 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale out for large minibatch SGD: Residual network training on ImageNet-1K with improved accuracy and reduced time to train
Paper and Code
Nov 15, 2017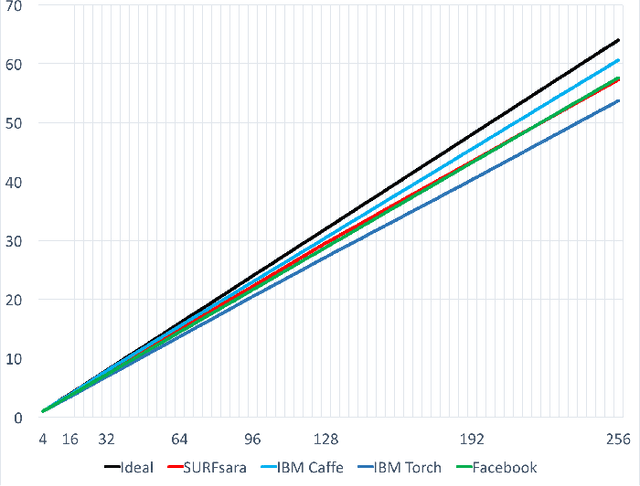
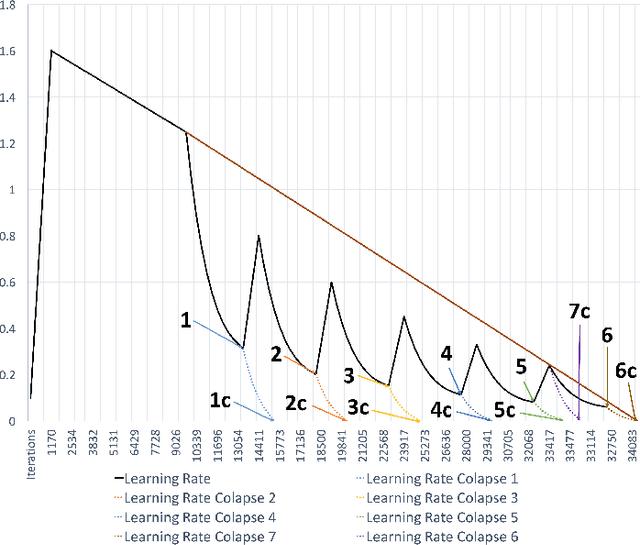
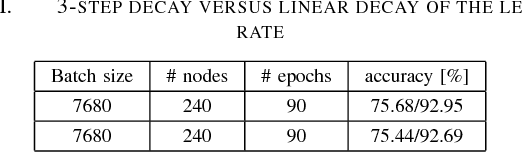
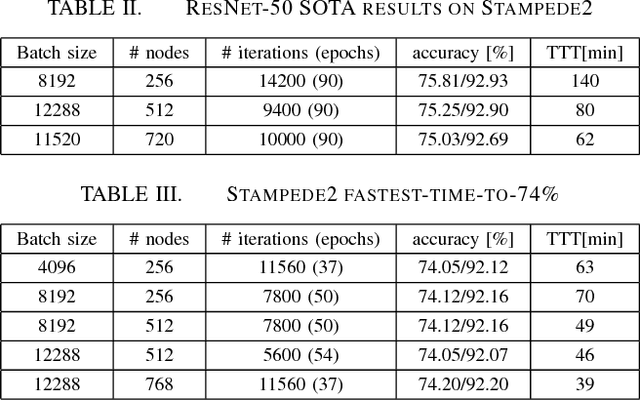
For the past 5 years, the ILSVRC competition and the ImageNet dataset have attracted a lot of interest from the Computer Vision community, allowing for state-of-the-art accuracy to grow tremendously. This should be credited to the use of deep artificial neural network designs. As these became more complex, the storage, bandwidth, and compute requirements increased. This means that with a non-distributed approach, even when using the most high-density server available, the training process may take weeks, making it prohibitive. Furthermore, as datasets grow, the representation learning potential of deep networks grows as well by using more complex models. This synchronicity triggers a sharp increase in the computational requirements and motivates us to explore the scaling behaviour on petaflop scale supercomputers. In this paper we will describe the challenges and novel solutions needed in order to train ResNet-50 in this large scale environment. We demonstrate above 90\% scaling efficiency and a training time of 28 minutes using up to 104K x86 cores. This is supported by software tools from Intel's ecosystem. Moreover, we show that with regular 90 - 120 epoch train runs we can achieve a top-1 accuracy as high as 77\% for the unmodified ResNet-50 topology. We also introduce the novel Collapsed Ensemble (CE) technique that allows us to obtain a 77.5\% top-1 accuracy, similar to that of a ResNet-152, while training a unmodified ResNet-50 topology for the same fixed training budget. All ResNet-50 models as well as the scripts needed to replicate them will be posted shortly.