 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLean-ing on Quality: How High-Quality Data Beats Diverse Multilingual Data in AutoFormalization
Feb 18, 2025Autoformalization, the process of transforming informal mathematical language into formal specifications and proofs remains a difficult task for state-of-the-art (large) language models. Existing works point to competing explanations for the performance gap. To this end, we introduce a novel methodology that leverages back-translation with hand-curated prompts to enhance the mathematical capabilities of language models, particularly addressing the challenge posed by the scarcity of labeled data. Specifically, we evaluate three primary variations of this strategy: (1) on-the-fly (online) backtranslation, (2) distilled (offline) backtranslation with few-shot amplification, and (3) line-by-line proof analysis integrated with proof state information. Each variant is designed to optimize data quality over quantity, focusing on the high fidelity of generated proofs rather than sheer data scale. Our findings provide evidence that employing our proposed approaches to generate synthetic data, which prioritizes quality over volume, improves the Autoformalization performance of LLMs as measured by standard benchmarks such as ProofNet. Crucially, our approach outperforms pretrained models using a minimal number of tokens. We also show, through strategic prompting and backtranslation, that our approaches surpass the performance of fine-tuning with extensive multilingual datasets such as MMA on ProofNet with only 1/150th of the tokens. Taken together, our methods show a promising new approach to significantly reduce the resources required to formalize proofs, thereby accelerating AI for math.
ZIP-FIT: Embedding-Free Data Selection via Compression-Based Alignment
Oct 23, 2024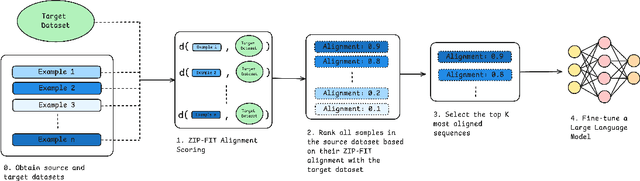

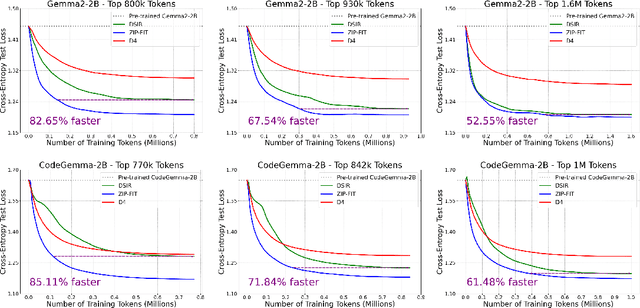
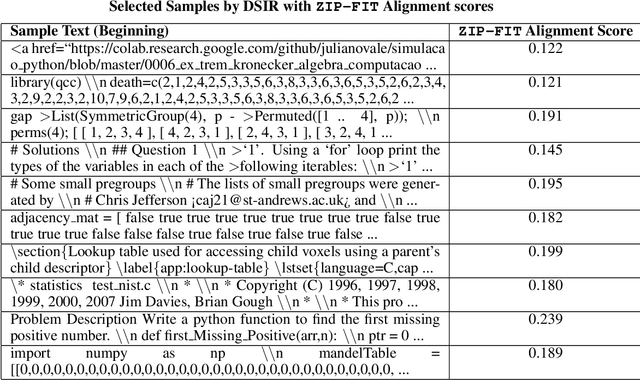
Data selection is crucial for optimizing language model (LM) performance on specific tasks, yet most existing methods fail to effectively consider the target task distribution. Current approaches either ignore task-specific requirements entirely or rely on approximations that fail to capture the nuanced patterns needed for tasks like Autoformalization or code generation. Methods that do consider the target distribution often rely on simplistic, sometimes noisy, representations, like hashed n-gram features, which can lead to collisions and introduce noise. We introduce ZIP-FIT, a data selection framework that uses gzip compression to directly measure alignment between potential training data and the target task distribution. In extensive evaluations on Autoformalization and Python code generation, ZIP-FIT significantly outperforms leading baselines like DSIR and D4. Models trained on ZIP-FIT-selected data achieve their lowest cross-entropy loss up to 85.1\% faster than baselines, demonstrating that better task alignment leads to more efficient learning. In addition, ZIP-FIT performs selection up to 65.8\% faster than DSIR and two orders of magnitude faster than D4. Notably, ZIP-FIT shows that smaller, well-aligned datasets often outperform larger but less targeted ones, demonstrating that a small amount of higher quality data is superior to a large amount of lower quality data. Our results imply that task-aware data selection is crucial for efficient domain adaptation, and that compression offers a principled way to measure task alignment. By showing that targeted data selection can dramatically improve task-specific performance, our work provides new insights into the relationship between data quality, task alignment, and model learning efficiency.