 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion-Aligned Contrastive Learning Between Images and Music
Aug 24, 2023Traditional music search engines rely on retrieval methods that match natural language queries with music metadata. There have been increasing efforts to expand retrieval methods to consider the audio characteristics of music itself, using queries of various modalities including text, video, and speech. Most approaches aim to match general music semantics to the input queries, while only a few focus on affective qualities. We address the task of retrieving emotionally-relevant music from image queries by proposing a framework for learning an affective alignment between images and music audio. Our approach focuses on learning an emotion-aligned joint embedding space between images and music. This joint embedding space is learned via emotion-supervised contrastive learning, using an adapted cross-modal version of the SupCon loss. We directly evaluate the joint embeddings with cross-modal retrieval tasks (image-to-music and music-to-image) based on emotion labels. In addition, we investigate the generalizability of the learned music embeddings with automatic music tagging as a downstream task. Our experiments show that our approach successfully aligns images and music, and that the learned embedding space is effective for cross-modal retrieval applications.
On the Role of Visual Context in Enriching Music Representations
Oct 28, 2022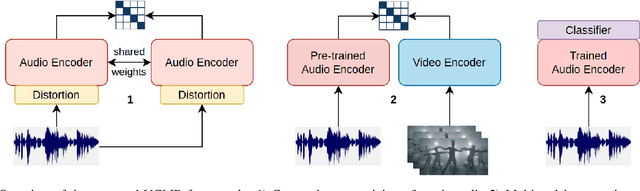
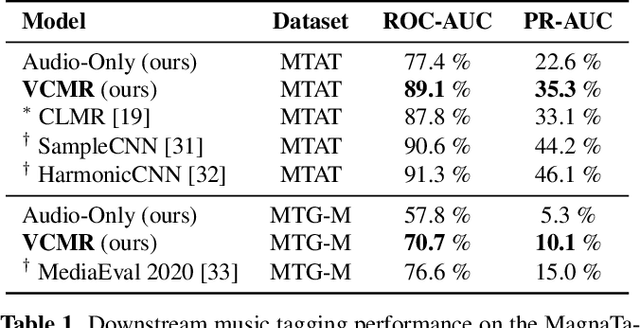
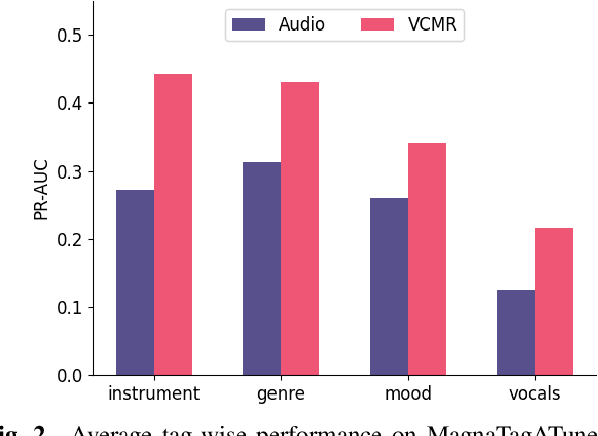
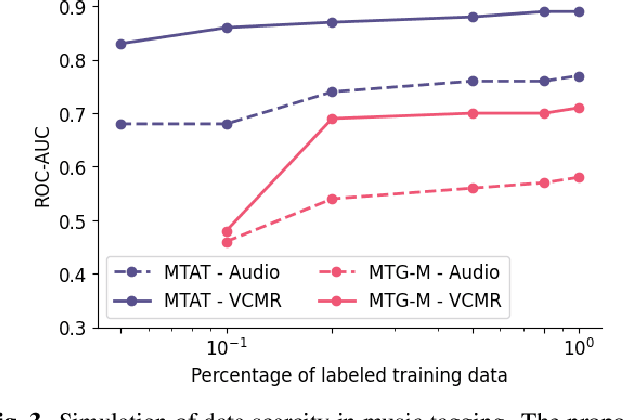
Human perception and experience of music is highly context-dependent. Contextual variability contributes to differences in how we interpret and interact with music, challenging the design of robust models for information retrieval. Incorporating multimodal context from diverse sources provides a promising approach toward modeling this variability. Music presented in media such as movies and music videos provide rich multimodal context that modulates underlying human experiences. However, such context modeling is underexplored, as it requires large amounts of multimodal data along with relevant annotations. Self-supervised learning can help address these challenges by automatically extracting rich, high-level correspondences between different modalities, hence alleviating the need for fine-grained annotations at scale. In this study, we propose VCMR -- Video-Conditioned Music Representations, a contrastive learning framework that learns music representations from audio and the accompanying music videos. The contextual visual information enhances representations of music audio, as evaluated on the downstream task of music tagging. Experimental results show that the proposed framework can contribute additive robustness to audio representations and indicates to what extent musical elements are affected or determined by visual context.
Exploring Out-of-Distribution Generalization in Text Classifiers Trained on Tobacco-3482 and RVL-CDIP
Aug 05, 2021



To be robust enough for widespread adoption, document analysis systems involving machine learning models must be able to respond correctly to inputs that fall outside of the data distribution that was used to generate the data on which the models were trained. This paper explores the ability of text classifiers trained on standard document classification datasets to generalize to out-of-distribution documents at inference time. We take the Tobacco-3482 and RVL-CDIP datasets as a starting point and generate new out-of-distribution evaluation datasets in order to analyze the generalization performance of models trained on these standard datasets. We find that models trained on the smaller Tobacco-3482 dataset perform poorly on our new out-of-distribution data, while text classification models trained on the larger RVL-CDIP exhibit smaller performance drops.