 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTamperBench: Systematically Stress-Testing LLM Safety Under Fine-Tuning and Tampering
Feb 06, 2026As increasingly capable open-weight large language models (LLMs) are deployed, improving their tamper resistance against unsafe modifications, whether accidental or intentional, becomes critical to minimize risks. However, there is no standard approach to evaluate tamper resistance. Varied data sets, metrics, and tampering configurations make it difficult to compare safety, utility, and robustness across different models and defenses. To this end, we introduce TamperBench, the first unified framework to systematically evaluate the tamper resistance of LLMs. TamperBench (i) curates a repository of state-of-the-art weight-space fine-tuning attacks and latent-space representation attacks; (ii) enables realistic adversarial evaluation through systematic hyperparameter sweeps per attack-model pair; and (iii) provides both safety and utility evaluations. TamperBench requires minimal additional code to specify any fine-tuning configuration, alignment-stage defense method, and metric suite while ensuring end-to-end reproducibility. We use TamperBench to evaluate 21 open-weight LLMs, including defense-augmented variants, across nine tampering threats using standardized safety and capability metrics with hyperparameter sweeps per model-attack pair. This yields novel insights, including effects of post-training on tamper resistance, that jailbreak-tuning is typically the most severe attack, and that Triplet emerges as a leading alignment-stage defense. Code is available at: https://github.com/criticalml-uw/TamperBench
Randomized Gradient Subspaces for Efficient Large Language Model Training
Oct 02, 2025Training large language models (LLMs) is often bottlenecked by extreme memory demands, with optimizer states dominating the footprint. Recent works mitigates this cost by projecting gradients into low-dimensional subspaces using sophisticated update strategies. In this paper, we analyze the dynamics of gradient space and its underlying subspaces. We find that while a small subspace captures most gradient energy, a significant portion still resides in the residual bulk; moreover, the influence of the core subspace diminishes over time and in deeper layers. We also observe that the gradient space exhibits near-flat curvature, calling for algorithms that explicitly account for this geometry. Motivated by these insights, we introduce a suite of randomized algorithms, GrassWalk and GrassJump, which exploit subspace and achieve state-of-the-art memory savings while improving performance on LLaMA-1B and LLaMA-7B pretraining.
SubTrack your Grad: Gradient Subspace Tracking for Memory and Time Efficient Full-Parameter LLM Training
Feb 03, 2025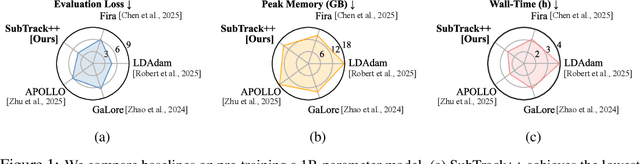
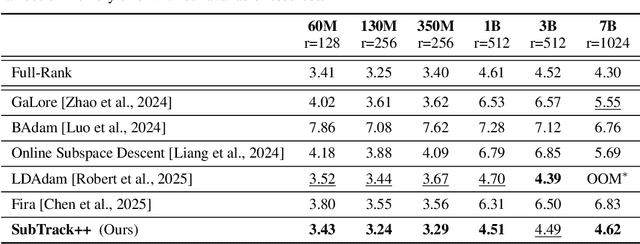
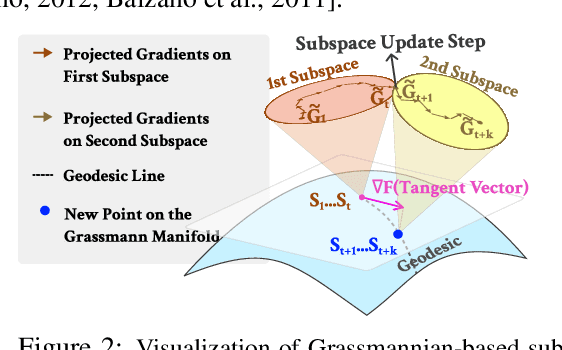
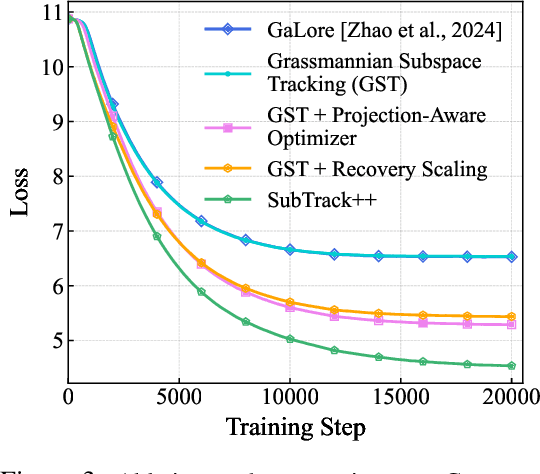
Training Large Language Models (LLMs) demand significant time and computational resources due to their large model sizes and optimizer states. To overcome these challenges, recent methods, such as BAdam, employ partial weight updates to enhance time and memory efficiency, though sometimes at the cost of performance. Others, like GaLore, focus on maintaining performance while optimizing memory usage through full parameter training, but may incur higher time complexity. By leveraging the low-rank structure of the gradient and the Grassmannian geometry, we propose SubTrack-Grad, a subspace tracking-based optimization method that efficiently tracks the evolving gradient subspace by incorporating estimation errors and previously identified subspaces. SubTrack-Grad delivers better or on-par results compared to GaLore, while significantly outperforming BAdam, which, despite being time-efficient, compromises performance. SubTrack-Grad reduces wall-time by up to 20.57% on GLUE tasks (15% average reduction) and up to 65% on SuperGLUE tasks (22% average reduction) compared to GaLore. Notably, for a 3B parameter model, GaLore incurred a substantial 157% increase in wall-time compared to full-rank training, whereas SubTrack-Grad exhibited a 31% increase, representing a 49% reduction in wall-time, while enjoying the same memory reductions as GaLore.