 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstruct a Sentence with Multiple Specified Words
Jun 25, 2022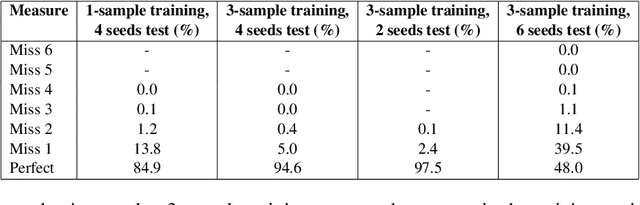

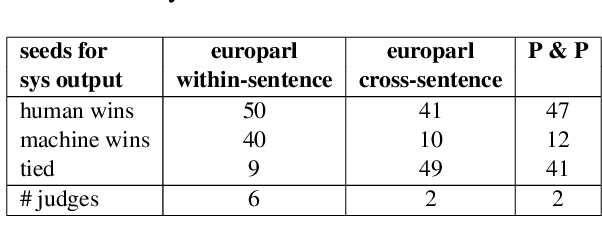
This paper demonstrates a task to finetune a BART model so it can construct a sentence from an arbitrary set of words, which used to be a difficult NLP task. The training task is making sentences with four words, but the trained model can generate sentences when fewer or more words are provided. The output sentences have high quality in general. The model can have some real-world applications, and this task can be used as an evaluation mechanism for any language model as well.
Memory-Augmented Recurrent Networks for Dialogue Coherence
Oct 16, 2019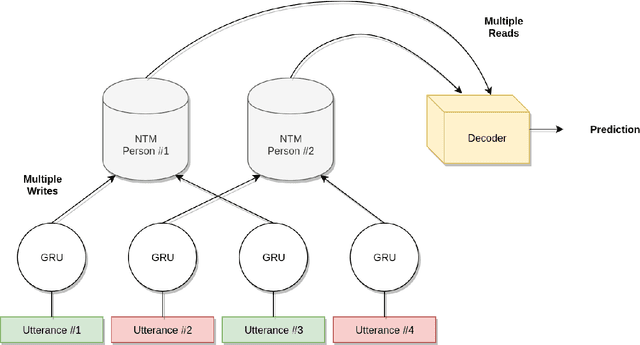
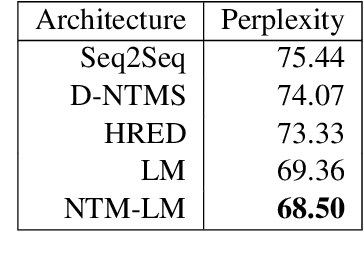
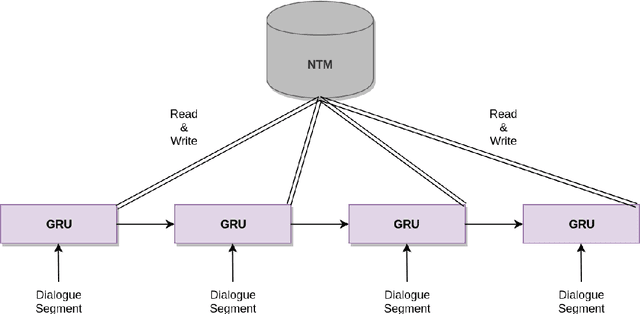

