 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePnPXAI: A Universal XAI Framework Providing Automatic Explanations Across Diverse Modalities and Models
May 15, 2025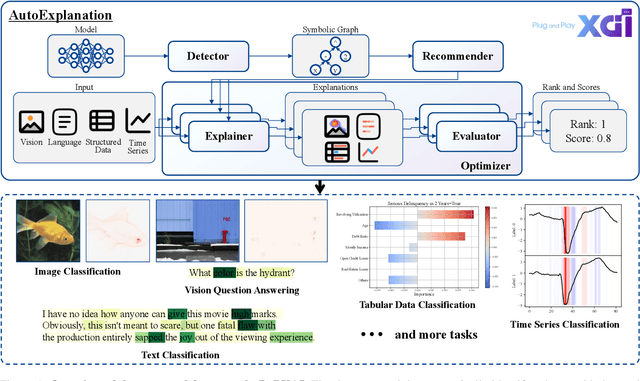

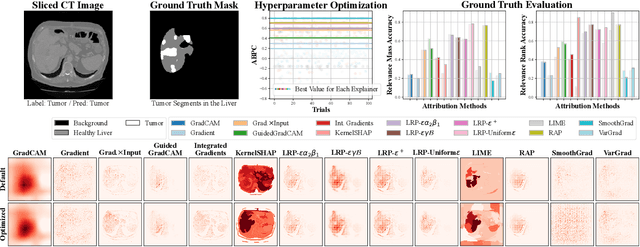
Recently, post hoc explanation methods have emerged to enhance model transparency by attributing model outputs to input features. However, these methods face challenges due to their specificity to certain neural network architectures and data modalities. Existing explainable artificial intelligence (XAI) frameworks have attempted to address these challenges but suffer from several limitations. These include limited flexibility to diverse model architectures and data modalities due to hard-coded implementations, a restricted number of supported XAI methods because of the requirements for layer-specific operations of attribution methods, and sub-optimal recommendations of explanations due to the lack of evaluation and optimization phases. Consequently, these limitations impede the adoption of XAI technology in real-world applications, making it difficult for practitioners to select the optimal explanation method for their domain. To address these limitations, we introduce \textbf{PnPXAI}, a universal XAI framework that supports diverse data modalities and neural network models in a Plug-and-Play (PnP) manner. PnPXAI automatically detects model architectures, recommends applicable explanation methods, and optimizes hyperparameters for optimal explanations. We validate the framework's effectiveness through user surveys and showcase its versatility across various domains, including medicine and finance.
TraM : Enhancing User Sleep Prediction with Transformer-based Multivariate Time Series Modeling and Machine Learning Ensembles
Oct 15, 2024This paper presents a novel approach that leverages Transformer-based multivariate time series model and Machine Learning Ensembles to predict the quality of human sleep, emotional states, and stress levels. A formula to calculate the labels was developed, and the various models were applied to user data. Time Series Transformer was used for labels where time series characteristics are crucial, while Machine Learning Ensembles were employed for labels requiring comprehensive daily activity statistics. Time Series Transformer excels in capturing the characteristics of time series through pre-training, while Machine Learning Ensembles select machine learning models that meet our categorization criteria. The proposed model, TraM, scored 6.10 out of 10 in experiments, demonstrating superior performance compared to other methodologies. The code and configuration for the TraM framework are available at: https://github.com/jin-jae/ETRI-Paper-Contest.
Statistical and computational rates in high rank tensor estimation
Apr 08, 2023Higher-order tensor datasets arise commonly in recommendation systems, neuroimaging, and social networks. Here we develop probable methods for estimating a possibly high rank signal tensor from noisy observations. We consider a generative latent variable tensor model that incorporates both high rank and low rank models, including but not limited to, simple hypergraphon models, single index models, low-rank CP models, and low-rank Tucker models. Comprehensive results are developed on both the statistical and computational limits for the signal tensor estimation. We find that high-dimensional latent variable tensors are of log-rank; the fact explains the pervasiveness of low-rank tensors in applications. Furthermore, we propose a polynomial-time spectral algorithm that achieves the computationally optimal rate. We show that the statistical-computational gap emerges only for latent variable tensors of order 3 or higher. Numerical experiments and two real data applications are presented to demonstrate the practical merits of our methods.
Sufficient dimension reduction for feature matrices
Mar 07, 2023We address the problem of sufficient dimension reduction for feature matrices, which arises often in sensor network localization, brain neuroimaging, and electroencephalography analysis. In general, feature matrices have both row- and column-wise interpretations and contain structural information that can be lost with naive vectorization approaches. To address this, we propose a method called principal support matrix machine (PSMM) for the matrix sufficient dimension reduction. The PSMM converts the sufficient dimension reduction problem into a series of classification problems by dividing the response variables into slices. It effectively utilizes the matrix structure by finding hyperplanes with rank-1 normal matrix that optimally separate the sliced responses. Additionally, we extend our approach to the higher-order tensor case. Our numerical analysis demonstrates that the PSMM outperforms existing methods and has strong interpretability in real data applications.
Smooth tensor estimation with unknown permutations
Nov 08, 2021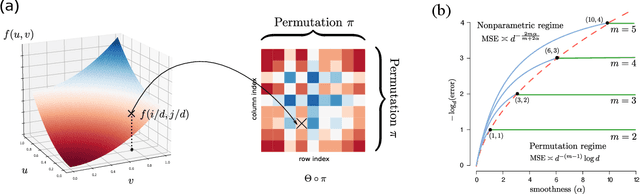

