 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Labels are as Effective as Manual Labels in Biomedical Images Classification with Deep Learning
Jun 20, 2024The increasing availability of biomedical data is helping to design more robust deep learning (DL) algorithms to analyze biomedical samples. Currently, one of the main limitations to train DL algorithms to perform a specific task is the need for medical experts to label data. Automatic methods to label data exist, however automatic labels can be noisy and it is not completely clear when automatic labels can be adopted to train DL models. This paper aims to investigate under which circumstances automatic labels can be adopted to train a DL model on the classification of Whole Slide Images (WSI). The analysis involves multiple architectures, such as Convolutional Neural Networks (CNN) and Vision Transformer (ViT), and over 10000 WSIs, collected from three use cases: celiac disease, lung cancer and colon cancer, which one including respectively binary, multiclass and multilabel data. The results allow identifying 10% as the percentage of noisy labels that lead to train competitive models for the classification of WSIs. Therefore, an algorithm generating automatic labels needs to fit this criterion to be adopted. The application of the Semantic Knowledge Extractor Tool (SKET) algorithm to generate automatic labels leads to performance comparable to the one obtained with manual labels, since it generates a percentage of noisy labels between 2-5%. Automatic labels are as effective as manual ones, reaching solid performance comparable to the one obtained training models with manual labels.
Neural Symplectic Integrator with Hamiltonian Inductive Bias for the Gravitational $N$-body Problem
Nov 28, 2021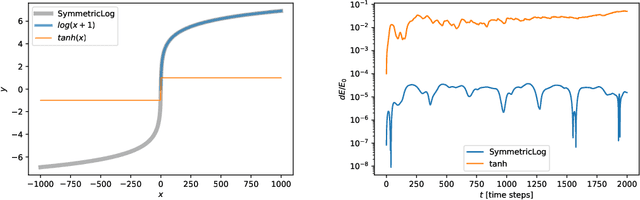
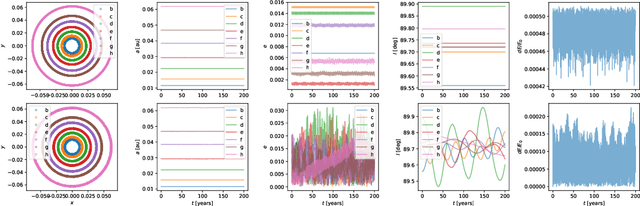
The gravitational $N$-body problem, which is fundamentally important in astrophysics to predict the motion of $N$ celestial bodies under the mutual gravity of each other, is usually solved numerically because there is no known general analytical solution for $N>2$. Can an $N$-body problem be solved accurately by a neural network (NN)? Can a NN observe long-term conservation of energy and orbital angular momentum? Inspired by Wistom & Holman (1991)'s symplectic map, we present a neural $N$-body integrator for splitting the Hamiltonian into a two-body part, solvable analytically, and an interaction part that we approximate with a NN. Our neural symplectic $N$-body code integrates a general three-body system for $10^{5}$ steps without diverting from the ground truth dynamics obtained from a traditional $N$-body integrator. Moreover, it exhibits good inductive bias by successfully predicting the evolution of $N$-body systems that are no part of the training set.
Predicting atmospheric optical properties for radiative transfer computations using neural networks
May 06, 2020



The radiative transfer equations are well-known, but radiation parametrizations in atmospheric models are computationally expensive. A promising tool for accelerating parametrizations is the use of machine learning techniques. In this study, we develop a machine learning-based parametrization for the gaseous optical properties by training neural networks to emulate the Rapid Radiative Transfer model for General circulation Model applications - Parallel (RRTMGP). To minimize computational costs, we reduce the range of atmospheric conditions for which the neural networks are applicable and use machine-specific optimised BLAS functions to accelerate matrix computations. To generate training data, we use a set of randomly perturbed atmospheric profiles and calculate optical properties using RRTMGP. Predicted optical properties are highly accurate and the resulting radiative fluxes have errors within 1.2 W m$^{-2}$ for longwave and 0.12 W m$^{-2}$ for shortwave radiation. Our parametrization is 3 to 7 times faster than RRTMGP, depending on the size of the neural networks. We further test the trade-off between speed and accuracy by training neural networks for a single LES case, so smaller and therefore faster networks can achieve a desired accuracy, especially for shortwave radiation. We conclude that our machine learning-based parametrization can speed-up radiative transfer computations whilst retaining high accuracy.
Densifying Assumed-sparse Tensors: Improving Memory Efficiency and MPI Collective Performance during Tensor Accumulation for Parallelized Training of Neural Machine Translation Models
May 10, 2019


Neural machine translation - using neural networks to translate human language - is an area of active research exploring new neuron types and network topologies with the goal of dramatically improving machine translation performance. Current state-of-the-art approaches, such as the multi-head attention-based transformer, require very large translation corpuses and many epochs to produce models of reasonable quality. Recent attempts to parallelize the official TensorFlow "Transformer" model across multiple nodes have hit roadblocks due to excessive memory use and resulting out of memory errors when performing MPI collectives. This paper describes modifications made to the Horovod MPI-based distributed training framework to reduce memory usage for transformer models by converting assumed-sparse tensors to dense tensors, and subsequently replacing sparse gradient gather with dense gradient reduction. The result is a dramatic increase in scale-out capability, with CPU-only scaling tests achieving 91% weak scaling efficiency up to 1200 MPI processes (300 nodes), and up to 65% strong scaling efficiency up to 400 MPI processes (200 nodes) using the Stampede2 supercomputer.