Recent dialogue approaches operate by reading each word in a conversation history, and aggregating accrued dialogue information into a single state. This fixed-size vector is not expandable and must maintain a consistent format over time. Other recent approaches exploit an attention mechanism to extract useful information from past conversational utterances, but this introduces an increased computational complexity. In this work, we explore the use of the Neural Turing Machine (NTM) to provide a more permanent and flexible storage mechanism for maintaining dialogue coherence. Specifically, we introduce two separate dialogue architectures based on this NTM design. The first design features a sequence-to-sequence architecture with two separate NTM modules, one for each participant in the conversation. The second memory architecture incorporates a single NTM module, which stores parallel context information for both speakers. This second design also replaces the sequence-to-sequence architecture with a neural language model, to allow for longer context of the NTM and greater understanding of the dialogue history. We report perplexity performance for both models, and compare them to existing baselines.
Solving Math Word Problems with Double-Decoder Transformer
Aug 28, 2019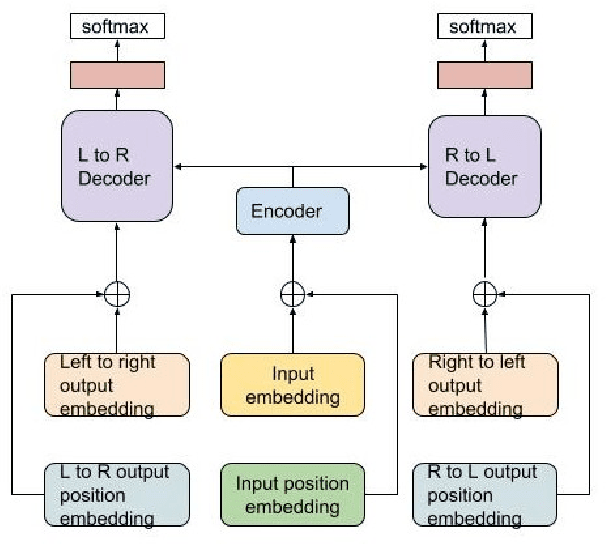
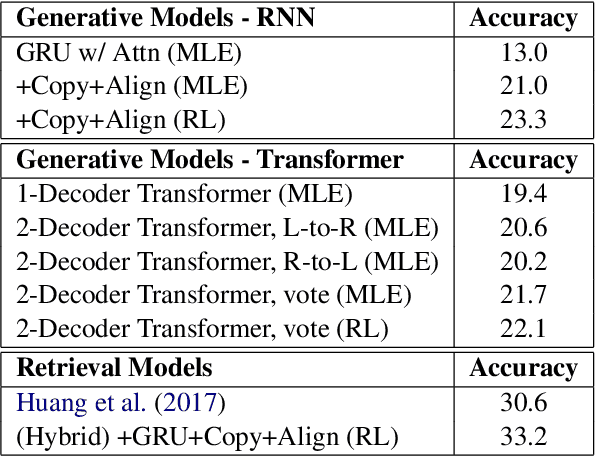
This paper proposes a Transformer-based model to generate equations for math word problems. It achieves much better results than RNN models when copy and align mechanisms are not used, and can outperform complex copy and align RNN models. We also show that training a Transformer jointly in a generation task with two decoders, left-to-right and right-to-left, is beneficial. Such a Transformer performs better than the one with just one decoder not only because of the ensemble effect, but also because it improves the encoder training procedure. We also experiment with adding reinforcement learning to our model, showing improved performance compared to MLE training.
Triad-based Neural Network for Coreference Resolution
Sep 18, 2018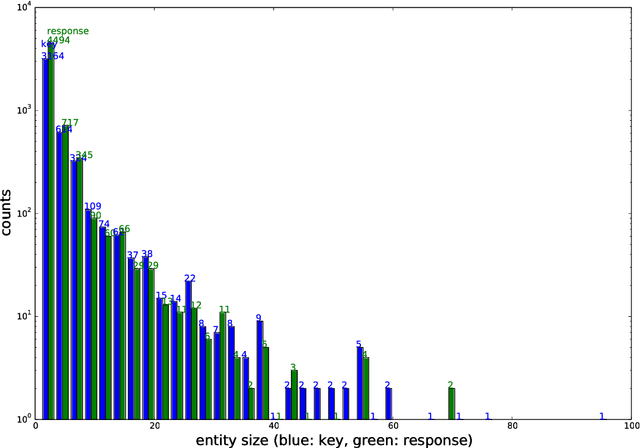
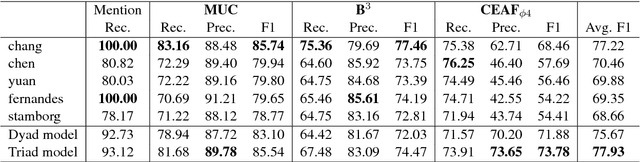

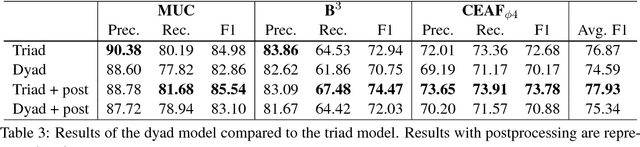
We propose a triad-based neural network system that generates affinity scores between entity mentions for coreference resolution. The system simultaneously accepts three mentions as input, taking mutual dependency and logical constraints of all three mentions into account, and thus makes more accurate predictions than the traditional pairwise approach. Depending on system choices, the affinity scores can be further used in clustering or mention ranking. Our experiments show that a standard hierarchical clustering using the scores produces state-of-art results with gold mentions on the English portion of CoNLL 2012 Shared Task. The model does not rely on many handcrafted features and is easy to train and use. The triads can also be easily extended to polyads of higher orders. To our knowledge, this is the first neural network system to model mutual dependency of more than two members at mention level.
Temporal Information Extraction for Question Answering Using Syntactic Dependencies in an LSTM-based Architecture
Oct 05, 2017
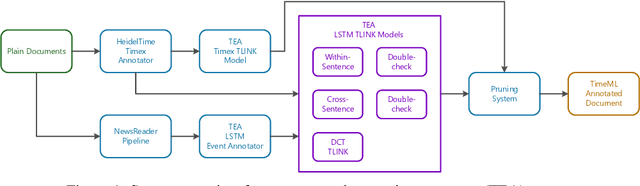
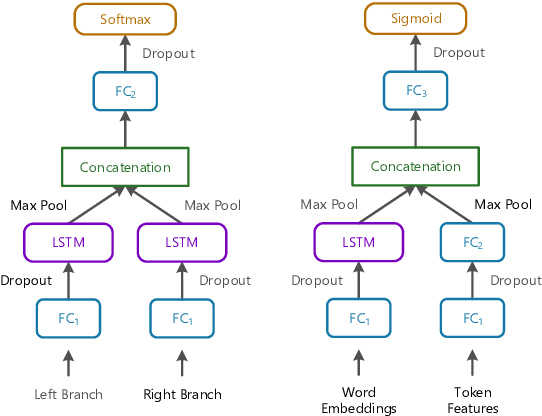

In this paper, we propose to use a set of simple, uniform in architecture LSTM-based models to recover different kinds of temporal relations from text. Using the shortest dependency path between entities as input, the same architecture is used to extract intra-sentence, cross-sentence, and document creation time relations. A "double-checking" technique reverses entity pairs in classification, boosting the recall of positive cases and reducing misclassifications between opposite classes. An efficient pruning algorithm resolves conflicts globally. Evaluated on QA-TempEval (SemEval2015 Task 5), our proposed technique outperforms state-of-the-art methods by a large margin.