 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Variational Inference over Nonlinear Channels
Sep 21, 2023Deep learning methods for communications over unknown nonlinear channels have attracted considerable interest recently. In this paper, we consider semi-supervised learning methods, which are based on variational inference, for decoding unknown nonlinear channels. These methods, which include Monte Carlo expectation maximization and a variational autoencoder, make efficient use of few pilot symbols and the payload data. The best semi-supervised learning results are achieved with a variational autoencoder. For sufficiently many payload symbols, the variational autoencoder also has lower error rate compared to meta learning that uses the pilot data of the present as well as previous transmission blocks.
Unsupervised Linear and Nonlinear Channel Equalization and Decoding using Variational Autoencoders
May 21, 2019
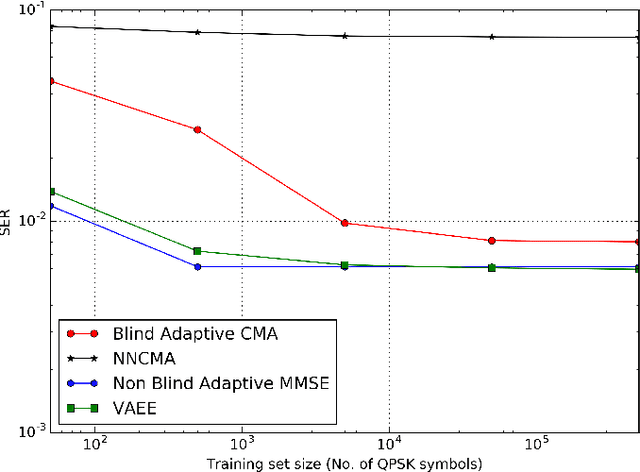
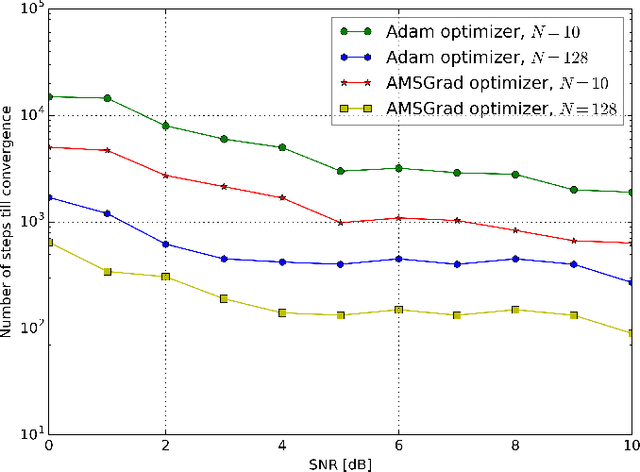
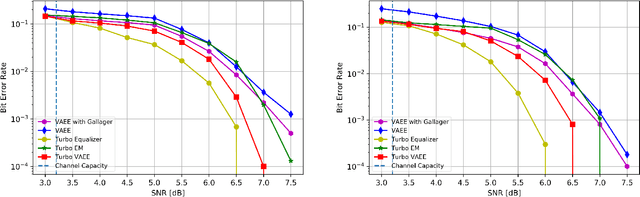
A new approach for blind channel equalization and decoding, using variational autoencoders (VAEs), is introduced. We first consider the reconstruction of uncoded data symbols transmitted over a noisy linear intersymbol interference (ISI) channel, with an unknown impulse response, without using pilot symbols. We derive an approximated maximum likelihood estimate to the channel parameters and reconstruct the transmitted data. We demonstrate significant and consistent improvements in the error rate of the reconstructed symbols, compared to existing blind equalization methods such as constant modulus, thus enabling faster channel acquisition. The VAE equalizer uses a fully convolutional neural network with a small number of free parameters. These results are extended to blind equalization over a noisy nonlinear ISI channel with unknown parameters. We then consider coded communication using low-density parity-check (LDPC) codes transmitted over a noisy linear or nonlinear ISI channel. The goal is to reconstruct the transmitted message from the channel observations corresponding to a transmitted codeword, without using pilot symbols. We demonstrate substantial improvements compared to expectation maximization (EM) using turbo equalization. Furthermore, in our simulations we demonstrate a relatively small gap between the performance of the new unsupervised equalization method and that of the fully channel informed (non-blind) turbo equalizer.
