Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Math Word Problems with Double-Decoder Transformer
Paper and Code
Aug 28, 2019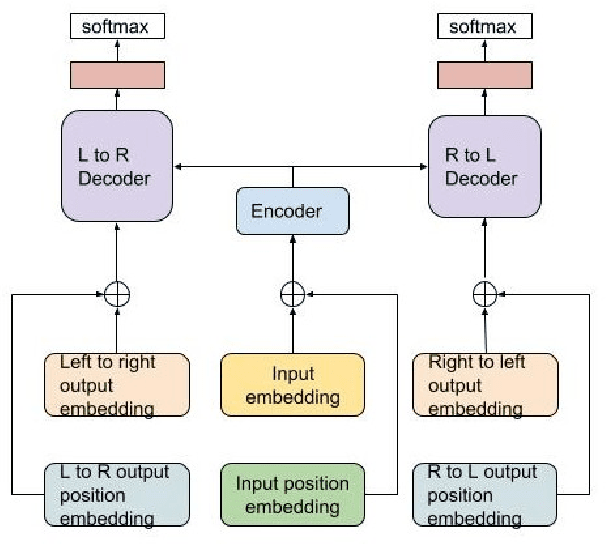
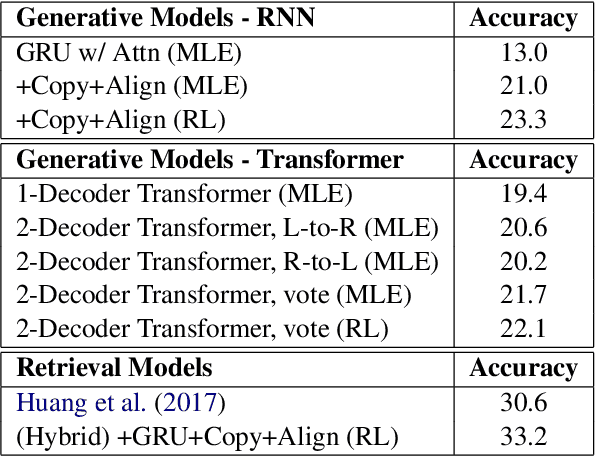
This paper proposes a Transformer-based model to generate equations for math word problems. It achieves much better results than RNN models when copy and align mechanisms are not used, and can outperform complex copy and align RNN models. We also show that training a Transformer jointly in a generation task with two decoders, left-to-right and right-to-left, is beneficial. Such a Transformer performs better than the one with just one decoder not only because of the ensemble effect, but also because it improves the encoder training procedure. We also experiment with adding reinforcement learning to our model, showing improved performance compared to MLE training.
View paper on