 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA low latency ASR-free end to end spoken language understanding system
Nov 10, 2020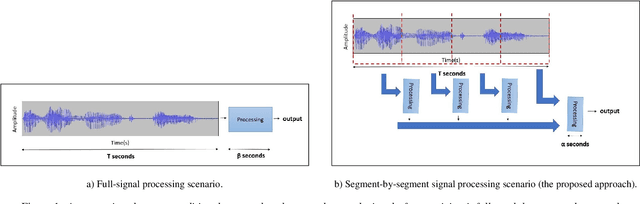
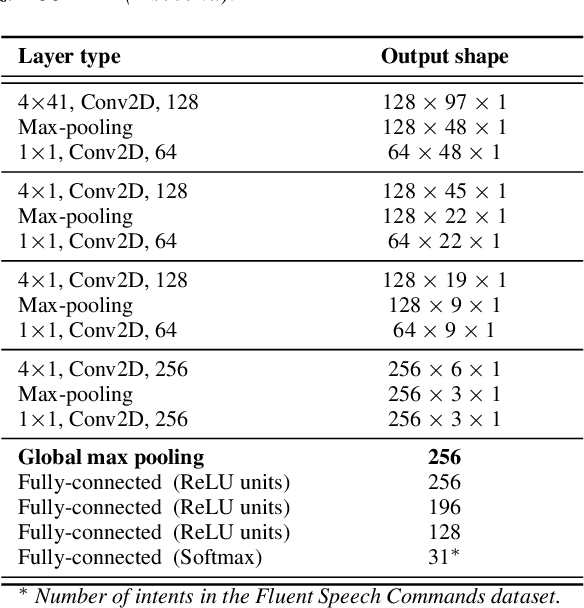
In recent years, developing a speech understanding system that classifies a waveform to structured data, such as intents and slots, without first transcribing the speech to text has emerged as an interesting research problem. This work proposes such as system with an additional constraint of designing a system that has a small enough footprint to run on small micro-controllers and embedded systems with minimal latency. Given a streaming input speech signal, the proposed system can process it segment-by-segment without the need to have the entire stream at the moment of processing. The proposed system is evaluated on the publicly available Fluent Speech Commands dataset. Experiments show that the proposed system yields state-of-the-art performance with the advantage of low latency and a much smaller model when compared to other published works on the same task.
Speech Model Pre-training for End-to-End Spoken Language Understanding
Apr 07, 2019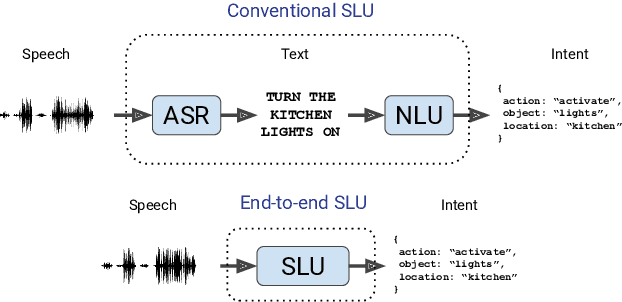
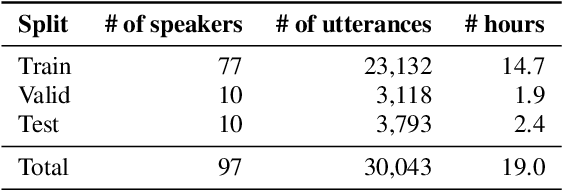
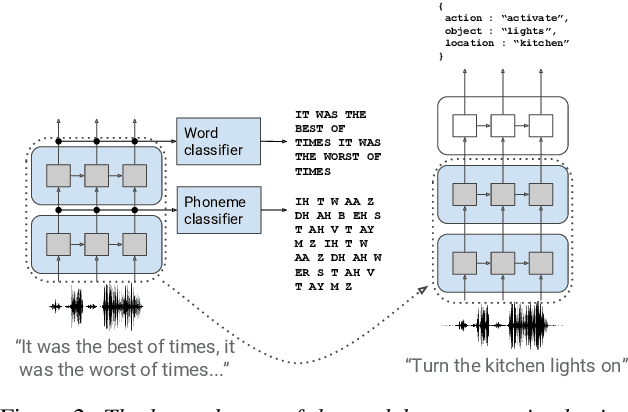
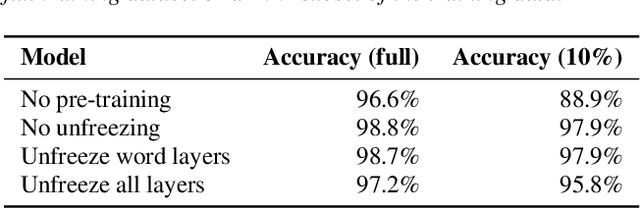
Whereas conventional spoken language understanding (SLU) systems map speech to text, and then text to intent, end-to-end SLU systems map speech directly to intent through a single trainable model. Achieving high accuracy with these end-to-end models without a large amount of training data is difficult. We propose a method to reduce the data requirements of end-to-end SLU in which the model is first pre-trained to predict words and phonemes, thus learning good features for SLU. We introduce a new SLU dataset, Fluent Speech Commands, and show that our method improves performance both when the full dataset is used for training and when only a small subset is used. We also describe preliminary experiments to gauge the model's ability to generalize to new phrases not heard during training.
