 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Pre-training Truly Better Than Meta-Learning?
Jun 24, 2023



In the context of few-shot learning, it is currently believed that a fixed pre-trained (PT) model, along with fine-tuning the final layer during evaluation, outperforms standard meta-learning algorithms. We re-evaluate these claims under an in-depth empirical examination of an extensive set of formally diverse datasets and compare PT to Model Agnostic Meta-Learning (MAML). Unlike previous work, we emphasize a fair comparison by using: the same architecture, the same optimizer, and all models trained to convergence. Crucially, we use a more rigorous statistical tool -- the effect size (Cohen's d) -- to determine the practical significance of the difference between a model trained with PT vs. a MAML. We then use a previously proposed metric -- the diversity coefficient -- to compute the average formal diversity of a dataset. Using this analysis, we demonstrate the following: 1. when the formal diversity of a data set is low, PT beats MAML on average and 2. when the formal diversity is high, MAML beats PT on average. The caveat is that the magnitude of the average difference between a PT vs. MAML using the effect size is low (according to classical statistical thresholds) -- less than 0.2. Nevertheless, this observation is contrary to the currently held belief that a pre-trained model is always better than a meta-learning model. Our extensive experiments consider 21 few-shot learning benchmarks, including the large-scale few-shot learning dataset Meta-Data set. We also show no significant difference between a MAML model vs. a PT model with GPT-2 on Openwebtext. We, therefore, conclude that a pre-trained model does not always beat a meta-learned model and that the formal diversity of a dataset is a driving factor.
The Curse of Low Task Diversity: On the Failure of Transfer Learning to Outperform MAML and Their Empirical Equivalence
Aug 02, 2022

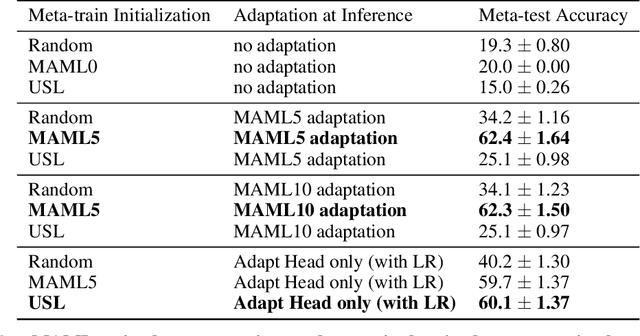
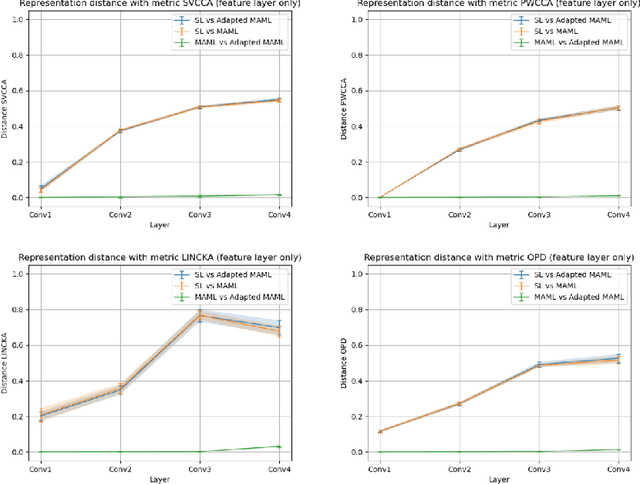
Recently, it has been observed that a transfer learning solution might be all we need to solve many few-shot learning benchmarks -- thus raising important questions about when and how meta-learning algorithms should be deployed. In this paper, we seek to clarify these questions by 1. proposing a novel metric -- the diversity coefficient -- to measure the diversity of tasks in a few-shot learning benchmark and 2. by comparing Model-Agnostic Meta-Learning (MAML) and transfer learning under fair conditions (same architecture, same optimizer, and all models trained to convergence). Using the diversity coefficient, we show that the popular MiniImageNet and CIFAR-FS few-shot learning benchmarks have low diversity. This novel insight contextualizes claims that transfer learning solutions are better than meta-learned solutions in the regime of low diversity under a fair comparison. Specifically, we empirically find that a low diversity coefficient correlates with a high similarity between transfer learning and MAML learned solutions in terms of accuracy at meta-test time and classification layer similarity (using feature based distance metrics like SVCCA, PWCCA, CKA, and OPD). To further support our claim, we find this meta-test accuracy holds even as the model size changes. Therefore, we conclude that in the low diversity regime, MAML and transfer learning have equivalent meta-test performance when both are compared fairly. We also hope our work inspires more thoughtful constructions and quantitative evaluations of meta-learning benchmarks in the future.
LEASGD: an Efficient and Privacy-Preserving Decentralized Algorithm for Distributed Learning
Nov 27, 2018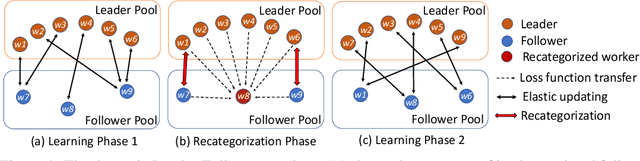
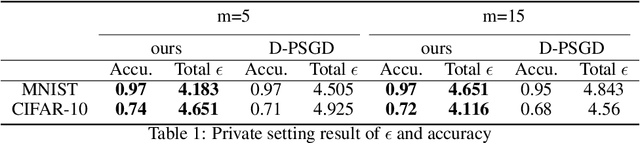
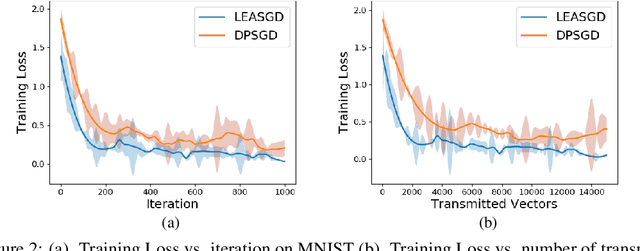
Distributed learning systems have enabled training large-scale models over large amount of data in significantly shorter time. In this paper, we focus on decentralized distributed deep learning systems and aim to achieve differential privacy with good convergence rate and low communication cost. To achieve this goal, we propose a new learning algorithm LEASGD (Leader-Follower Elastic Averaging Stochastic Gradient Descent), which is driven by a novel Leader-Follower topology and a differential privacy model.We provide a theoretical analysis of the convergence rate and the trade-off between the performance and privacy in the private setting.The experimental results show that LEASGD outperforms state-of-the-art decentralized learning algorithm DPSGD by achieving steadily lower loss within the same iterations and by reducing the communication cost by 30%. In addition, LEASGD spends less differential privacy budget and has higher final accuracy result than DPSGD under private setting.