 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Vision & Language Decoders use Images and Text equally? How Self-consistent are their Explanations?
Paper and Code
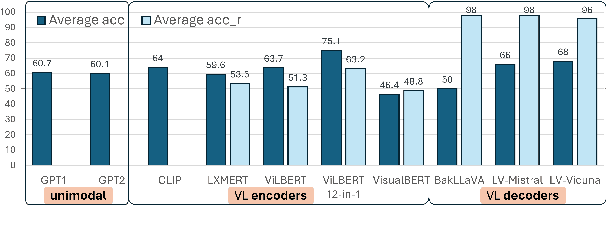
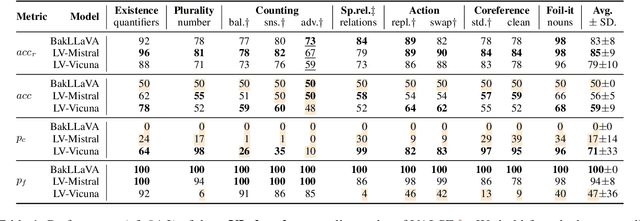
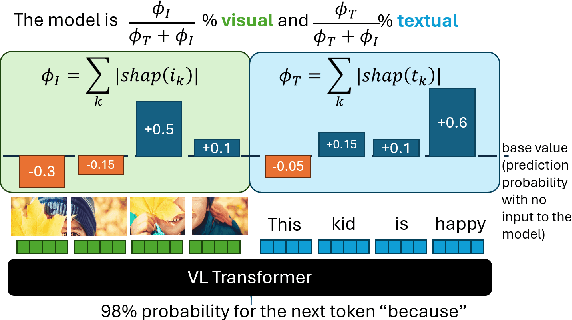
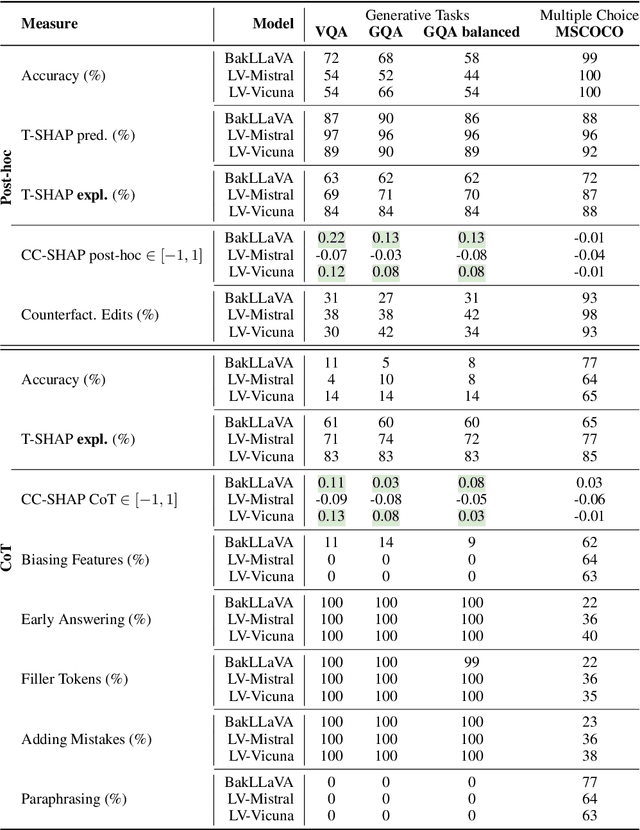
Vision and language models (VLMs) are currently the most generally performant architectures on multimodal tasks. Next to their predictions, they can also produce explanations, either in post-hoc or CoT settings. However, it is not clear how much they use the vision and text modalities when generating predictions or explanations. In this work, we investigate if VLMs rely on modalities differently when generating explanations as opposed to when they provide answers. We also evaluate the self-consistency of VLM decoders in both post-hoc and CoT explanation settings, by extending existing tests and measures to VLM decoders. We find that VLMs are less self-consistent than LLMs. The text contributions in VL decoders are much larger than the image contributions across all measured tasks. And the contributions of the image are significantly larger for explanation generations than for answer generation. This difference is even larger in CoT compared to the post-hoc explanation setting. We also provide an up-to-date benchmarking of state-of-the-art VL decoders on the VALSE benchmark, which to date focused only on VL encoders. We find that VL decoders are still struggling with most phenomena tested by VALSE.