 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Prompt Threats: Attacking Safety Alignment and Unlearning in Open-Source LLMs through the Embedding Space
Paper and Code
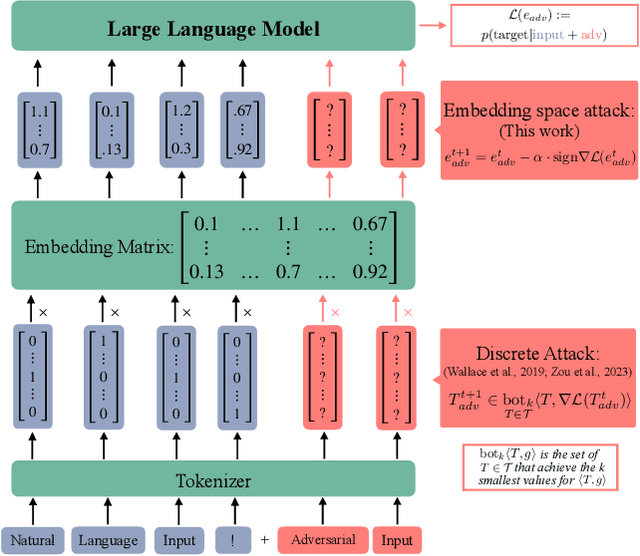
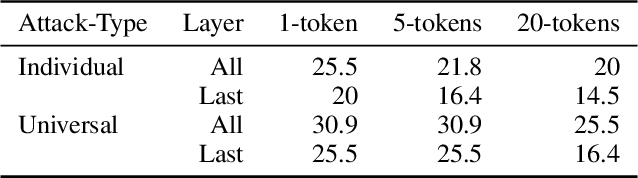

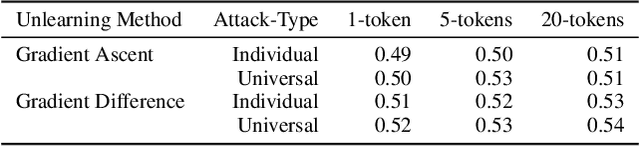
Current research in adversarial robustness of LLMs focuses on discrete input manipulations in the natural language space, which can be directly transferred to closed-source models. However, this approach neglects the steady progression of open-source models. As open-source models advance in capability, ensuring their safety also becomes increasingly imperative. Yet, attacks tailored to open-source LLMs that exploit full model access remain largely unexplored. We address this research gap and propose the embedding space attack, which directly attacks the continuous embedding representation of input tokens. We find that embedding space attacks circumvent model alignments and trigger harmful behaviors more efficiently than discrete attacks or model fine-tuning. Furthermore, we present a novel threat model in the context of unlearning and show that embedding space attacks can extract supposedly deleted information from unlearned LLMs across multiple datasets and models. Our findings highlight embedding space attacks as an important threat model in open-source LLMs. Trigger Warning: the appendix contains LLM-generated text with violence and harassment.