base Question Answering (KBQA). Specifically, we focus on how to select an optimal query graph from a candidate set so as to retrieve the answer from knowledge base (KB). In our approach, we first propose to linearize the query graph into a sequence, which is used to form a sequence pair with the question. It allows us to use mature sequence modeling, such as BERT, to encode the sequence pair. Then we use a ranking method to sort candidate query graphs. In contrast to the previous studies, our approach can efficiently model semantic interactions between the graph and the question as well as rank the candidate graphs from a global view. The experimental results show that our system achieves the top performance on ComplexQuestions and the second best performance on WebQuestions.
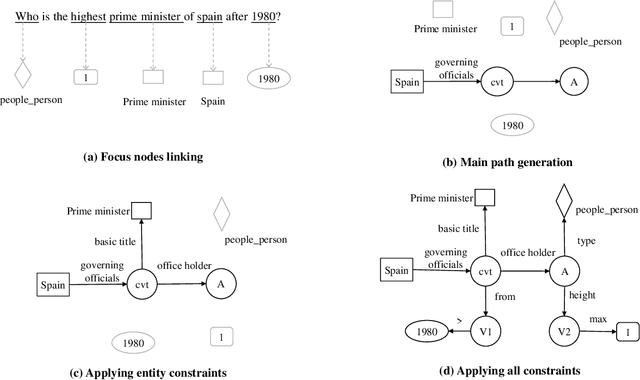
Exploiting Rich Syntax for Better Knowledge Base Question Answering
Jul 16, 2021
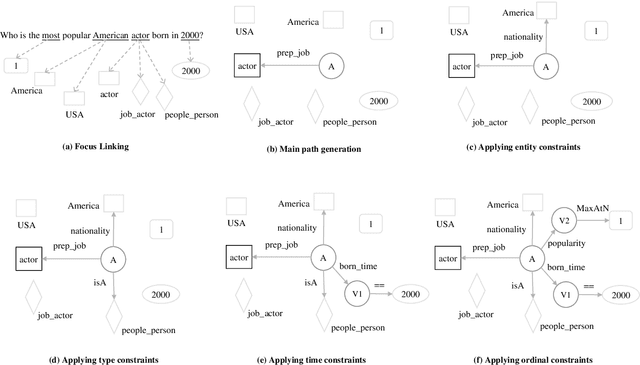
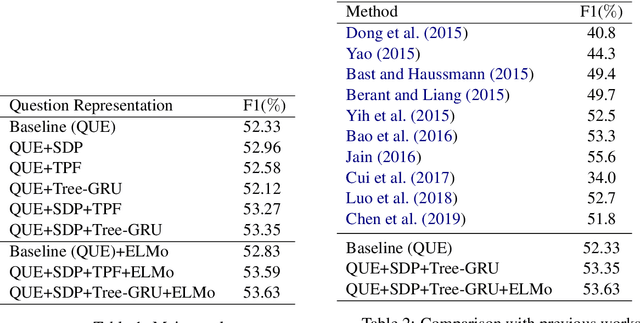

Recent studies on Knowledge Base Question Answering (KBQA) have shown great progress on this task via better question understanding. Previous works for encoding questions mainly focus on the word sequences, but seldom consider the information from syntactic trees.In this paper, we propose an approach to learn syntax-based representations for KBQA. First, we encode path-based syntax by considering the shortest dependency paths between keywords. Then, we propose two encoding strategies to mode the information of whole syntactic trees to obtain tree-based syntax. Finally, we combine both path-based and tree-based syntax representations for KBQA. We conduct extensive experiments on a widely used benchmark dataset and the experimental results show that our syntax-aware systems can make full use of syntax information in different settings and achieve state-of-the-art performance of KBQA.