Scale out for large minibatch SGD: Residual network training on ImageNet-1K with improved accuracy and reduced time to train
Nov 15, 2017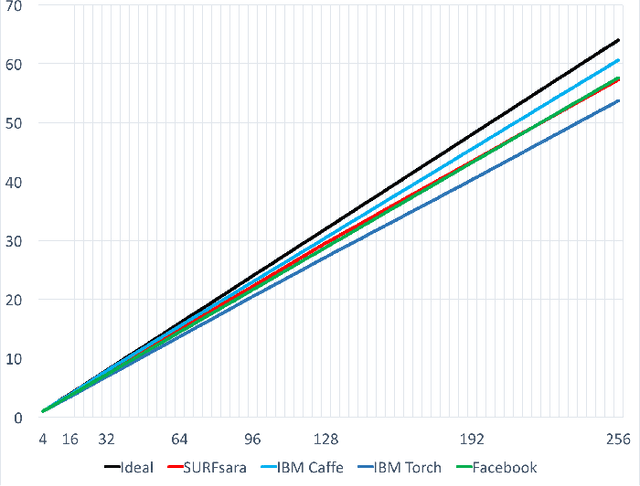
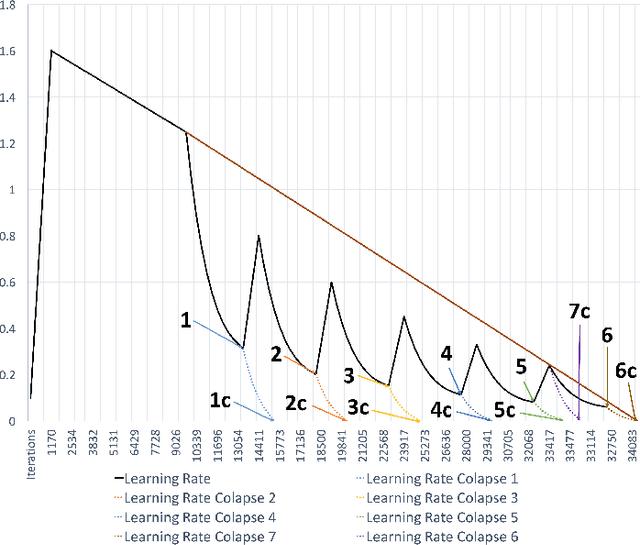
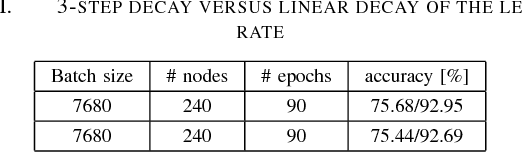
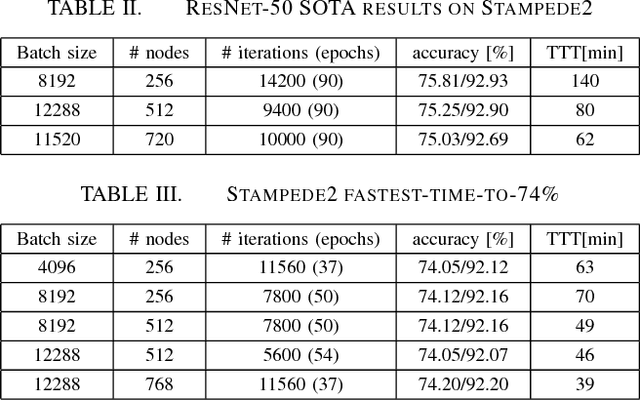
For the past 5 years, the ILSVRC competition and the ImageNet dataset have attracted a lot of interest from the Computer Vision community, allowing for state-of-the-art accuracy to grow tremendously. This should be credited to the use of deep artificial neural network designs. As these became more complex, the storage, bandwidth, and compute requirements increased. This means that with a non-distributed approach, even when using the most high-density server available, the training process may take weeks, making it prohibitive. Furthermore, as datasets grow, the representation learning potential of deep networks grows as well by using more complex models. This synchronicity triggers a sharp increase in the computational requirements and motivates us to explore the scaling behaviour on petaflop scale supercomputers. In this paper we will describe the challenges and novel solutions needed in order to train ResNet-50 in this large scale environment. We demonstrate above 90\% scaling efficiency and a training time of 28 minutes using up to 104K x86 cores. This is supported by software tools from Intel's ecosystem. Moreover, we show that with regular 90 - 120 epoch train runs we can achieve a top-1 accuracy as high as 77\% for the unmodified ResNet-50 topology. We also introduce the novel Collapsed Ensemble (CE) technique that allows us to obtain a 77.5\% top-1 accuracy, similar to that of a ResNet-152, while training a unmodified ResNet-50 topology for the same fixed training budget. All ResNet-50 models as well as the scripts needed to replicate them will be posted shortly.