 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-Conditioned Next-Frame Video Generation with Neural Flows
Paper and Code
Oct 16, 2019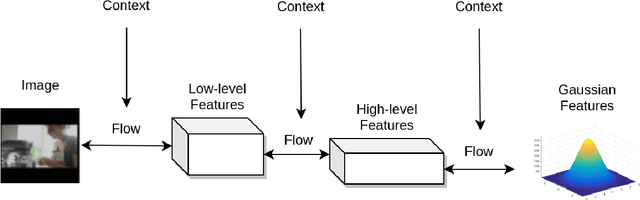


Recent state-of-the-art video generation systems employ Generative Adversarial Networks (GANs) or Variational Autoencoders (VAEs) to produce novel videos. However, VAE models typically produce blurry outputs when faced with sub-optimal conditioning of the input, and GANs are known to be unstable for large output sizes. In addition, the output videos of these models are difficult to evaluate, partly because the GAN loss function is not an accurate measure of convergence. In this work, we propose using a state-of-the-art neural flow generator called Glow to generate videos conditioned on a textual label, one frame at a time. Neural flow models are more stable than standard GANs, as they only optimize a single cross entropy loss function, which is monotonic and avoids the circular convergence issues of the GAN minimax objective. In addition, we also show how to condition Glow on external context, while still preserving the invertible nature of each "flow" layer. Finally, we evaluate the proposed Glow model by calculating cross entropy on a held-out validation set of videos, in order to compare multiple versions of the proposed model via an ablation study. We show generated videos and discuss future improvements.