 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepVRegulome: DNABERT-based deep-learning framework for predicting the functional impact of short genomic variants on the human regulome
Nov 12, 2025
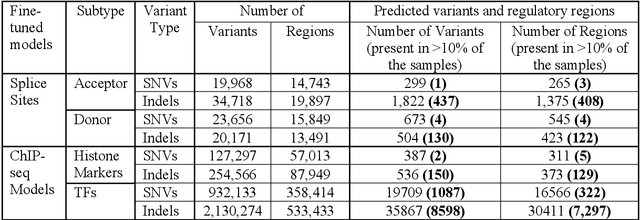


Whole-genome sequencing (WGS) has revealed numerous non-coding short variants whose functional impacts remain poorly understood. Despite recent advances in deep-learning genomic approaches, accurately predicting and prioritizing clinically relevant mutations in gene regulatory regions remains a major challenge. Here we introduce Deep VRegulome, a deep-learning method for prediction and interpretation of functionally disruptive variants in the human regulome, which combines 700 DNABERT fine-tuned models, trained on vast amounts of ENCODE gene regulatory regions, with variant scoring, motif analysis, attention-based visualization, and survival analysis. We showcase its application on TCGA glioblastoma WGS dataset in prioritizing survival-associated mutations and regulatory regions. The analysis identified 572 splice-disrupting and 9,837 transcription-factor binding site altering mutations occurring in greater than 10% of glioblastoma samples. Survival analysis linked 1352 mutations and 563 disrupted regulatory regions to patient outcomes, enabling stratification via non-coding mutation signatures. All the code, fine-tuned models, and an interactive data portal are publicly available.
DNABERT-2: Efficient Foundation Model and Benchmark For Multi-Species Genome
Jun 26, 2023
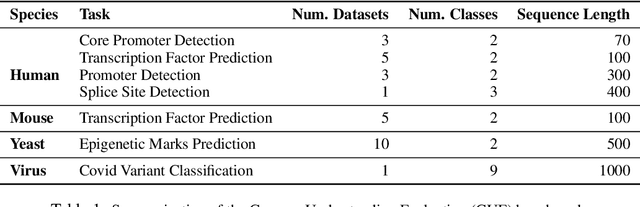

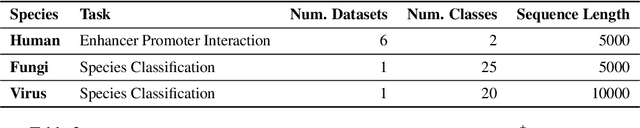
Decoding the linguistic intricacies of the genome is a crucial problem in biology, and pre-trained foundational models such as DNABERT and Nucleotide Transformer have made significant strides in this area. Existing works have largely hinged on k-mer, fixed-length permutations of A, T, C, and G, as the token of the genome language due to its simplicity. However, we argue that the computation and sample inefficiencies introduced by k-mer tokenization are primary obstacles in developing large genome foundational models. We provide conceptual and empirical insights into genome tokenization, building on which we propose to replace k-mer tokenization with Byte Pair Encoding (BPE), a statistics-based data compression algorithm that constructs tokens by iteratively merging the most frequent co-occurring genome segment in the corpus. We demonstrate that BPE not only overcomes the limitations of k-mer tokenization but also benefits from the computational efficiency of non-overlapping tokenization. Based on these insights, we introduce DNABERT-2, a refined genome foundation model that adapts an efficient tokenizer and employs multiple strategies to overcome input length constraints, reduce time and memory expenditure, and enhance model capability. Furthermore, we identify the absence of a comprehensive and standardized benchmark for genome understanding as another significant impediment to fair comparative analysis. In response, we propose the Genome Understanding Evaluation (GUE), a comprehensive multi-species genome classification dataset that amalgamates $28$ distinct datasets across $7$ tasks, with input lengths ranging from $70$ to $1000$. Through comprehensive experiments on the GUE benchmark, we demonstrate that DNABERT-2 achieves comparable performance to the state-of-the-art model with $21 \times$ fewer parameters and approximately $56 \times$ less GPU time in pre-training.
Machine: The New Art Connoisseur
Dec 03, 2019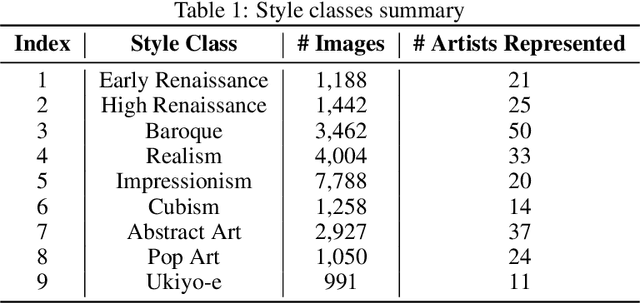
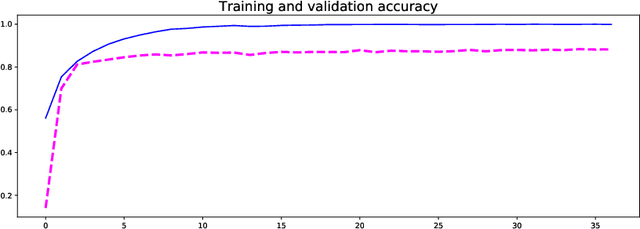

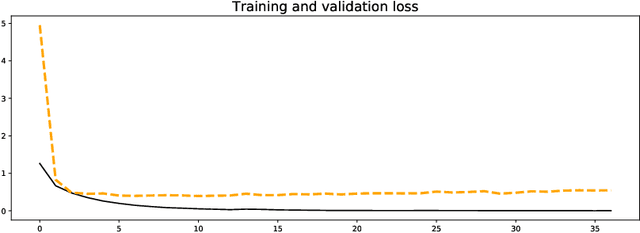
The process of identifying and understanding art styles to discover artistic influences is essential to the study of art history. Traditionally, trained experts review fine details of the works and compare them to other known works. To automate and scale this task, we use several state-of-the-art CNN architectures to explore how a machine may help perceive and quantify art styles. This study explores: (1) How accurately can a machine classify art styles? (2) What may be the underlying relationships among different styles and artists? To help answer the first question, our best-performing model using Inception V3 achieves a 9-class classification accuracy of 88.35%, which outperforms the model in Elgammal et al.'s study by more than 20 percent. Visualizations using Grad-CAM heat maps confirm that the model correctly focuses on the characteristic parts of paintings. To help address the second question, we conduct network analysis on the influences among styles and artists by extracting 512 features from the best-performing classification model. Through 2D and 3D T-SNE visualizations, we observe clear chronological patterns of development and separation among the art styles. The network analysis also appears to show anticipated artist level connections from an art historical perspective. This technique appears to help identify some previously unknown linkages that may shed light upon new directions for further exploration by art historians. We hope that humans and machines working in concert may bring new opportunities to the field.