 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut-of-Distribution Detection through Soft Clustering with Non-Negative Kernel Regression
Jul 18, 2024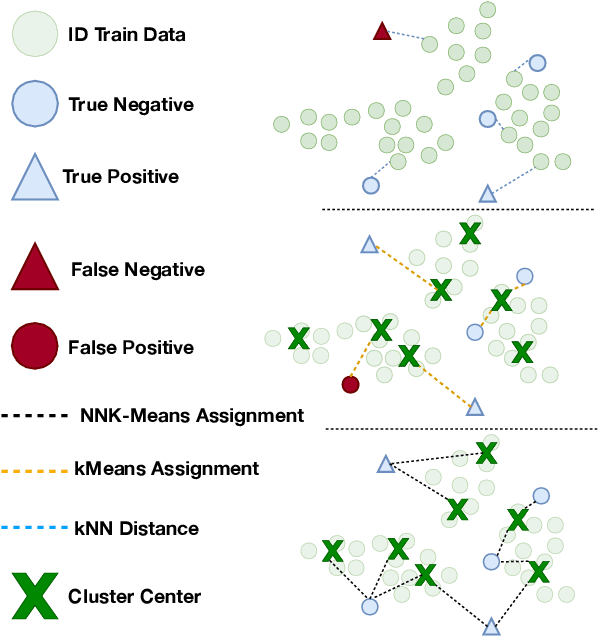


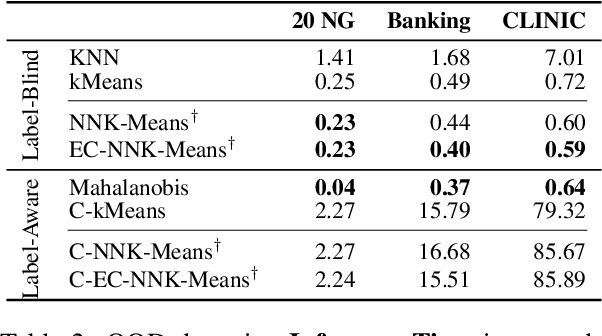
As language models become more general purpose, increased attention needs to be paid to detecting out-of-distribution (OOD) instances, i.e., those not belonging to any of the distributions seen during training. Existing methods for detecting OOD data are computationally complex and storage-intensive. We propose a novel soft clustering approach for OOD detection based on non-negative kernel regression. Our approach greatly reduces computational and space complexities (up to 11x improvement in inference time and 87% reduction in storage requirements) and outperforms existing approaches by up to 4 AUROC points on four different benchmarks. We also introduce an entropy-constrained version of our algorithm, which leads to further reductions in storage requirements (up to 97% lower than comparable approaches) while retaining competitive performance. Our soft clustering approach for OOD detection highlights its potential for detecting tail-end phenomena in extreme-scale data settings.
An Evaluation Benchmark for Autoformalization in Lean4
Jun 01, 2024

Large Language Models (LLMs) hold the potential to revolutionize autoformalization. The introduction of Lean4, a mathematical programming language, presents an unprecedented opportunity to rigorously assess the autoformalization capabilities of LLMs. This paper introduces a novel evaluation benchmark designed for Lean4, applying it to test the abilities of state-of-the-art LLMs, including GPT-3.5, GPT-4, and Gemini Pro. Our comprehensive analysis reveals that, despite recent advancements, these LLMs still exhibit limitations in autoformalization, particularly in more complex areas of mathematics. These findings underscore the need for further development in LLMs to fully harness their potential in scientific research and development. This study not only benchmarks current LLM capabilities but also sets the stage for future enhancements in autoformalization.