 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Language Models
Jan 13, 2024


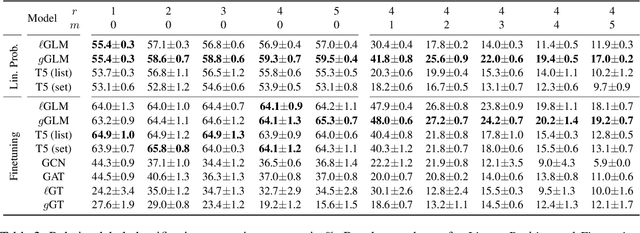
While Language Models have become workhorses for NLP, their interplay with textual knowledge graphs (KGs) - structured memories of general or domain knowledge - is actively researched. Current embedding methodologies for such graphs typically either (i) linearize graphs for embedding them using sequential Language Models (LMs), which underutilize structural information, or (ii) use Graph Neural Networks (GNNs) to preserve graph structure, while GNNs cannot represent textual features as well as a pre-trained LM could. In this work we introduce a novel language model, the Graph Language Model (GLM), that integrates the strengths of both approaches, while mitigating their weaknesses. The GLM parameters are initialized from a pretrained LM, to facilitate nuanced understanding of individual concepts and triplets. Simultaneously, its architectural design incorporates graph biases, thereby promoting effective knowledge distribution within the graph. Empirical evaluations on relation classification tasks on ConceptNet subgraphs reveal that GLM embeddings surpass both LM- and GNN-based baselines in supervised and zero-shot settings.
Similarity-weighted Construction of Contextualized Commonsense Knowledge Graphs for Knowledge-intense Argumentation Tasks
May 15, 2023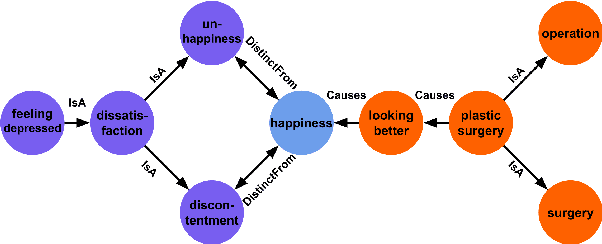
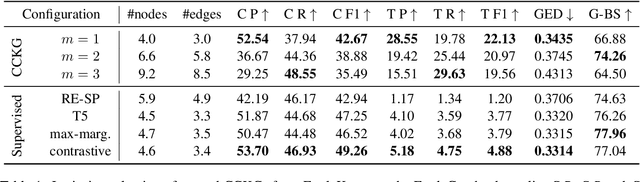
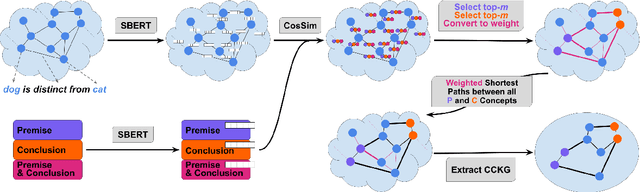
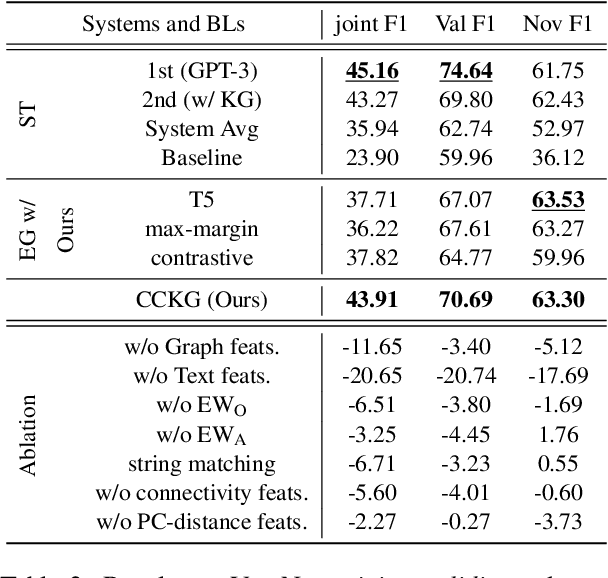
Arguments often do not make explicit how a conclusion follows from its premises. To compensate for this lack, we enrich arguments with structured background knowledge to support knowledge-intense argumentation tasks. We present a new unsupervised method for constructing Contextualized Commonsense Knowledge Graphs (CCKGs) that selects contextually relevant knowledge from large knowledge graphs (KGs) efficiently and at high quality. Our work goes beyond context-insensitive knowledge extraction heuristics by computing semantic similarity between KG triplets and textual arguments. Using these triplet similarities as weights, we extract contextualized knowledge paths that connect a conclusion to its premise, while maximizing similarity to the argument. We combine multiple paths into a CCKG that we optionally prune to reduce noise and raise precision. Intrinsic evaluation of the quality of our graphs shows that our method is effective for (re)constructing human explanation graphs. Manual evaluations in a large-scale knowledge selection setup confirm high recall and precision of implicit CSK in the CCKGs. Finally, we demonstrate the effectiveness of CCKGs in a knowledge-insensitive argument quality rating task, outperforming strong baselines and rivaling a GPT-3 based system.