 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOutliers Dimensions that Disrupt Transformers Are Driven by Frequency
Paper and Code
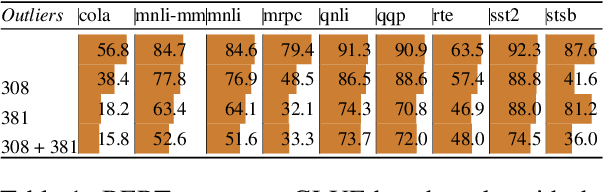
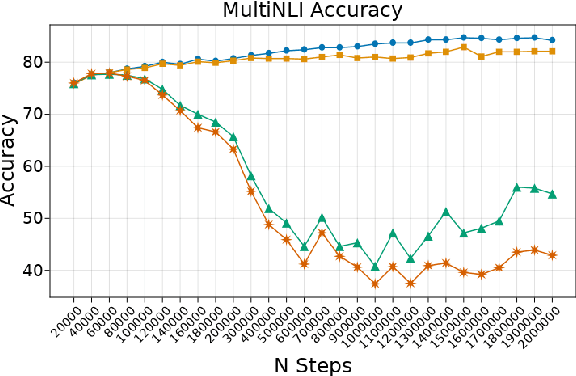
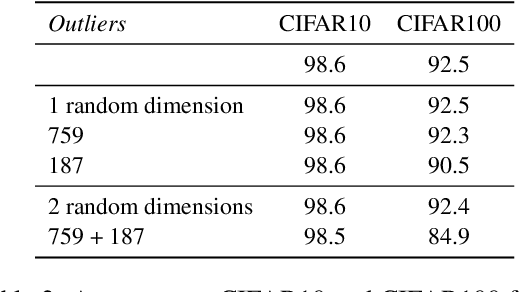
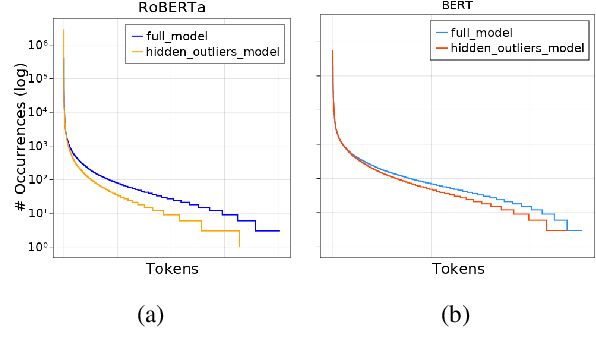
Transformer-based language models are known to display anisotropic behavior: the token embeddings are not homogeneously spread in space, but rather accumulate along certain directions. A related recent finding is the outlier phenomenon: the parameters in the final element of Transformer layers that consistently have unusual magnitude in the same dimension across the model, and significantly degrade its performance if disabled. We replicate the evidence for the outlier phenomenon and we link it to the geometry of the embedding space. Our main finding is that in both BERT and RoBERTa the token frequency, known to contribute to anisotropicity, also contributes to the outlier phenomenon. In its turn, the outlier phenomenon contributes to the "vertical" self-attention pattern that enables the model to focus on the special tokens. We also find that, surprisingly, the outlier effect on the model performance varies by layer, and that variance is also related to the correlation between outlier magnitude and encoded token frequency.