 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Role of Visual Context in Enriching Music Representations
Paper and Code
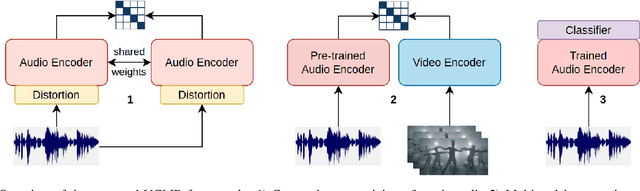
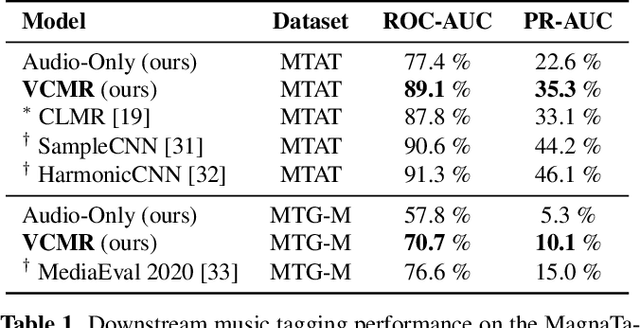
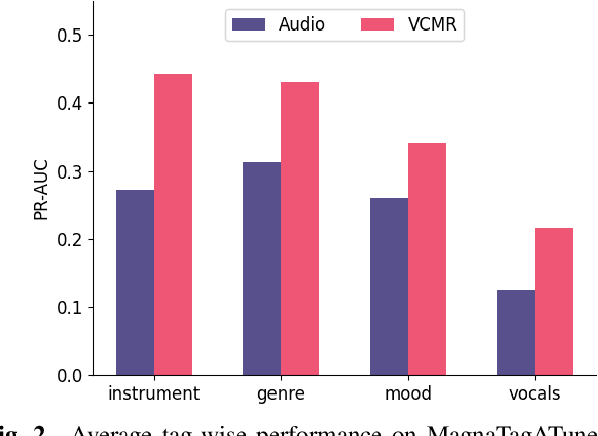
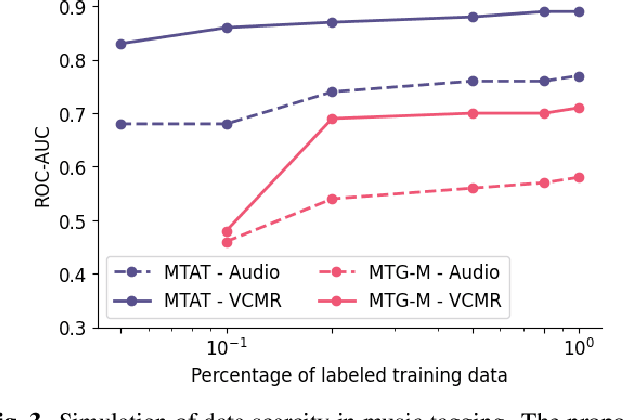
Human perception and experience of music is highly context-dependent. Contextual variability contributes to differences in how we interpret and interact with music, challenging the design of robust models for information retrieval. Incorporating multimodal context from diverse sources provides a promising approach toward modeling this variability. Music presented in media such as movies and music videos provide rich multimodal context that modulates underlying human experiences. However, such context modeling is underexplored, as it requires large amounts of multimodal data along with relevant annotations. Self-supervised learning can help address these challenges by automatically extracting rich, high-level correspondences between different modalities, hence alleviating the need for fine-grained annotations at scale. In this study, we propose VCMR -- Video-Conditioned Music Representations, a contrastive learning framework that learns music representations from audio and the accompanying music videos. The contextual visual information enhances representations of music audio, as evaluated on the downstream task of music tagging. Experimental results show that the proposed framework can contribute additive robustness to audio representations and indicates to what extent musical elements are affected or determined by visual context.