 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Inexact Unlearning Requires Revisiting Forgetting
Paper and Code


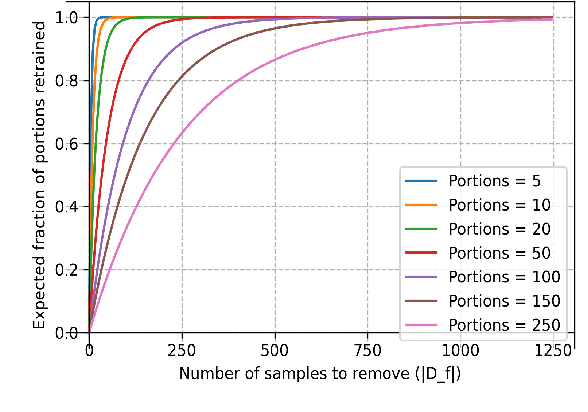

Existing works in inexact machine unlearning focus on achieving indistinguishability from models retrained after removing the deletion set. We argue that indistinguishability is unnecessary, infeasible to measure, and its practical relaxations can be insufficient. We redefine the goal of unlearning as forgetting all information specific to the deletion set while maintaining high utility and resource efficiency. Motivated by the practical application of removing mislabelled and biased data from models, we introduce a novel test to measure the degree of forgetting called Interclass Confusion (IC). It allows us to analyze two aspects of forgetting: (i) memorization and (ii) property generalization. Despite being a black-box test, IC can investigate whether information from the deletion set was erased until the early layers of the network. We empirically show that two simple unlearning methods, exact-unlearning and catastrophic-forgetting the final k layers of a network, scale well to large deletion sets unlike prior unlearning methods. k controls the forgetting-efficiency tradeoff at similar utility. Overall, we believe our formulation of unlearning and the IC test will guide the design of better unlearning algorithms.