 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSDM 2.0: Time-Accurate Speech Rich Transcription with Non-Fluencies
Nov 29, 2024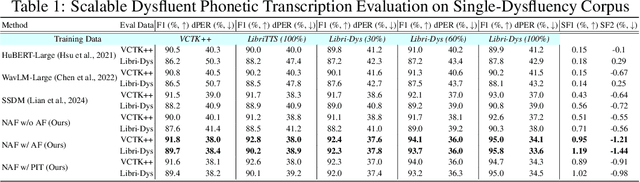
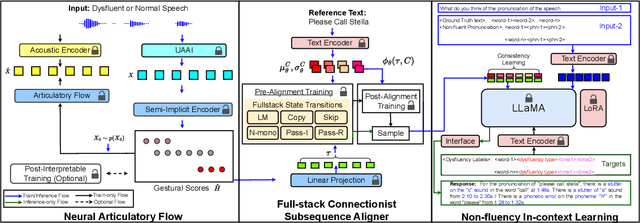

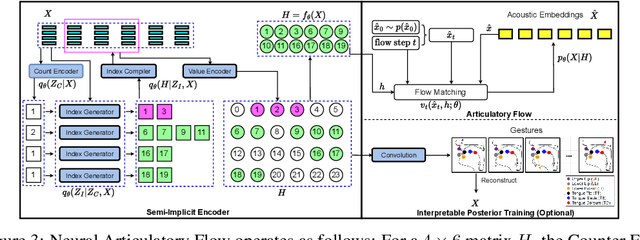
Speech is a hierarchical collection of text, prosody, emotions, dysfluencies, etc. Automatic transcription of speech that goes beyond text (words) is an underexplored problem. We focus on transcribing speech along with non-fluencies (dysfluencies). The current state-of-the-art pipeline SSDM suffers from complex architecture design, training complexity, and significant shortcomings in the local sequence aligner, and it does not explore in-context learning capacity. In this work, we propose SSDM 2.0, which tackles those shortcomings via four main contributions: (1) We propose a novel \textit{neural articulatory flow} to derive highly scalable speech representations. (2) We developed a \textit{full-stack connectionist subsequence aligner} that captures all types of dysfluencies. (3) We introduced a mispronunciation prompt pipeline and consistency learning module into LLM to leverage dysfluency \textit{in-context pronunciation learning} abilities. (4) We curated Libri-Dys and open-sourced the current largest-scale co-dysfluency corpus, \textit{Libri-Co-Dys}, for future research endeavors. In clinical experiments on pathological speech transcription, we tested SSDM 2.0 using nfvPPA corpus primarily characterized by \textit{articulatory dysfluencies}. Overall, SSDM 2.0 outperforms SSDM and all other dysfluency transcription models by a large margin. See our project demo page at \url{https://berkeley-speech-group.github.io/SSDM2.0/}.
SSDM: Scalable Speech Dysfluency Modeling
Aug 29, 2024



Speech dysfluency modeling is the core module for spoken language learning, and speech therapy. However, there are three challenges. First, current state-of-the-art solutions suffer from poor scalability. Second, there is a lack of a large-scale dysfluency corpus. Third, there is not an effective learning framework. In this paper, we propose \textit{SSDM: Scalable Speech Dysfluency Modeling}, which (1) adopts articulatory gestures as scalable forced alignment; (2) introduces connectionist subsequence aligner (CSA) to achieve dysfluency alignment; (3) introduces a large-scale simulated dysfluency corpus called Libri-Dys; and (4) develops an end-to-end system by leveraging the power of large language models (LLMs). We expect SSDM to serve as a standard in the area of dysfluency modeling. Demo is available at \url{https://eureka235.github.io}.