 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Transfer-based Universal Attacks in Pure Black-box Setting
Apr 11, 2025Despite their impressive performance, deep visual models are susceptible to transferable black-box adversarial attacks. Principally, these attacks craft perturbations in a target model-agnostic manner. However, surprisingly, we find that existing methods in this domain inadvertently take help from various priors that violate the black-box assumption such as the availability of the dataset used to train the target model, and the knowledge of the number of classes in the target model. Consequently, the literature fails to articulate the true potency of transferable black-box attacks. We provide an empirical study of these biases and propose a framework that aids in a prior-free transparent study of this paradigm. Using our framework, we analyze the role of prior knowledge of the target model data and number of classes in attack performance. We also provide several interesting insights based on our analysis, and demonstrate that priors cause overestimation in transferability scores. Finally, we extend our framework to query-based attacks. This extension inspires a novel image-blending technique to prepare data for effective surrogate model training.
Rethinking interpretation: Input-agnostic saliency mapping of deep visual classifiers
Mar 31, 2023Saliency methods provide post-hoc model interpretation by attributing input features to the model outputs. Current methods mainly achieve this using a single input sample, thereby failing to answer input-independent inquiries about the model. We also show that input-specific saliency mapping is intrinsically susceptible to misleading feature attribution. Current attempts to use 'general' input features for model interpretation assume access to a dataset containing those features, which biases the interpretation. Addressing the gap, we introduce a new perspective of input-agnostic saliency mapping that computationally estimates the high-level features attributed by the model to its outputs. These features are geometrically correlated, and are computed by accumulating model's gradient information with respect to an unrestricted data distribution. To compute these features, we nudge independent data points over the model loss surface towards the local minima associated by a human-understandable concept, e.g., class label for classifiers. With a systematic projection, scaling and refinement process, this information is transformed into an interpretable visualization without compromising its model-fidelity. The visualization serves as a stand-alone qualitative interpretation. With an extensive evaluation, we not only demonstrate successful visualizations for a variety of concepts for large-scale models, but also showcase an interesting utility of this new form of saliency mapping by identifying backdoor signatures in compromised classifiers.
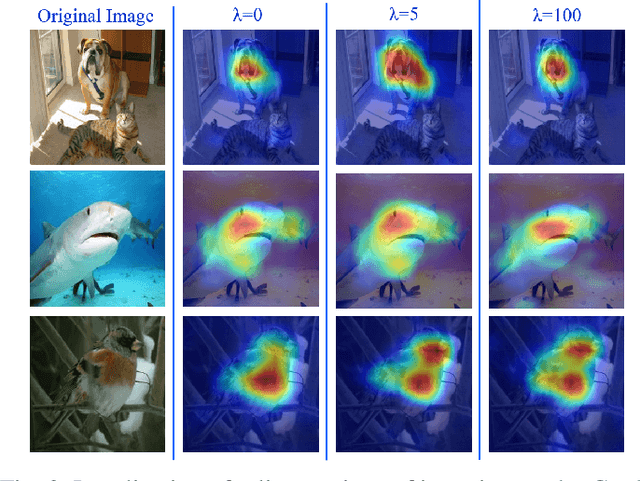
CAMERAS: Enhanced Resolution And Sanity preserving Class Activation Mapping for image saliency
Jun 20, 2021
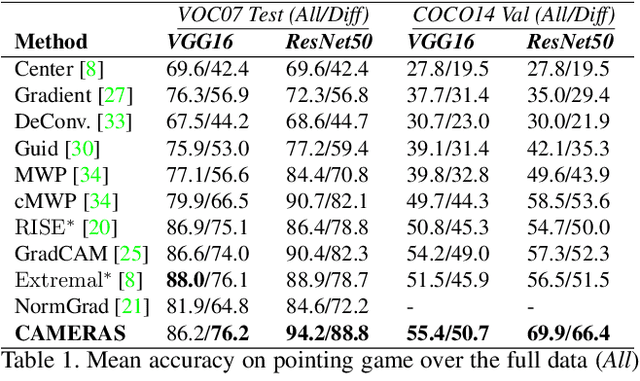


Backpropagation image saliency aims at explaining model predictions by estimating model-centric importance of individual pixels in the input. However, class-insensitivity of the earlier layers in a network only allows saliency computation with low resolution activation maps of the deeper layers, resulting in compromised image saliency. Remedifying this can lead to sanity failures. We propose CAMERAS, a technique to compute high-fidelity backpropagation saliency maps without requiring any external priors and preserving the map sanity. Our method systematically performs multi-scale accumulation and fusion of the activation maps and backpropagated gradients to compute precise saliency maps. From accurate image saliency to articulation of relative importance of input features for different models, and precise discrimination between model perception of visually similar objects, our high-resolution mapping offers multiple novel insights into the black-box deep visual models, which are presented in the paper. We also demonstrate the utility of our saliency maps in adversarial setup by drastically reducing the norm of attack signals by focusing them on the precise regions identified by our maps. Our method also inspires new evaluation metrics and a sanity check for this developing research direction. Code is available here https://github.com/VisMIL/CAMERAS
Orthogonal Deep Models As Defense Against Black-Box Attacks
Jun 26, 2020

