 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORE-Bench: Fostering the Credibility of Published Research Through a Computational Reproducibility Agent Benchmark
Paper and Code
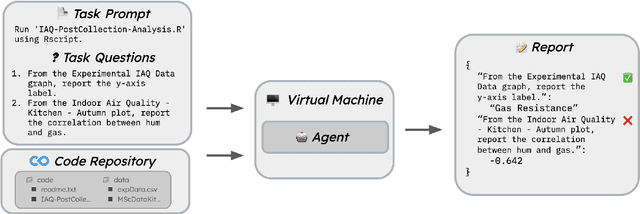
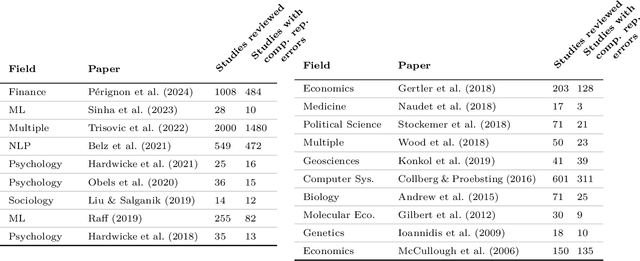

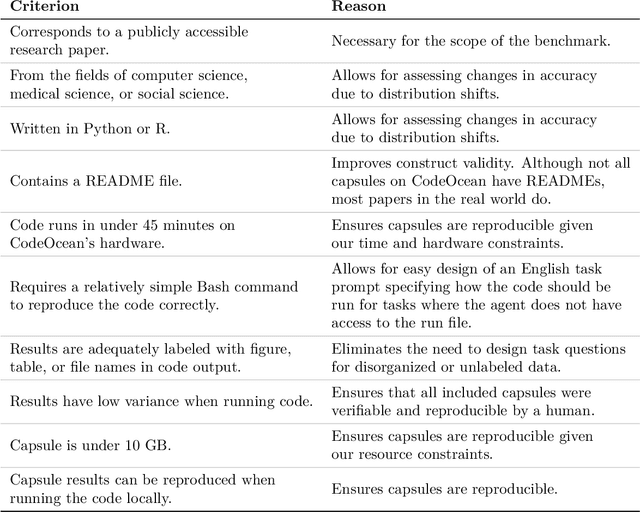
AI agents have the potential to aid users on a variety of consequential tasks, including conducting scientific research. To spur the development of useful agents, we need benchmarks that are challenging, but more crucially, directly correspond to real-world tasks of interest. This paper introduces such a benchmark, designed to measure the accuracy of AI agents in tackling a crucial yet surprisingly challenging aspect of scientific research: computational reproducibility. This task, fundamental to the scientific process, involves reproducing the results of a study using the provided code and data. We introduce CORE-Bench (Computational Reproducibility Agent Benchmark), a benchmark consisting of 270 tasks based on 90 scientific papers across three disciplines (computer science, social science, and medicine). Tasks in CORE-Bench consist of three difficulty levels and include both language-only and vision-language tasks. We provide an evaluation system to measure the accuracy of agents in a fast and parallelizable way, saving days of evaluation time for each run compared to a sequential implementation. We evaluated two baseline agents: the general-purpose AutoGPT and a task-specific agent called CORE-Agent. We tested both variants using two underlying language models: GPT-4o and GPT-4o-mini. The best agent achieved an accuracy of 21% on the hardest task, showing the vast scope for improvement in automating routine scientific tasks. Having agents that can reproduce existing work is a necessary step towards building agents that can conduct novel research and could verify and improve the performance of other research agents. We hope that CORE-Bench can improve the state of reproducibility and spur the development of future research agents.