Blind Channel Equalization using Variational Autoencoders
Mar 05, 2018

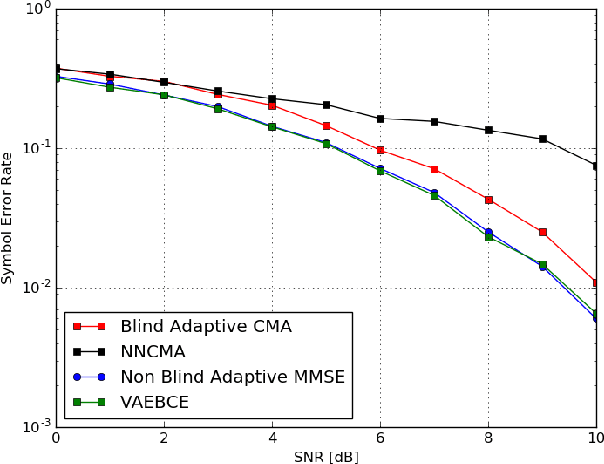

A new maximum likelihood estimation approach for blind channel equalization, using variational autoencoders (VAEs), is introduced. Significant and consistent improvements in the error rate of the reconstructed symbols, compared to constant modulus equalizers, are demonstrated. In fact, for the channels that were examined, the performance of the new VAE blind channel equalizer was close to the performance of a nonblind adaptive linear minimum mean square error equalizer. The new equalization method enables a significantly lower latency channel acquisition compared to the constant modulus algorithm (CMA). The VAE uses a convolutional neural network with two layers and a very small number of free parameters. Although the computational complexity of the new equalizer is higher compared to CMA, it is still reasonable, and the number of free parameters to estimate is small.