Deep learning has demonstrated state-of-the-art performance for a variety of challenging computer vision tasks. On one hand, this has enabled deep visual models to pave the way for a plethora of critical applications like disease prognostics and smart surveillance. On the other, deep learning has also been found vulnerable to adversarial attacks, which calls for new techniques to defend deep models against these attacks. Among the attack algorithms, the black-box schemes are of serious practical concern since they only need publicly available knowledge of the targeted model. We carefully analyze the inherent weakness of deep models in black-box settings where the attacker may develop the attack using a model similar to the targeted model. Based on our analysis, we introduce a novel gradient regularization scheme that encourages the internal representation of a deep model to be orthogonal to another, even if the architectures of the two models are similar. Our unique constraint allows a model to concomitantly endeavour for higher accuracy while maintaining near orthogonal alignment of gradients with respect to a reference model. Detailed empirical study verifies that controlled misalignment of gradients under our orthogonality objective significantly boosts a model's robustness against transferable black-box adversarial attacks. In comparison to regular models, the orthogonal models are significantly more robust to a range of $l_p$ norm bounded perturbations. We verify the effectiveness of our technique on a variety of large-scale models.
Direct Image to Point Cloud Descriptors Matching for 6-DOF Camera Localization in Dense 3D Point Cloud
Jun 14, 2019
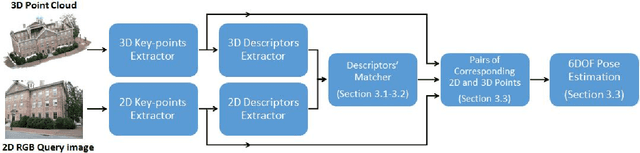

We propose a novel concept to directly match feature descriptors extracted from RGB images, with feature descriptors extracted from 3D point clouds. We use this concept to localize the position and orientation (pose) of the camera of a query image in dense point clouds. We generate a dataset of matching 2D and 3D descriptors, and use it to train a proposed Descriptor-Matcher algorithm. To localize a query image in a point cloud, we extract 2D keypoints and descriptors from the query image. Then the Descriptor-Matcher is used to find the corresponding pairs 2D and 3D keypoints by matching the 2D descriptors with the pre-extracted 3D descriptors of the point cloud. This information is used in a robust pose estimation algorithm to localize the query image in the 3D point cloud. Experiments demonstrate that directly matching 2D and 3D descriptors is not only a viable idea but also achieves competitive accuracy compared to other state-of-the-art approaches for camera pose localization.
Label Universal Targeted Attack
Jun 01, 2019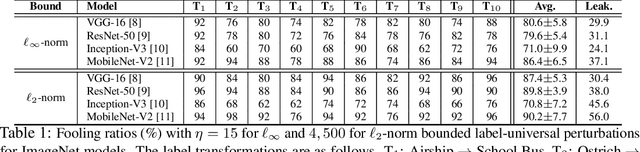
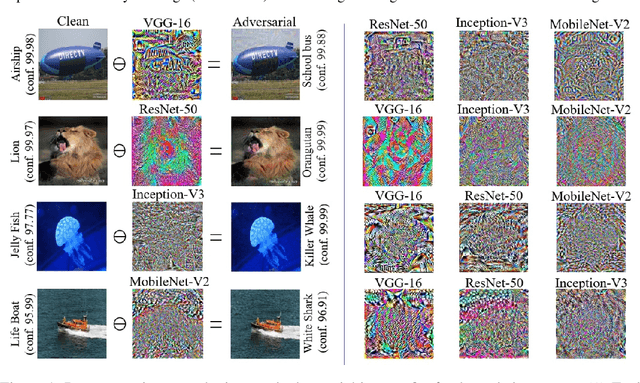


We introduce Label Universal Targeted Attack (LUTA) that makes a deep model predict a label of attacker's choice for `any' sample of a given source class with high probability. Our attack stochastically maximizes the log-probability of the target label for the source class with first order gradient optimization, while accounting for the gradient moments. It also suppresses the leakage of attack information to the non-source classes for avoiding the attack suspicions. The perturbations resulting from our attack achieve high fooling ratios on the large-scale ImageNet and VGGFace models, and transfer well to the Physical World. Given full control over the perturbation scope in LUTA, we also demonstrate it as a tool for deep model autopsy. The proposed attack reveals interesting perturbation patterns and observations regarding the deep models.