DONUT: CTC-based Query-by-Example Keyword Spotting
Nov 26, 2018

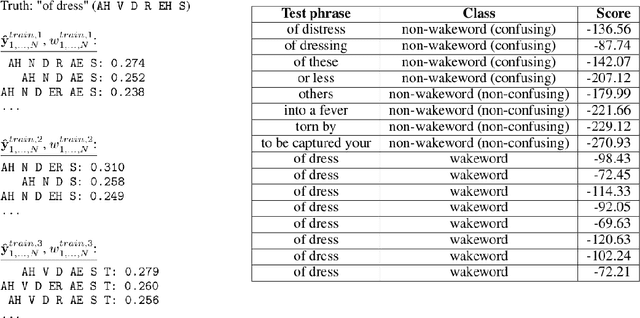
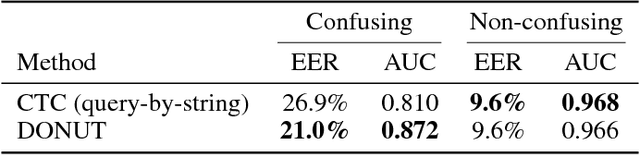
Keyword spotting--or wakeword detection--is an essential feature for hands-free operation of modern voice-controlled devices. With such devices becoming ubiquitous, users might want to choose a personalized custom wakeword. In this work, we present DONUT, a CTC-based algorithm for online query-by-example keyword spotting that enables custom wakeword detection. The algorithm works by recording a small number of training examples from the user, generating a set of label sequence hypotheses from these training examples, and detecting the wakeword by aggregating the scores of all the hypotheses given a new audio recording. Our method combines the generalization and interpretability of CTC-based keyword spotting with the user-adaptation and convenience of a conventional query-by-example system. DONUT has low computational requirements and is well-suited for both learning and inference on embedded systems without requiring private user data to be uploaded to the cloud.
Graph based manifold regularized deep neural networks for automatic speech recognition
Jun 19, 2016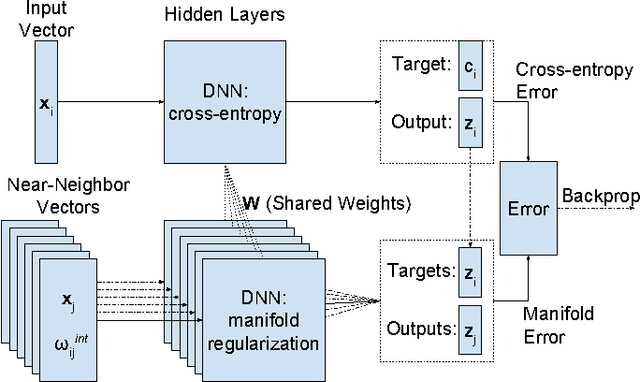
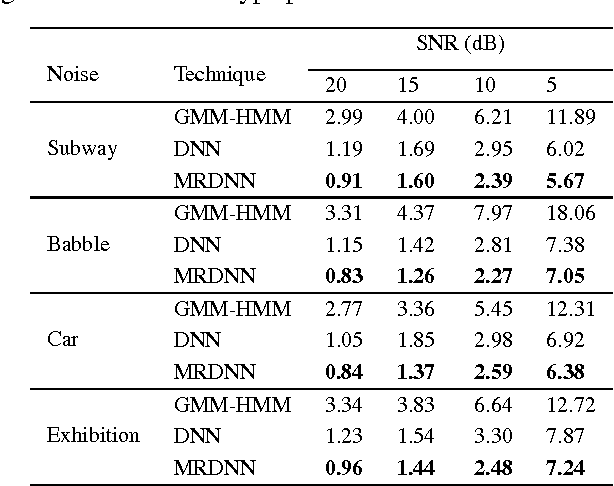
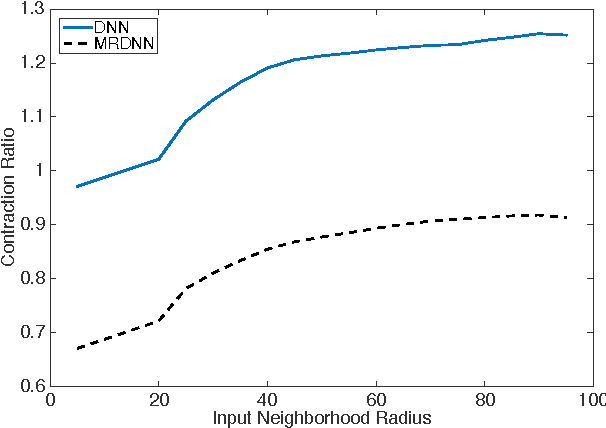
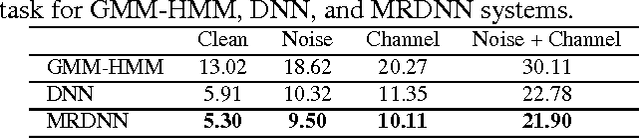
Deep neural networks (DNNs) have been successfully applied to a wide variety of acoustic modeling tasks in recent years. These include the applications of DNNs either in a discriminative feature extraction or in a hybrid acoustic modeling scenario. Despite the rapid progress in this area, a number of challenges remain in training DNNs. This paper presents an effective way of training DNNs using a manifold learning based regularization framework. In this framework, the parameters of the network are optimized to preserve underlying manifold based relationships between speech feature vectors while minimizing a measure of loss between network outputs and targets. This is achieved by incorporating manifold based locality constraints in the objective criterion of DNNs. Empirical evidence is provided to demonstrate that training a network with manifold constraints preserves structural compactness in the hidden layers of the network. Manifold regularization is applied to train bottleneck DNNs for feature extraction in hidden Markov model (HMM) based speech recognition. The experiments in this work are conducted on the Aurora-2 spoken digits and the Aurora-4 read news large vocabulary continuous speech recognition tasks. The performance is measured in terms of word error rate (WER) on these tasks. It is shown that the manifold regularized DNNs result in up to 37% reduction in WER relative to standard DNNs.