 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA low latency ASR-free end to end spoken language understanding system
Nov 10, 2020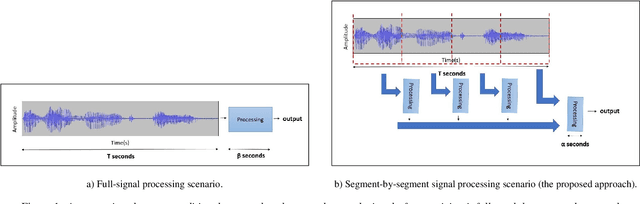
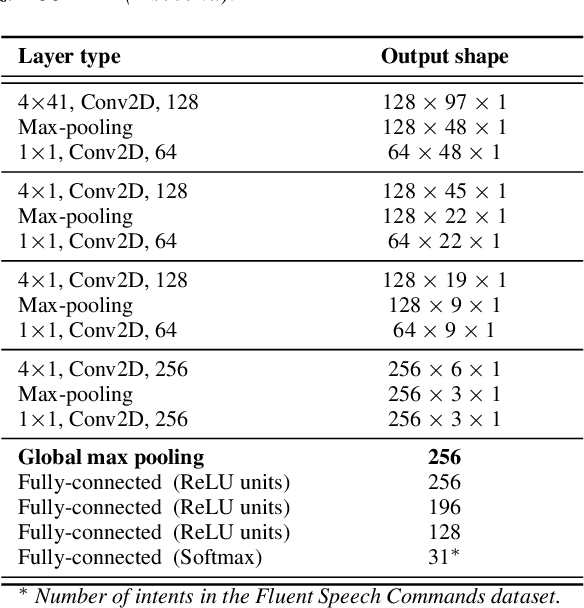
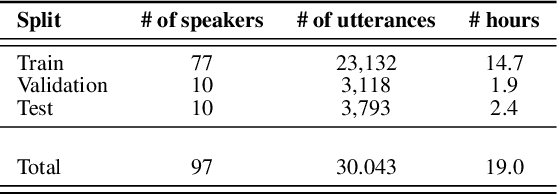
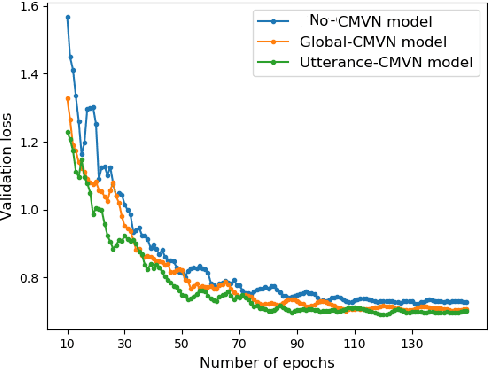
In recent years, developing a speech understanding system that classifies a waveform to structured data, such as intents and slots, without first transcribing the speech to text has emerged as an interesting research problem. This work proposes such as system with an additional constraint of designing a system that has a small enough footprint to run on small micro-controllers and embedded systems with minimal latency. Given a streaming input speech signal, the proposed system can process it segment-by-segment without the need to have the entire stream at the moment of processing. The proposed system is evaluated on the publicly available Fluent Speech Commands dataset. Experiments show that the proposed system yields state-of-the-art performance with the advantage of low latency and a much smaller model when compared to other published works on the same task.
DONUT: CTC-based Query-by-Example Keyword Spotting
Nov 26, 2018

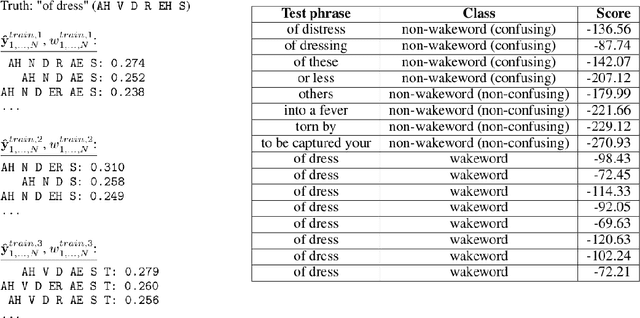
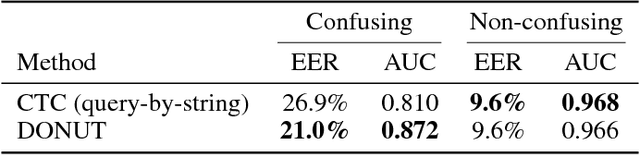
Keyword spotting--or wakeword detection--is an essential feature for hands-free operation of modern voice-controlled devices. With such devices becoming ubiquitous, users might want to choose a personalized custom wakeword. In this work, we present DONUT, a CTC-based algorithm for online query-by-example keyword spotting that enables custom wakeword detection. The algorithm works by recording a small number of training examples from the user, generating a set of label sequence hypotheses from these training examples, and detecting the wakeword by aggregating the scores of all the hypotheses given a new audio recording. Our method combines the generalization and interpretability of CTC-based keyword spotting with the user-adaptation and convenience of a conventional query-by-example system. DONUT has low computational requirements and is well-suited for both learning and inference on embedded systems without requiring private user data to be uploaded to the cloud.