 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending LLMs to New Languages: A Case Study of Llama and Persian Adaptation
Dec 17, 2024Large language models (LLMs) have made great progress in classification and text generation tasks. However, they are mainly trained on English data and often struggle with low-resource languages. In this study, we explore adding a new language, i.e., Persian, to Llama (a model with a limited understanding of Persian) using parameter-efficient fine-tuning. We employ a multi-stage approach involving pretraining on monolingual Persian data, aligning representations through bilingual pretraining and instruction datasets, and instruction-tuning with task-specific datasets. We evaluate the model's performance at each stage on generation and classification tasks. Our findings suggest that incorporating the Persian language, through bilingual data alignment, can enhance classification accuracy for Persian tasks, with no adverse impact and sometimes even improvements on English tasks. Additionally, the results highlight the model's initial strength as a critical factor when working with limited training data, with cross-lingual alignment offering minimal benefits for the low-resource language. Knowledge transfer from English to Persian has a marginal effect, primarily benefiting simple classification tasks.
Robust Model Evaluation over Large-scale Federated Networks
Oct 26, 2024
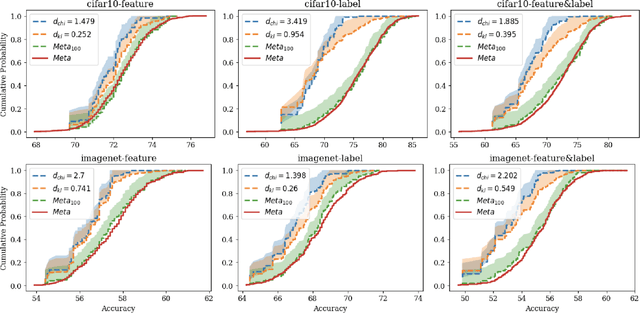

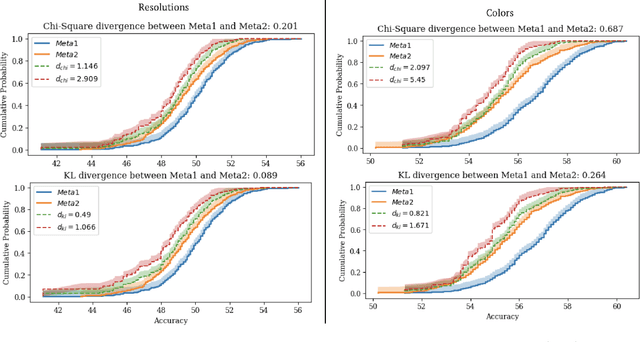
In this paper, we address the challenge of certifying the performance of a machine learning model on an unseen target network, using measurements from an available source network. We focus on a scenario where heterogeneous datasets are distributed across a source network of clients, all connected to a central server. Specifically, consider a source network "A" composed of $K$ clients, each holding private data from unique and heterogeneous distributions, which are assumed to be independent samples from a broader meta-distribution $\mu$. Our goal is to provide certified guarantees for the model's performance on a different, unseen target network "B," governed by another meta-distribution $\mu'$, assuming the deviation between $\mu$ and $\mu'$ is bounded by either the Wasserstein distance or an $f$-divergence. We derive theoretical guarantees for the model's empirical average loss and provide uniform bounds on the risk CDF, where the latter correspond to novel and adversarially robust versions of the Glivenko-Cantelli theorem and the Dvoretzky-Kiefer-Wolfowitz (DKW) inequality. Our bounds are computable in polynomial time with a polynomial number of queries to the $K$ clients, preserving client privacy by querying only the model's (potentially adversarial) loss on private data. We also establish non-asymptotic generalization bounds that consistently converge to zero as both $K$ and the minimum client sample size grow. Extensive empirical evaluations validate the robustness and practicality of our bounds across real-world tasks.
Comparative Study of Multilingual Idioms and Similes in Large Language Models
Oct 21, 2024



This study addresses the gap in the literature concerning the comparative performance of LLMs in interpreting different types of figurative language across multiple languages. By evaluating LLMs using two multilingual datasets on simile and idiom interpretation, we explore the effectiveness of various prompt engineering strategies, including chain-of-thought, few-shot, and English translation prompts. We extend the language of these datasets to Persian as well by building two new evaluation sets. Our comprehensive assessment involves both closed-source (GPT-3.5, GPT-4o mini, Gemini 1.5), and open-source models (Llama 3.1, Qwen2), highlighting significant differences in performance across languages and figurative types. Our findings reveal that while prompt engineering methods are generally effective, their success varies by figurative type, language, and model. We also observe that open-source models struggle particularly with low-resource languages in similes. Additionally, idiom interpretation is nearing saturation for many languages, necessitating more challenging evaluations.
Benchmarking Large Language Models for Persian: A Preliminary Study Focusing on ChatGPT
Apr 03, 2024



This paper explores the efficacy of large language models (LLMs) for Persian. While ChatGPT and consequent LLMs have shown remarkable performance in English, their efficiency for more low-resource languages remains an open question. We present the first comprehensive benchmarking study of LLMs across diverse Persian language tasks. Our primary focus is on GPT-3.5-turbo, but we also include GPT-4 and OpenChat-3.5 to provide a more holistic evaluation. Our assessment encompasses a diverse set of tasks categorized into classic, reasoning, and knowledge-based domains. To enable a thorough comparison, we evaluate LLMs against existing task-specific fine-tuned models. Given the limited availability of Persian datasets for reasoning tasks, we introduce two new benchmarks: one based on elementary school math questions and another derived from the entrance exams for 7th and 10th grades. Our findings reveal that while LLMs, especially GPT-4, excel in tasks requiring reasoning abilities and a broad understanding of general knowledge, they often lag behind smaller pre-trained models fine-tuned specifically for particular tasks. Additionally, we observe improved performance when test sets are translated to English before inputting them into GPT-3.5. These results highlight the significant potential for enhancing LLM performance in the Persian language. This is particularly noteworthy due to the unique attributes of Persian, including its distinct alphabet and writing styles.