 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity Transfer of Functional Priors for Wide Bayesian Neural Networks by Learning Activations
Paper and Code
Oct 21, 2024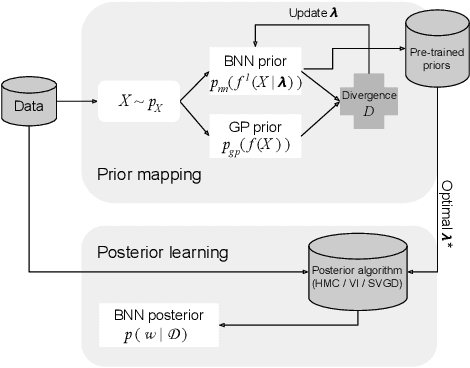



Function-space priors in Bayesian Neural Networks provide a more intuitive approach to embedding beliefs directly into the model's output, thereby enhancing regularization, uncertainty quantification, and risk-aware decision-making. However, imposing function-space priors on BNNs is challenging. We address this task through optimization techniques that explore how trainable activations can accommodate complex priors and match intricate target function distributions. We discuss critical learning challenges, including identifiability, loss construction, and symmetries that arise in this context. Furthermore, we enable evidence maximization to facilitate model selection by conditioning the functional priors on additional hyperparameters. Our empirical findings demonstrate that even BNNs with a single wide hidden layer, when equipped with these adaptive trainable activations and conditioning strategies, can effectively achieve high-fidelity function-space priors, providing a robust and flexible framework for enhancing Bayesian neural network performance.