Near Maximum Likelihood Decoding with Deep Learning
Jan 08, 2018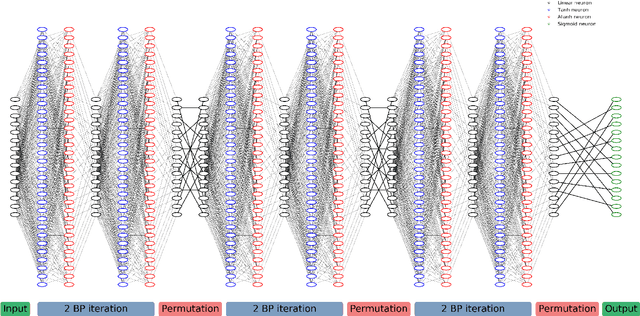
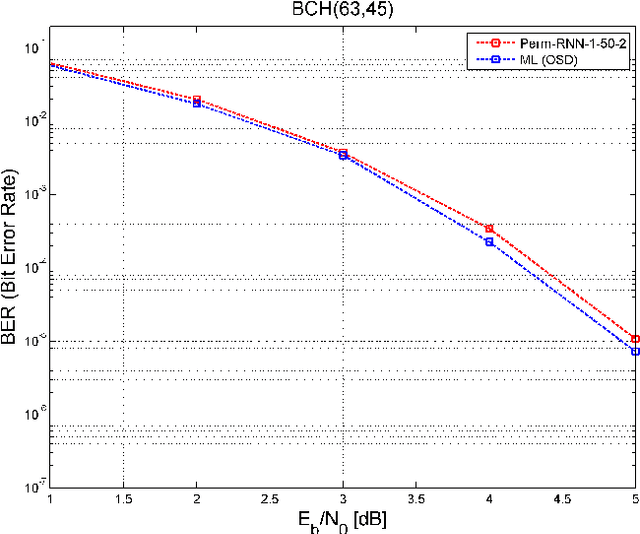
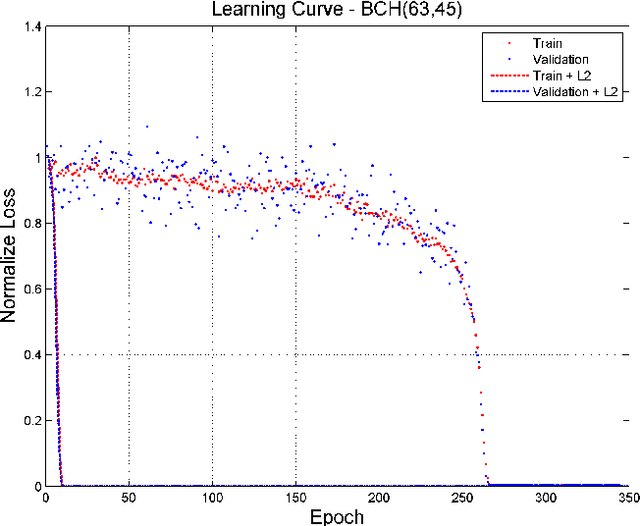
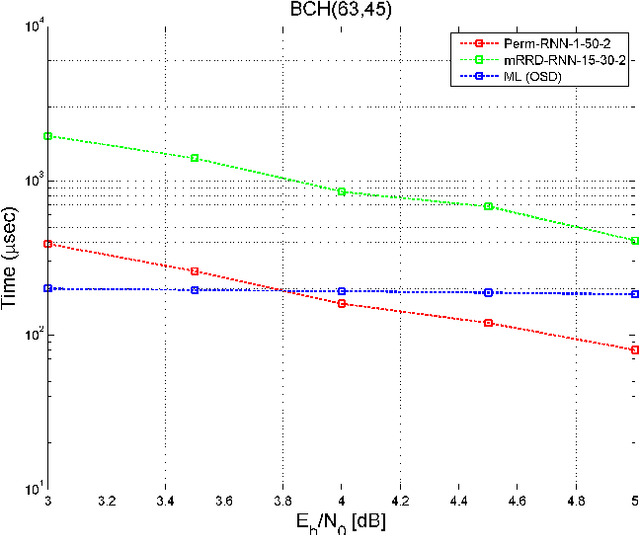
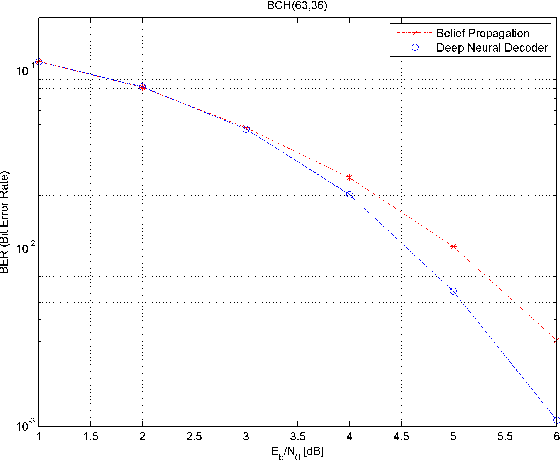
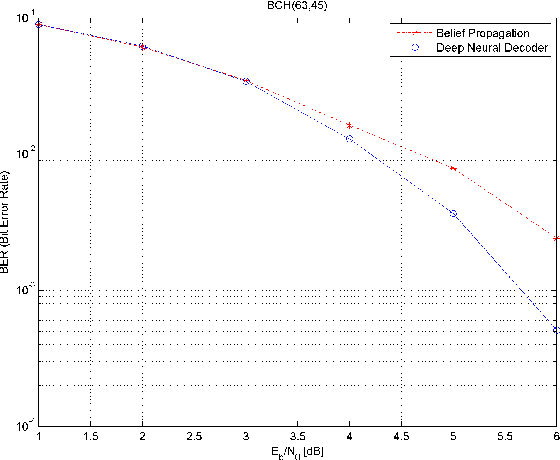
A novel and efficient neural decoder algorithm is proposed. The proposed decoder is based on the neural Belief Propagation algorithm and the Automorphism Group. By combining neural belief propagation with permutations from the Automorphism Group we achieve near maximum likelihood performance for High Density Parity Check codes. Moreover, the proposed decoder significantly improves the decoding complexity, compared to our earlier work on the topic. We also investigate the training process and show how it can be accelerated. Simulations of the hessian and the condition number show why the learning process is accelerated. We demonstrate the decoding algorithm for various linear block codes of length up to 63 bits.
