 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA low latency ASR-free end to end spoken language understanding system
Nov 10, 2020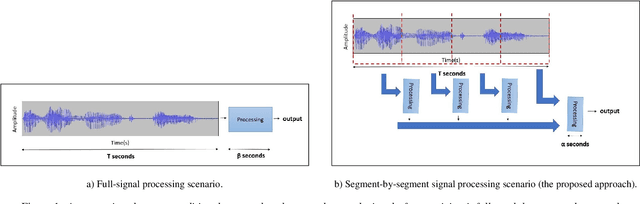
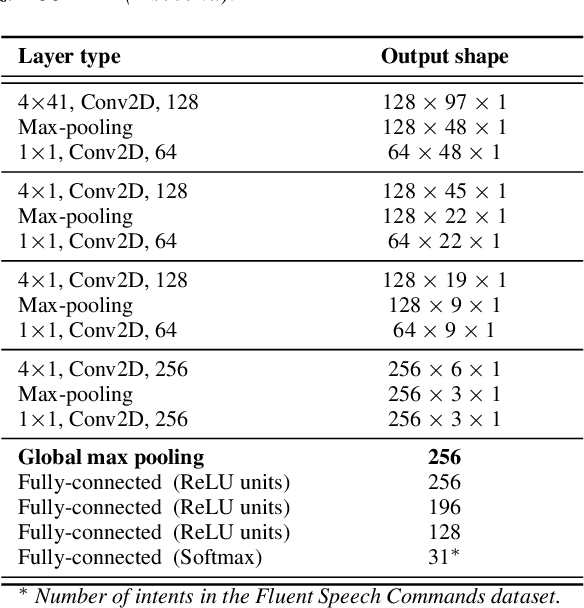
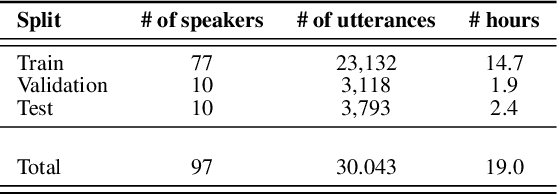
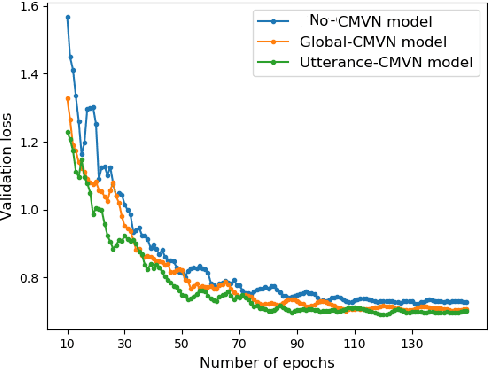
In recent years, developing a speech understanding system that classifies a waveform to structured data, such as intents and slots, without first transcribing the speech to text has emerged as an interesting research problem. This work proposes such as system with an additional constraint of designing a system that has a small enough footprint to run on small micro-controllers and embedded systems with minimal latency. Given a streaming input speech signal, the proposed system can process it segment-by-segment without the need to have the entire stream at the moment of processing. The proposed system is evaluated on the publicly available Fluent Speech Commands dataset. Experiments show that the proposed system yields state-of-the-art performance with the advantage of low latency and a much smaller model when compared to other published works on the same task.
Unsupervised image segmentation by Global and local Criteria Optimization Based on Bayesian Networks
Jan 22, 2015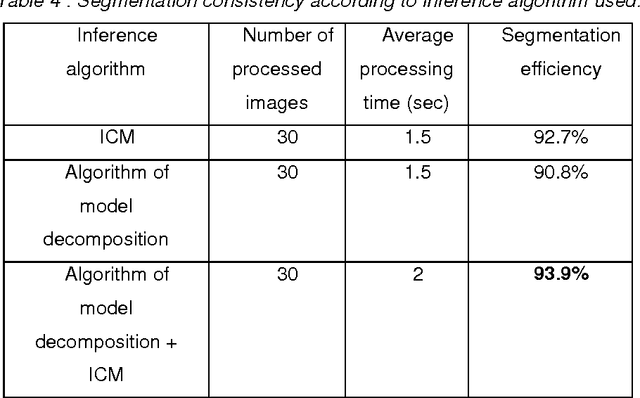
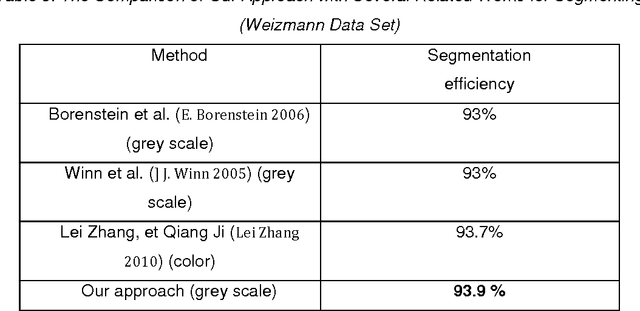
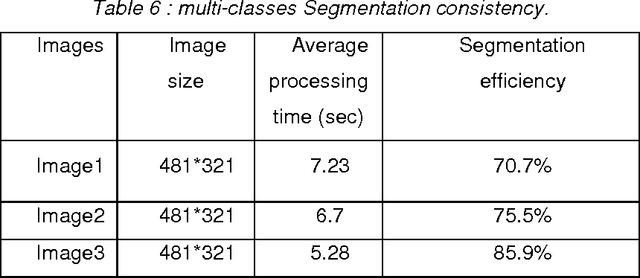

Today Bayesian networks are more used in many areas of decision support and image processing. In this way, our proposed approach uses Bayesian Network to modelize the segmented image quality. This quality is calculated on a set of attributes that represent local evaluation measures. The idea is to have these local levels chosen in a way to be intersected into them to keep the overall appearance of segmentation. The approach operates in two phases: the first phase is to make an over-segmentation which gives superpixels card. In the second phase, we model the superpixels by a Bayesian Network. To find the segmented image with the best overall quality we used two approximate inference methods, the first using ICM algorithm which is widely used in Markov Models and a second is a recursive method called algorithm of model decomposition based on max-product algorithm which is very popular in the recent works of image segmentation. For our model, we have shown that the composition of these two algorithms leads to good segmentation performance.