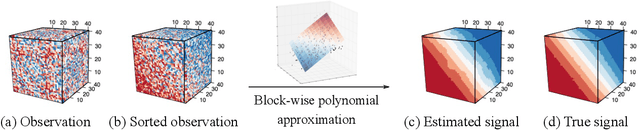
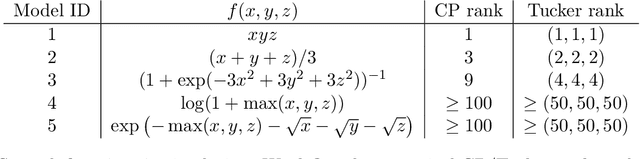
We consider the problem of structured tensor denoising in the presence of unknown permutations. Such data problems arise commonly in recommendation system, neuroimaging, community detection, and multiway comparison applications. Here, we develop a general family of smooth tensor models up to arbitrary index permutations; the model incorporates the popular tensor block models and Lipschitz hypergraphon models as special cases. We show that a constrained least-squares estimator in the block-wise polynomial family achieves the minimax error bound. A phase transition phenomenon is revealed with respect to the smoothness threshold needed for optimal recovery. In particular, we find that a polynomial of degree up to $(m-2)(m+1)/2$ is sufficient for accurate recovery of order-$m$ tensors, whereas higher degree exhibits no further benefits. This phenomenon reveals the intrinsic distinction for smooth tensor estimation problems with and without unknown permutations. Furthermore, we provide an efficient polynomial-time Borda count algorithm that provably achieves optimal rate under monotonicity assumptions. The efficacy of our procedure is demonstrated through both simulations and Chicago crime data analysis.
Nonparametric Trace Regression in High Dimensions via Sign Series Representation
May 04, 2021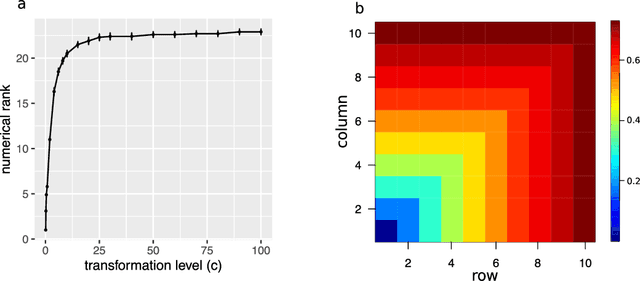

