 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInjecting Hierarchy with U-Net Transformers
Paper and Code
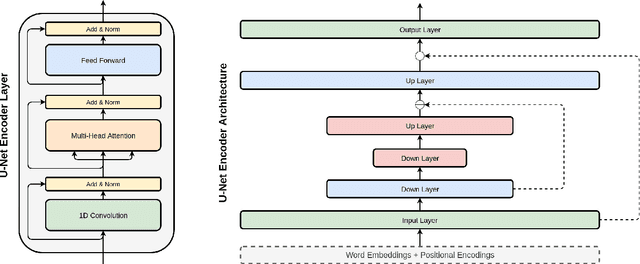

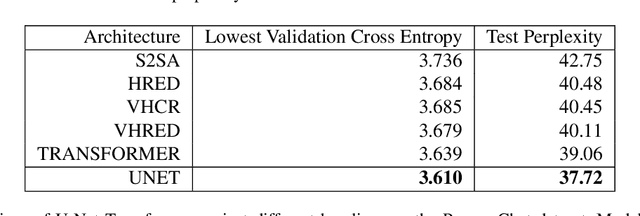
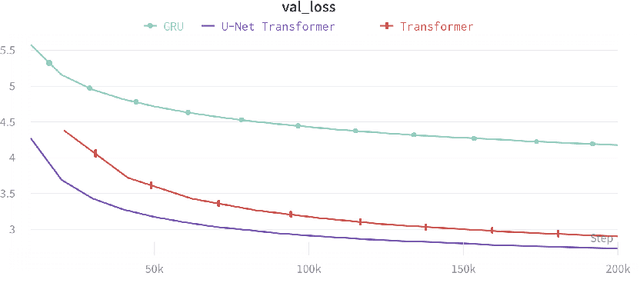
The Transformer architecture has become increasingly popular over the past couple of years, owing to its impressive performance on a number of natural language processing (NLP) tasks. However, it may be argued that the Transformer architecture lacks an explicit hierarchical representation, as all computations occur on word-level representations alone, and therefore, learning structure poses a challenge for Transformer models. In the present work, we introduce hierarchical processing into the Transformer model, taking inspiration from the U-Net architecture, popular in computer vision for its hierarchical view of natural images. We propose a novel architecture that combines ideas from Transformer and U-Net models to incorporate hierarchy at multiple levels of abstraction. We empirically demonstrate that the proposed architecture outperforms the vanilla Transformer and strong baselines in the chit-chat dialogue and machine translation domains.