Deep Learning Methods for Improved Decoding of Linear Codes
Jan 01, 2018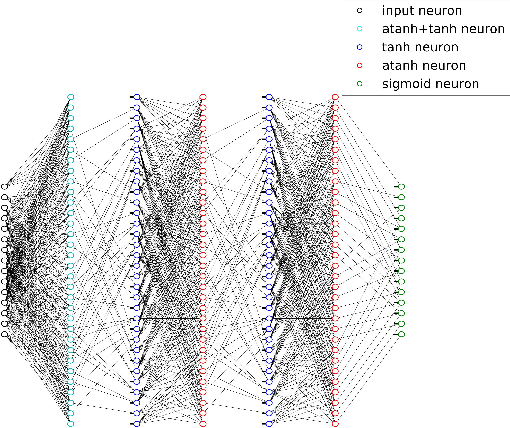
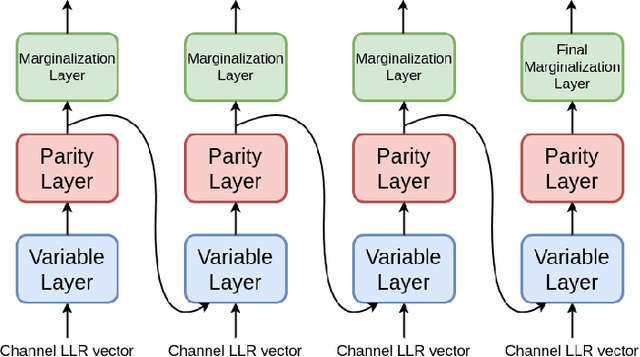
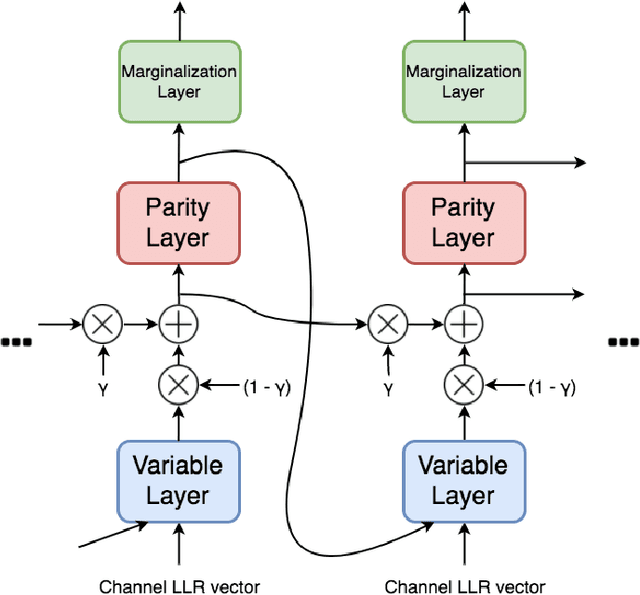
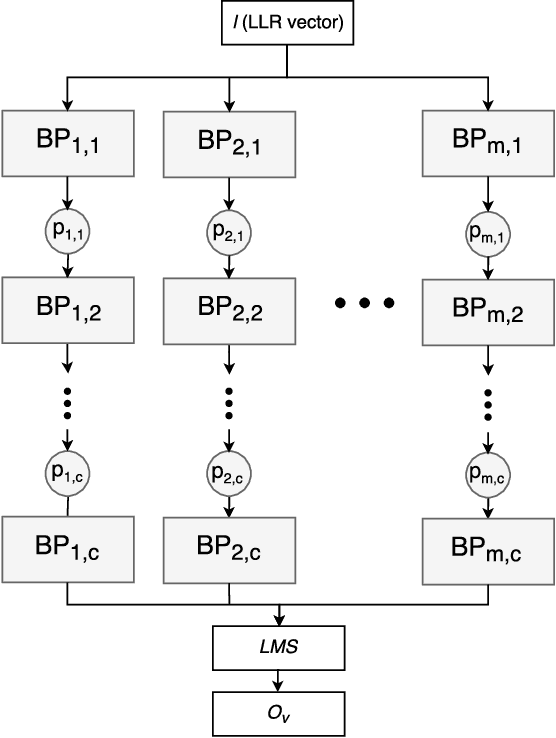
The problem of low complexity, close to optimal, channel decoding of linear codes with short to moderate block length is considered. It is shown that deep learning methods can be used to improve a standard belief propagation decoder, despite the large example space. Similar improvements are obtained for the min-sum algorithm. It is also shown that tying the parameters of the decoders across iterations, so as to form a recurrent neural network architecture, can be implemented with comparable results. The advantage is that significantly less parameters are required. We also introduce a recurrent neural decoder architecture based on the method of successive relaxation. Improvements over standard belief propagation are also observed on sparser Tanner graph representations of the codes. Furthermore, we