 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Invalsi Benchmark: measuring Language Models Mathematical and Language understanding in Italian
Paper and Code
Mar 27, 2024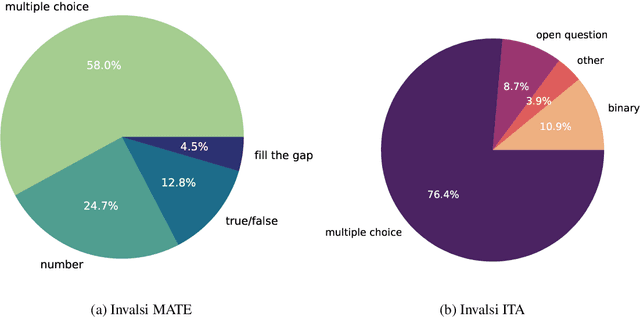
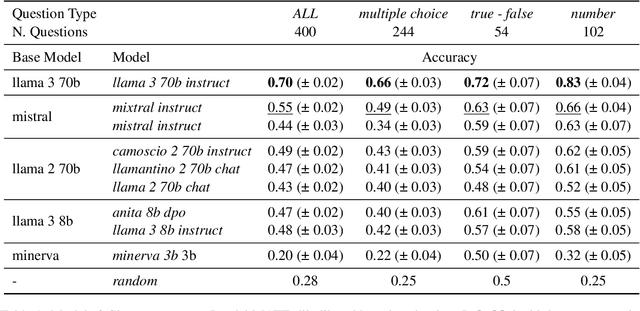
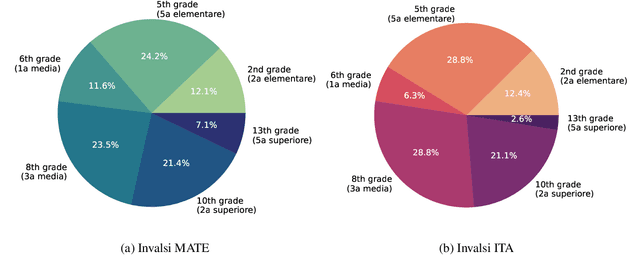
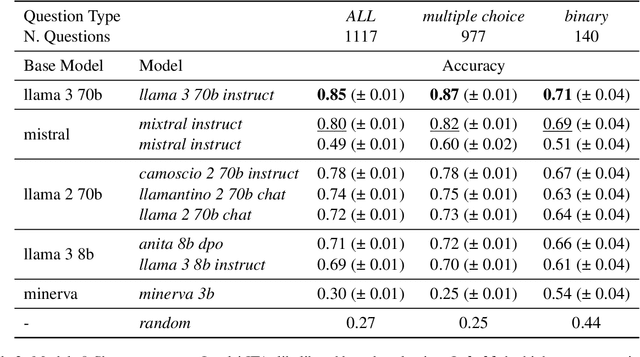
While Italian is by all metrics a high resource language, currently, there are isn't a Language Model pre-trained exclusively in this language. This results in a lower number of available benchmarks to evaluate the performance of language models in Italian. This work presents two new benchmarks to evaluate the models performance on mathematical understanding and language understanding in Italian. These benchmarks are based on real tests that are undertaken by students of age between 11 and 18 within the Italian school system and have therefore been validated by several experts in didactics and pedagogy. To validate this dataset we evaluate the performance of 9 language models that are the best performing when writing in Italian, including our own fine-tuned models. We show that this is a challenging benchmark where current language models are bound by 60\% accuracy. We believe that the release of this dataset paves the way for improving future models mathematical and language understanding in Italian.