 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagramIR: An Automatic Pipeline for Educational Math Diagram Evaluation
Nov 11, 2025Large Language Models (LLMs) are increasingly being adopted as tools for learning; however, most tools remain text-only, limiting their usefulness for domains where visualizations are essential, such as mathematics. Recent work shows that LLMs are capable of generating code that compiles to educational figures, but a major bottleneck remains: scalable evaluation of these diagrams. We address this by proposing DiagramIR: an automatic and scalable evaluation pipeline for geometric figures. Our method relies on intermediate representations (IRs) of LaTeX TikZ code. We compare our pipeline to other evaluation baselines such as LLM-as-a-Judge, showing that our approach has higher agreement with human raters. This evaluation approach also enables smaller models like GPT-4.1-Mini to perform comparably to larger models such as GPT-5 at a 10x lower inference cost, which is important for deploying accessible and scalable education technologies.
A Matter of Interest: Understanding Interestingness of Math Problems in Humans and Language Models
Nov 11, 2025The evolution of mathematics has been guided in part by interestingness. From researchers choosing which problems to tackle next, to students deciding which ones to engage with, people's choices are often guided by judgments about how interesting or challenging problems are likely to be. As AI systems, such as LLMs, increasingly participate in mathematics with people -- whether for advanced research or education -- it becomes important to understand how well their judgments align with human ones. Our work examines this alignment through two empirical studies of human and LLM assessment of mathematical interestingness and difficulty, spanning a range of mathematical experience. We study two groups: participants from a crowdsourcing platform and International Math Olympiad competitors. We show that while many LLMs appear to broadly agree with human notions of interestingness, they mostly do not capture the distribution observed in human judgments. Moreover, most LLMs only somewhat align with why humans find certain math problems interesting, showing weak correlation with human-selected interestingness rationales. Together, our findings highlight both the promises and limitations of current LLMs in capturing human interestingness judgments for mathematical AI thought partnerships.
MathCAMPS: Fine-grained Synthesis of Mathematical Problems From Human Curricula
Jul 01, 2024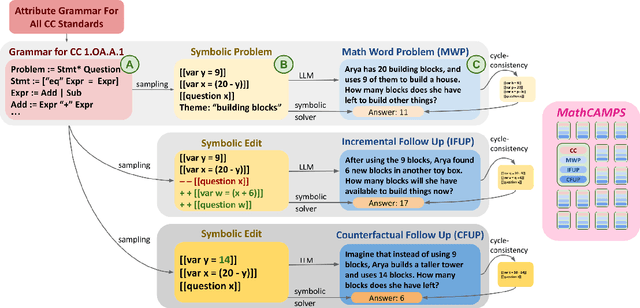
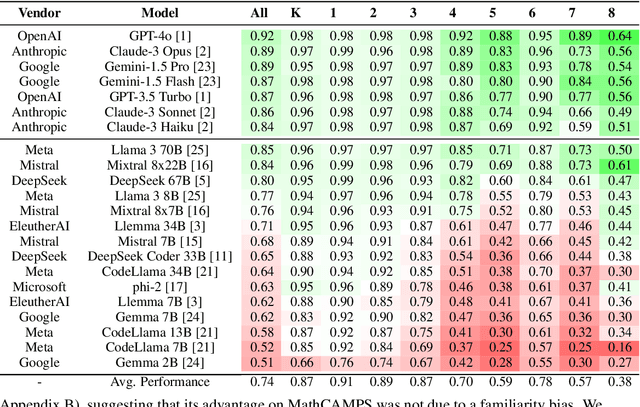
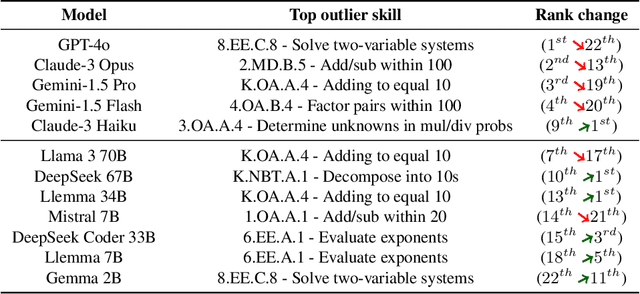
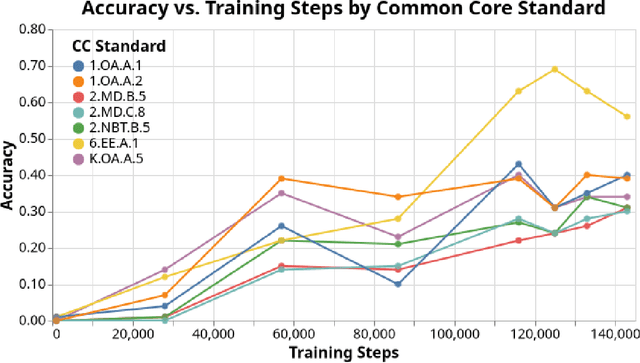
Mathematical problem solving is an important skill for Large Language Models (LLMs), both as an important capability and a proxy for a range of reasoning abilities. Existing benchmarks probe a diverse set of skills, but they yield aggregate accuracy metrics, obscuring specific abilities or weaknesses. Furthermore, they are difficult to extend with new problems, risking data contamination over time. To address these challenges, we propose MathCAMPS: a method to synthesize high-quality mathematical problems at scale, grounded on 44 fine-grained "standards" from the Mathematics Common Core (CC) Standard for K-8 grades. We encode each standard in a formal grammar, allowing us to sample diverse symbolic problems and their answers. We then use LLMs to realize the symbolic problems into word problems. We propose a cycle-consistency method for validating problem faithfulness. Finally, we derive follow-up questions from symbolic structures and convert them into follow-up word problems - a novel task of mathematical dialogue that probes for robustness in understanding. Experiments on 23 LLMs show surprising failures even in the strongest models (in particular when asked simple follow-up questions). Moreover, we evaluate training checkpoints of Pythia 12B on MathCAMPS, allowing us to analyze when particular mathematical skills develop during its training. Our framework enables the community to reproduce and extend our pipeline for a fraction of the typical cost of building new high-quality datasets.
An Evaluation Benchmark for Autoformalization in Lean4
Jun 01, 2024

Large Language Models (LLMs) hold the potential to revolutionize autoformalization. The introduction of Lean4, a mathematical programming language, presents an unprecedented opportunity to rigorously assess the autoformalization capabilities of LLMs. This paper introduces a novel evaluation benchmark designed for Lean4, applying it to test the abilities of state-of-the-art LLMs, including GPT-3.5, GPT-4, and Gemini Pro. Our comprehensive analysis reveals that, despite recent advancements, these LLMs still exhibit limitations in autoformalization, particularly in more complex areas of mathematics. These findings underscore the need for further development in LLMs to fully harness their potential in scientific research and development. This study not only benchmarks current LLM capabilities but also sets the stage for future enhancements in autoformalization.