demonstrate that the neural belief propagation decoder can be used to improve the performance, or alternatively reduce the computational complexity, of a close to optimal decoder of short BCH codes.
Simplified End-to-End MMI Training and Voting for ASR
Jul 16, 2017
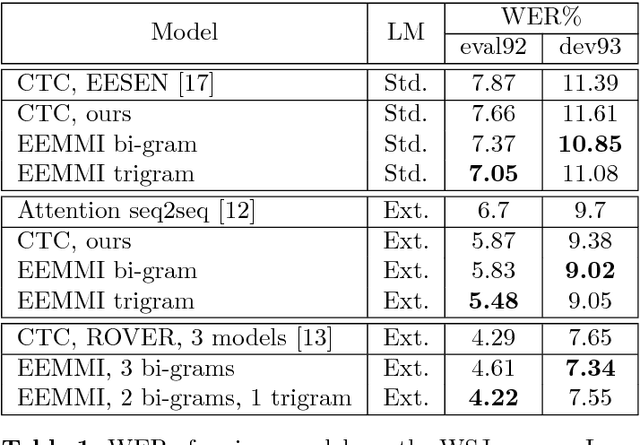


A simplified speech recognition system that uses the maximum mutual information (MMI) criterion is considered. End-to-end training using gradient descent is suggested, similarly to the training of connectionist temporal classification (CTC). We use an MMI criterion with a simple language model in the training stage, and a standard HMM decoder. Our method compares favorably to CTC in terms of performance, robustness, decoding time, disk footprint and quality of alignments. The good alignments enable the use of a straightforward ensemble method, obtained by simply averaging the predictions of several neural network models, that were trained separately end-to-end. The ensemble method yields a considerable reduction in the word error rate.
