 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Deep Learning Recommender Systems' Training On CPU Cluster Architectures
May 10, 2020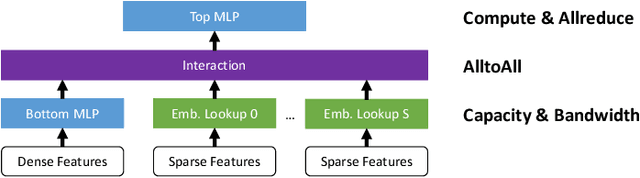

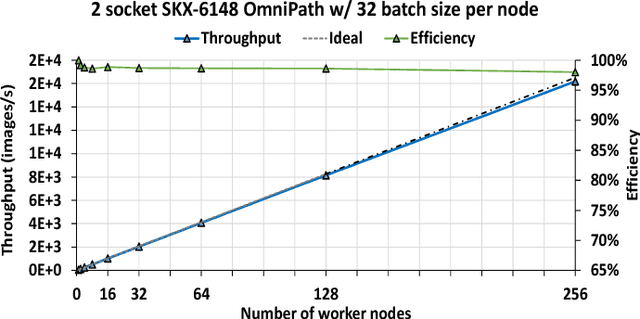
During the last two years, the goal of many researchers has been to squeeze the last bit of performance out of HPC system for AI tasks. Often this discussion is held in the context of how fast ResNet50 can be trained. Unfortunately, ResNet50 is no longer a representative workload in 2020. Thus, we focus on Recommender Systems which account for most of the AI cycles in cloud computing centers. More specifically, we focus on Facebook's DLRM benchmark. By enabling it to run on latest CPU hardware and software tailored for HPC, we are able to achieve more than two-orders of magnitude improvement in performance (110x) on a single socket compared to the reference CPU implementation, and high scaling efficiency up to 64 sockets, while fitting ultra-large datasets. This paper discusses the optimization techniques for the various operators in DLRM and which component of the systems are stressed by these different operators. The presented techniques are applicable to a broader set of DL workloads that pose the same scaling challenges/characteristics as DLRM.
On Scale-out Deep Learning Training for Cloud and HPC
Jan 24, 2018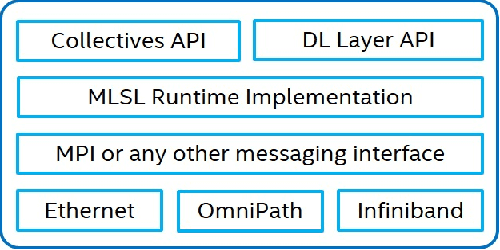
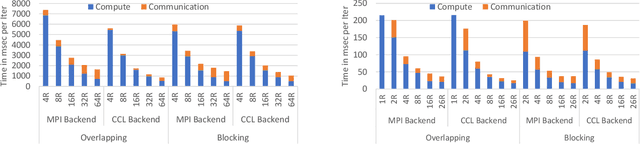
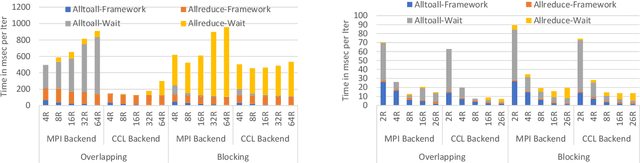
The exponential growth in use of large deep neural networks has accelerated the need for training these deep neural networks in hours or even minutes. This can only be achieved through scalable and efficient distributed training, since a single node/card cannot satisfy the compute, memory, and I/O requirements of today's state-of-the-art deep neural networks. However, scaling synchronous Stochastic Gradient Descent (SGD) is still a challenging problem and requires continued research/development. This entails innovations spanning algorithms, frameworks, communication libraries, and system design. In this paper, we describe the philosophy, design, and implementation of Intel Machine Learning Scalability Library (MLSL) and present proof-points demonstrating scaling DL training on 100s to 1000s of nodes across Cloud and HPC systems.
Deep Learning at 15PF: Supervised and Semi-Supervised Classification for Scientific Data
Aug 17, 2017
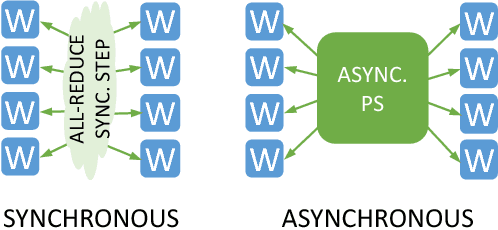
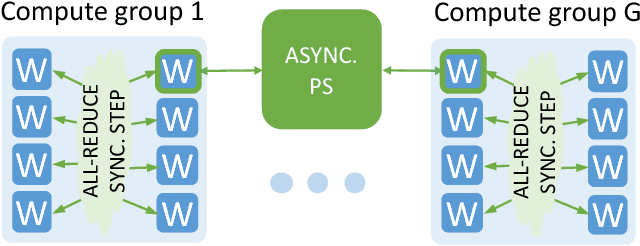
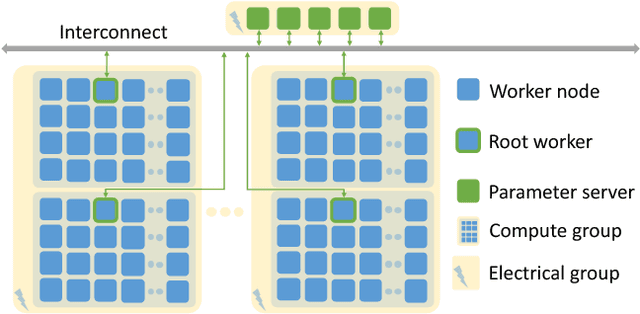
This paper presents the first, 15-PetaFLOP Deep Learning system for solving scientific pattern classification problems on contemporary HPC architectures. We develop supervised convolutional architectures for discriminating signals in high-energy physics data as well as semi-supervised architectures for localizing and classifying extreme weather in climate data. Our Intelcaffe-based implementation obtains $\sim$2TFLOP/s on a single Cori Phase-II Xeon-Phi node. We use a hybrid strategy employing synchronous node-groups, while using asynchronous communication across groups. We use this strategy to scale training of a single model to $\sim$9600 Xeon-Phi nodes; obtaining peak performance of 11.73-15.07 PFLOP/s and sustained performance of 11.41-13.27 PFLOP/s. At scale, our HEP architecture produces state-of-the-art classification accuracy on a dataset with 10M images, exceeding that achieved by selections on high-level physics-motivated features. Our semi-supervised architecture successfully extracts weather patterns in a 15TB climate dataset. Our results demonstrate that Deep Learning can be optimized and scaled effectively on many-core, HPC systems.