 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-Conditioned Next-Frame Video Generation with Neural Flows
Oct 16, 2019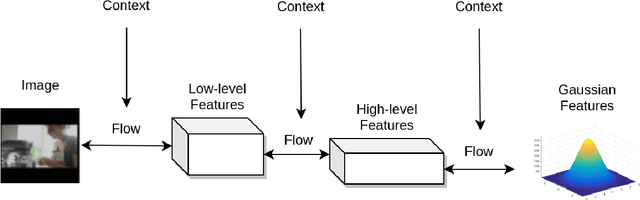


Recent state-of-the-art video generation systems employ Generative Adversarial Networks (GANs) or Variational Autoencoders (VAEs) to produce novel videos. However, VAE models typically produce blurry outputs when faced with sub-optimal conditioning of the input, and GANs are known to be unstable for large output sizes. In addition, the output videos of these models are difficult to evaluate, partly because the GAN loss function is not an accurate measure of convergence. In this work, we propose using a state-of-the-art neural flow generator called Glow to generate videos conditioned on a textual label, one frame at a time. Neural flow models are more stable than standard GANs, as they only optimize a single cross entropy loss function, which is monotonic and avoids the circular convergence issues of the GAN minimax objective. In addition, we also show how to condition Glow on external context, while still preserving the invertible nature of each "flow" layer. Finally, we evaluate the proposed Glow model by calculating cross entropy on a held-out validation set of videos, in order to compare multiple versions of the proposed model via an ablation study. We show generated videos and discuss future improvements.
Memory-Augmented Recurrent Networks for Dialogue Coherence
Oct 16, 2019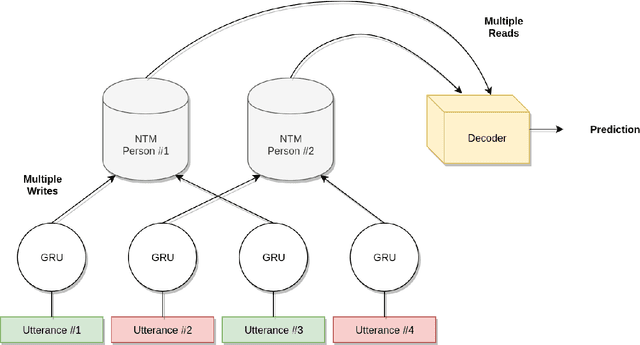
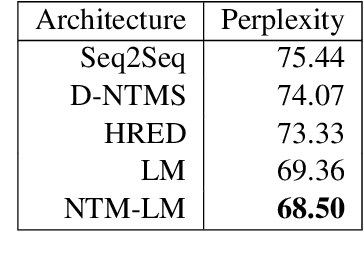
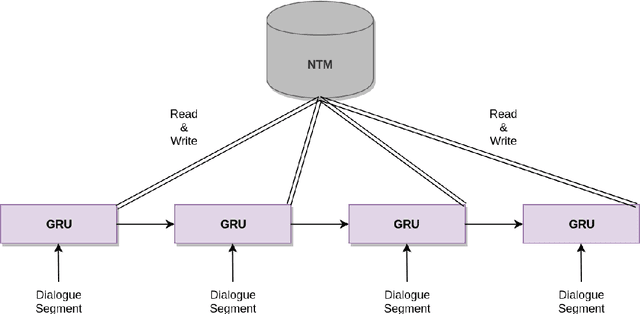

Recent dialogue approaches operate by reading each word in a conversation history, and aggregating accrued dialogue information into a single state. This fixed-size vector is not expandable and must maintain a consistent format over time. Other recent approaches exploit an attention mechanism to extract useful information from past conversational utterances, but this introduces an increased computational complexity. In this work, we explore the use of the Neural Turing Machine (NTM) to provide a more permanent and flexible storage mechanism for maintaining dialogue coherence. Specifically, we introduce two separate dialogue architectures based on this NTM design. The first design features a sequence-to-sequence architecture with two separate NTM modules, one for each participant in the conversation. The second memory architecture incorporates a single NTM module, which stores parallel context information for both speakers. This second design also replaces the sequence-to-sequence architecture with a neural language model, to allow for longer context of the NTM and greater understanding of the dialogue history. We report perplexity performance for both models, and compare them to existing baselines.
Injecting Hierarchy with U-Net Transformers
Oct 16, 2019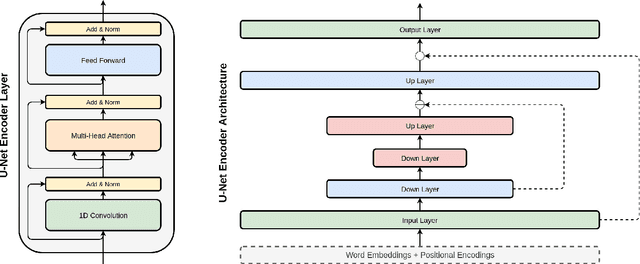