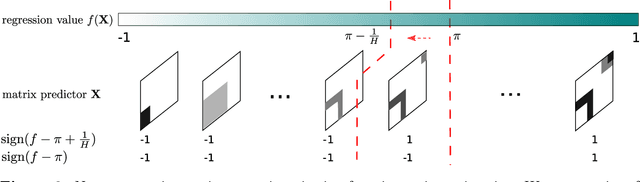

Learning of matrix-valued data has recently surged in a range of scientific and business applications. Trace regression is a widely used method to model effects of matrix predictors and has shown great success in matrix learning. However, nearly all existing trace regression solutions rely on two assumptions: (i) a known functional form of the conditional mean, and (ii) a global low-rank structure in the entire range of the regression function, both of which may be violated in practice. In this article, we relax these assumptions by developing a general framework for nonparametric trace regression models via structured sign series representations of high dimensional functions. The new model embraces both linear and nonlinear trace effects, and enjoys rank invariance to order-preserving transformations of the response. In the context of matrix completion, our framework leads to a substantially richer model based on what we coin as the "sign rank" of a matrix. We show that the sign series can be statistically characterized by weighted classification tasks. Based on this connection, we propose a learning reduction approach to learn the regression model via a series of classifiers, and develop a parallelable computation algorithm to implement sign series aggregations. We establish the excess risk bounds, estimation error rates, and sample complexities. Our proposal provides a broad nonparametric paradigm to many important matrix learning problems, including matrix regression, matrix completion, multi-task learning, and compressed sensing. We demonstrate the advantages of our method through simulations and two applications, one on brain connectivity study and the other on high-rank image completion.
Beyond the Signs: Nonparametric Tensor Completion via Sign Series
Jan 31, 2021

We consider the problem of tensor estimation from noisy observations with possibly missing entries. A nonparametric approach to tensor completion is developed based on a new model which we coin as sign representable tensors. The model represents the signal tensor of interest using a series of structured sign tensors. Unlike earlier methods, the sign series representation effectively addresses both low- and high-rank signals, while encompassing many existing tensor models -- including CP models, Tucker models, single index models, several hypergraphon models -- as special cases. We show that the sign tensor series is theoretically characterized, and computationally estimable, via classification tasks with carefully-specified weights. Excess risk bounds, estimation error rates, and sample complexities are established. We demonstrate the outperformance of our approach over previous methods on two datasets, one on human brain connectivity networks and the other on topic data mining.
Tensor denoising and completion based on ordinal observations
Feb 16, 2020
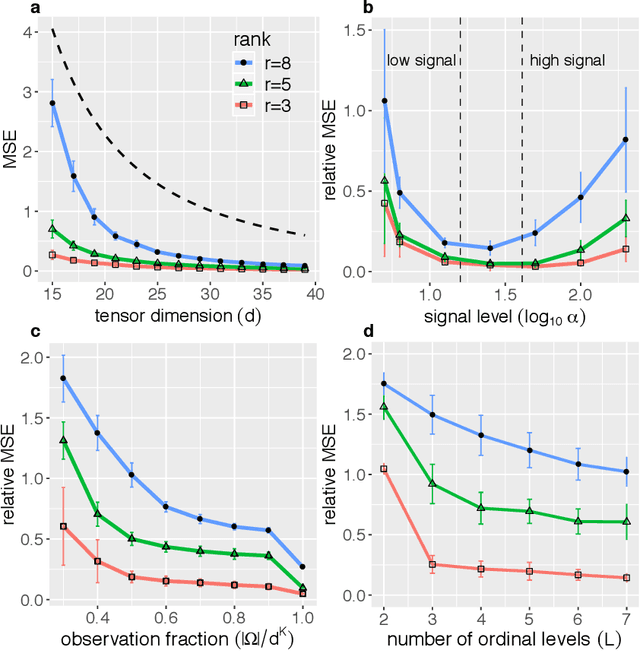
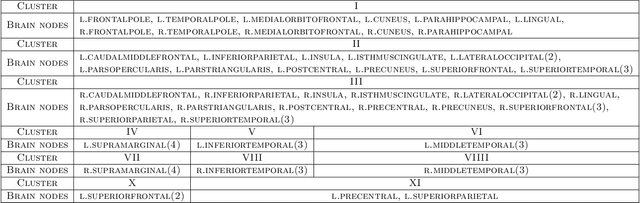
Higher-order tensors arise frequently in applications such as neuroimaging, recommendation system, social network analysis, and psychological studies. We consider the problem of low-rank tensor estimation from possibly incomplete, ordinal-valued observations. Two related problems are studied, one on tensor denoising and another on tensor completion. We propose a multi-linear cumulative link model, develop a rank-constrained M-estimator, and obtain theoretical accuracy guarantees. Our mean squared error bound enjoys a faster convergence rate than previous results, and we show that the proposed estimator is minimax optimal under the class of low-rank models. Furthermore, the procedure developed serves as an efficient completion method which guarantees consistent recovery of an order-$K$ $(d,\ldots,d)$-dimensional low-rank tensor using only $\tilde{\mathcal{O}}(Kd)$ noisy, quantized observations. We demonstrate the outperformance of our approach over previous methods on the tasks of clustering and collaborative filtering.