RNN Decoding of Linear Block Codes
Feb 24, 2017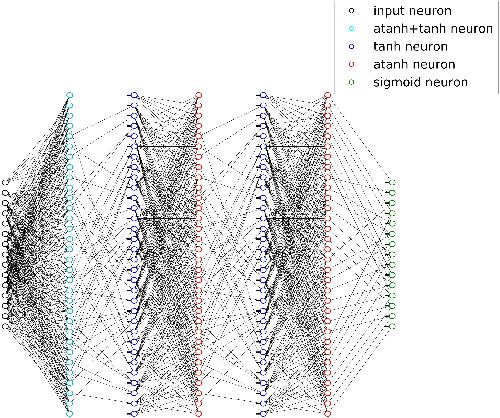


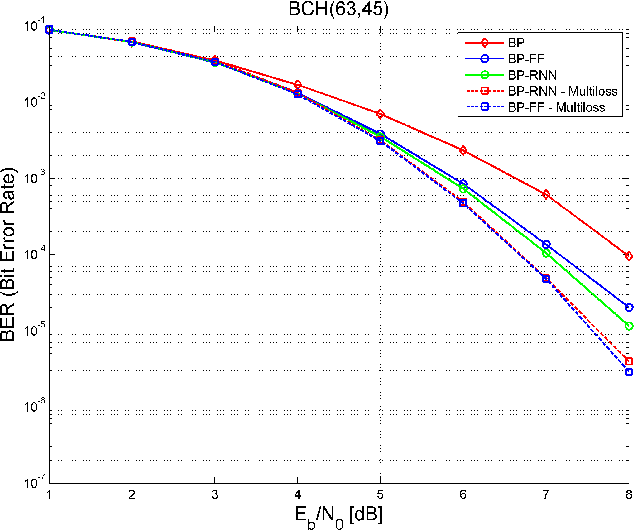
Designing a practical, low complexity, close to optimal, channel decoder for powerful algebraic codes with short to moderate block length is an open research problem. Recently it has been shown that a feed-forward neural network architecture can improve on standard belief propagation decoding, despite the large example space. In this paper we introduce a recurrent neural network architecture for decoding linear block codes. Our method shows comparable bit error rate results compared to the feed-forward neural network with significantly less parameters. We also demonstrate improved performance over belief propagation on sparser Tanner graph representations of the codes. Furthermore, we demonstrate that the RNN decoder can be used to improve the performance or alternatively reduce the computational complexity of the mRRD algorithm for low complexity, close to optimal, decoding of short BCH codes.
Learning to Decode Linear Codes Using Deep Learning
Sep 30, 2016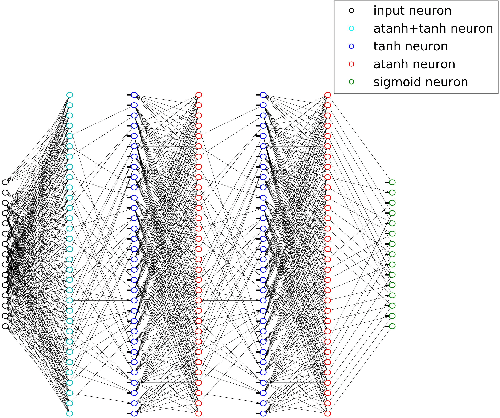
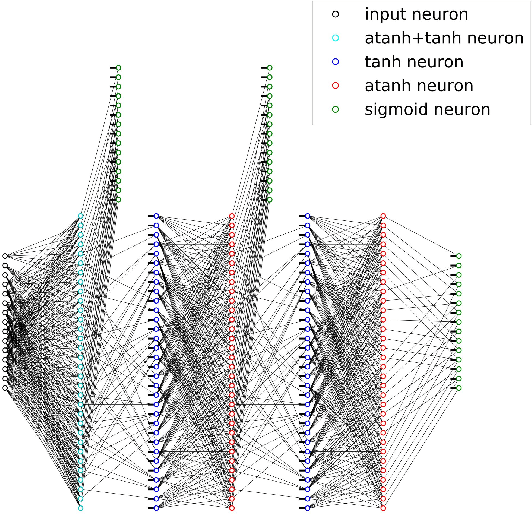
A novel deep learning method for improving the belief propagation algorithm is proposed. The method generalizes the standard belief propagation algorithm by assigning weights to the edges of the Tanner graph. These edges are then trained using deep learning techniques. A well-known property of the belief propagation algorithm is the independence of the performance on the transmitted codeword. A crucial property of our new method is that our decoder preserved this property. Furthermore, this property allows us to learn only a single codeword instead of exponential number of code-words. Improvements over the belief propagation algorithm are demonstrated for various high density parity check codes.