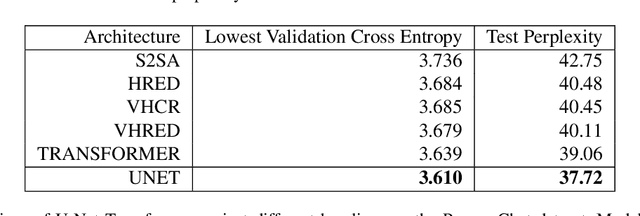
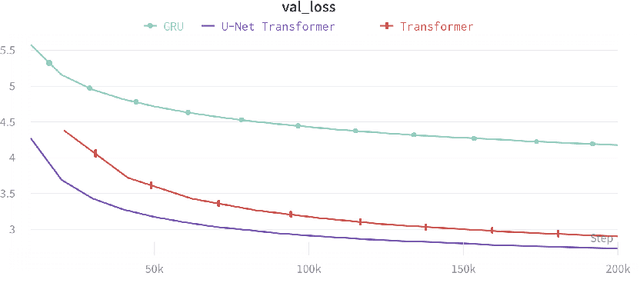
The Transformer architecture has become increasingly popular over the past couple of years, owing to its impressive performance on a number of natural language processing (NLP) tasks. However, it may be argued that the Transformer architecture lacks an explicit hierarchical representation, as all computations occur on word-level representations alone, and therefore, learning structure poses a challenge for Transformer models. In the present work, we introduce hierarchical processing into the Transformer model, taking inspiration from the U-Net architecture, popular in computer vision for its hierarchical view of natural images. We propose a novel architecture that combines ideas from Transformer and U-Net models to incorporate hierarchy at multiple levels of abstraction. We empirically demonstrate that the proposed architecture outperforms the vanilla Transformer and strong baselines in the chit-chat dialogue and machine translation domains.
Adversarial Text Generation Without Reinforcement Learning
Oct 11, 2018

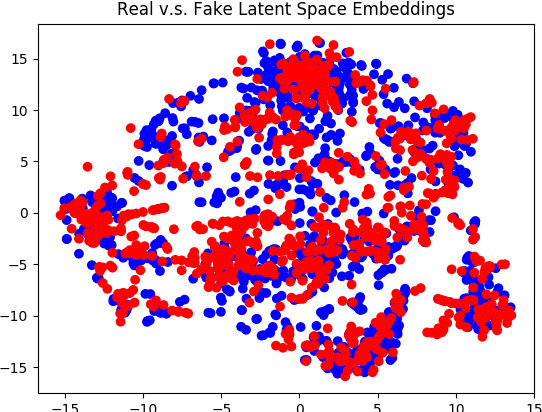
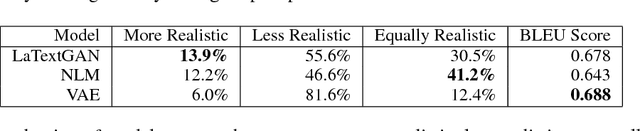
Generative Adversarial Networks (GANs) have experienced a recent surge in popularity, performing competitively in a variety of tasks, especially in computer vision. However, GAN training has shown limited success in natural language processing. This is largely because sequences of text are discrete, and thus gradients cannot propagate from the discriminator to the generator. Recent solutions use reinforcement learning to propagate approximate gradients to the generator, but this is inefficient to train. We propose to utilize an autoencoder to learn a low-dimensional representation of sentences. A GAN is then trained to generate its own vectors in this space, which decode to realistic utterances. We report both random and interpolated samples from the generator. Visualization of sentence vectors indicate our model correctly learns the latent space of the autoencoder. Both human ratings and BLEU scores show that our model generates realistic text against competitive baselines.
Adversarial Decomposition of Text Representation
Aug 27, 2018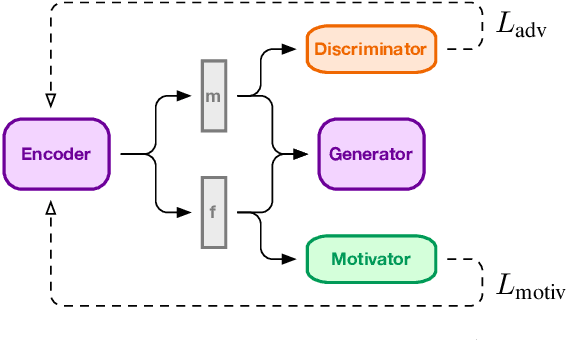

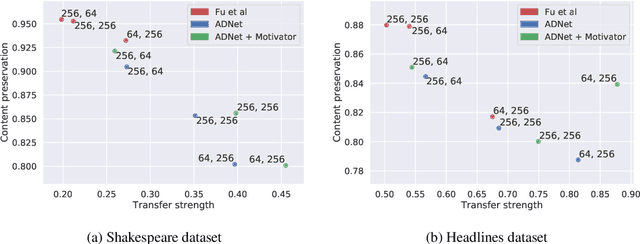

In this paper, we present a method for adversarial decomposition of text representation. This method can be used to decompose a representation of an input sentence into several independent vectors, where each vector is responsible for a specific aspect of the input sentence. We evaluate the proposed method on several case studies: the conversion between different social registers, diachronic language change and the decomposition of the sentiment polarity of input sentences. We show that the proposed method is capable of fine-grained controlled change of these aspects of the input sentence. The model uses adversarial-motivational training and includes a special motivational loss, which acts opposite to the discriminator and encourages a better decomposition. Finally, we evaluate the obtained meaning embeddings on a downstream task of paraphrase detection and show that they are significantly better than embeddings of a regular autoencoder.