 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-SHAP: A Performance-agnostic Metric for Measuring Multimodal Contributions in Vision and Language Models & Tasks
Paper and Code

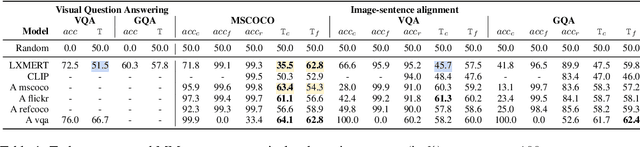
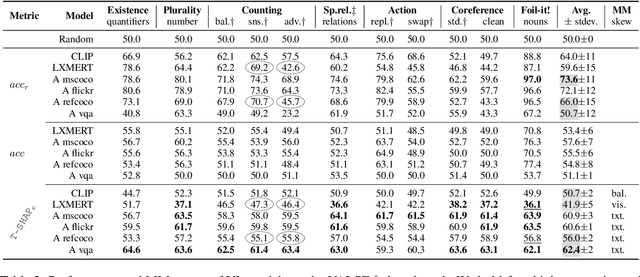
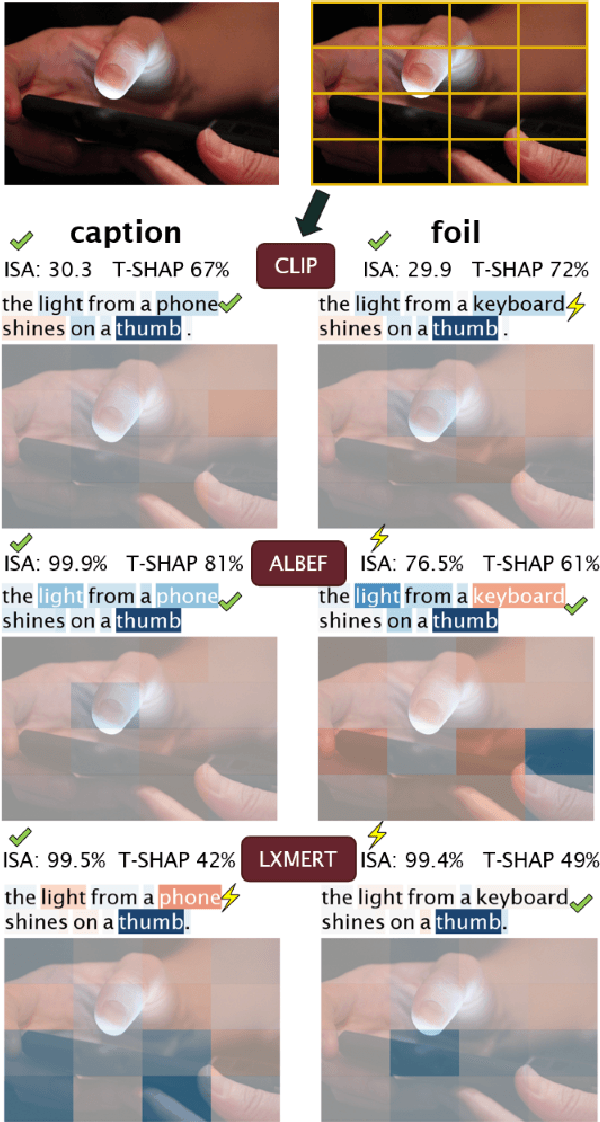
Vision and language models (VL) are known to exploit unrobust indicators in individual modalities (e.g., introduced by distributional biases), instead of focusing on relevant information in each modality. A small drop in accuracy obtained on a VL task with a unimodal model suggests that so-called unimodal collapse occurred. But how to quantify the amount of unimodal collapse reliably, at dataset and instance-level, to diagnose and combat unimodal collapse in a targeted way? We present MM-SHAP, a performance-agnostic multimodality score that quantifies the proportion by which a model uses individual modalities in multimodal tasks. MM-SHAP is based on Shapley values and will be applied in two ways: (1) to compare models for their degree of multimodality, and (2) to measure the contribution of individual modalities for a given task and dataset. Experiments with 6 VL models -- LXMERT, CLIP and four ALBEF variants -- on four VL tasks highlight that unimodal collapse can occur to different degrees and in different directions, contradicting the wide-spread assumption that unimodal collapse is one-sided. We recommend MM-SHAP for analysing multimodal tasks, to diagnose and guide progress towards multimodal integration. Code available at: https://github.com/Heidelberg-NLP/MM-SHAP