Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat is Multimodality?
Paper and Code
Mar 10, 2021
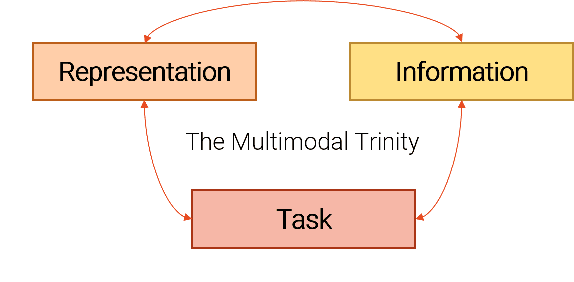
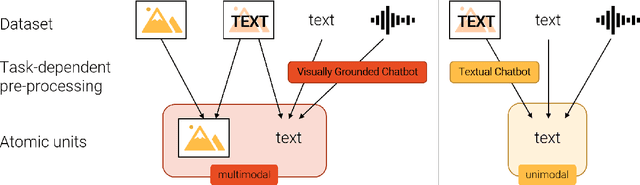
The last years have shown rapid developments in the field of multimodal machine learning, combining e.g., vision, text or speech. In this position paper we explain how the field uses outdated definitions of multimodality that prove unfit for the machine learning era. We propose a new task-relative definition of (multi)modality in the context of multimodal machine learning that focuses on representations and information that are relevant for a given machine learning task. With our new definition of multimodality we aim to provide a missing foundation for multimodal research, an important component of language grounding and a crucial milestone towards NLU.
* 9 pages, 3 figures
View paper on