 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMany Ways to be Lonely: Fine-grained Characterization of Loneliness and its Potential Changes in COVID-19
Jan 20, 2022
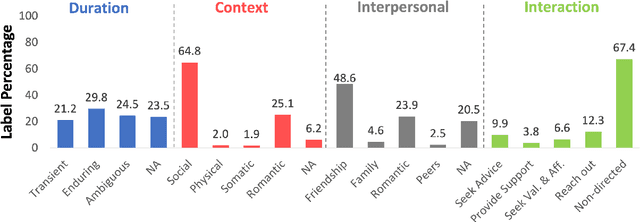
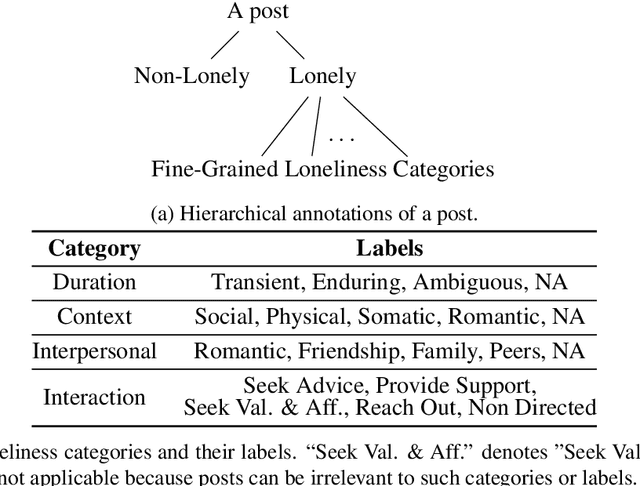
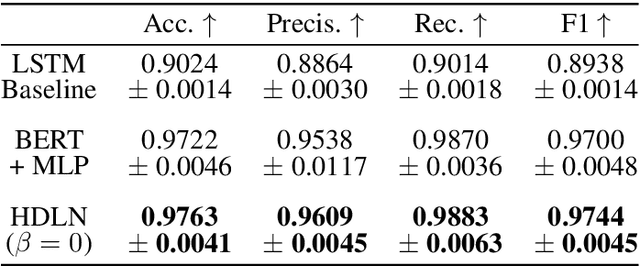
Loneliness has been associated with negative outcomes for physical and mental health. Understanding how people express and cope with various forms of loneliness is critical for early screening and targeted interventions to reduce loneliness, particularly among vulnerable groups such as young adults. To examine how different forms of loneliness and coping strategies manifest in loneliness self-disclosure, we built a dataset, FIG-Loneliness (FIne-Grained Loneliness) by using Reddit posts in two young adult-focused forums and two loneliness related forums consisting of a diverse age group. We provide annotations by trained human annotators for binary and fine-grained loneliness classifications of the posts. Trained on FIG-Loneliness, two BERT-based models were used to understand loneliness forms and authors' coping strategies in these forums. Our binary loneliness classification archived an accuracy above 97%, and fine-grained loneliness category classification reached an average accuracy of 77% across all labeled categories. With FIG-Loneliness and model predictions, we found that loneliness expressions in the young adult related forums are distinct from other forums. Those in young adult-focused forums are more likely to express concerns pertaining to peer relationship, and are potentially more sensitive to geographical isolation impacted by the COVID-19 pandemic lockdown. Also, we show that different forms of loneliness have differential use in coping strategies.
Disentangling Latent Emotions of Word Embeddings on Complex Emotional Narratives
Aug 15, 2019
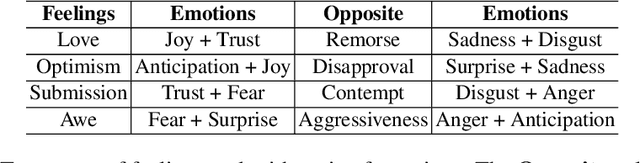
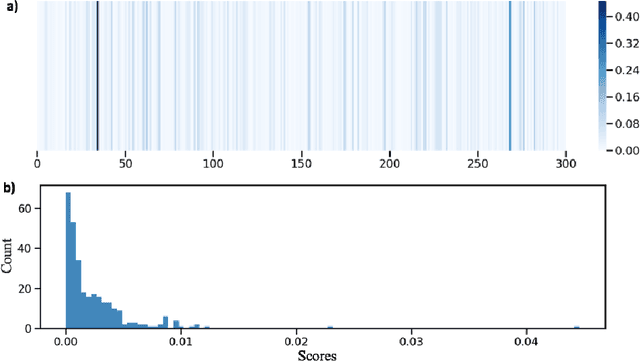
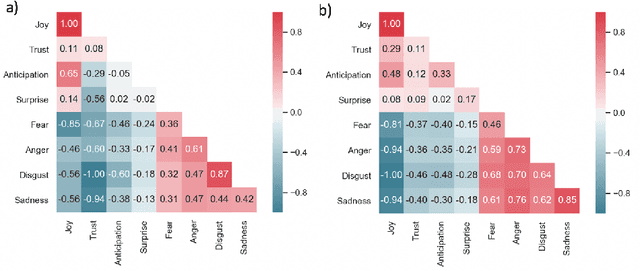
Word embedding models such as GloVe are widely used in natural language processing (NLP) research to convert words into vectors. Here, we provide a preliminary guide to probe latent emotions in text through GloVe word vectors. First, we trained a neural network model to predict continuous emotion valence ratings by taking linguistic inputs from Stanford Emotional Narratives Dataset (SEND). After interpreting the weights in the model, we found that only a few dimensions of the word vectors contributed to expressing emotions in text, and words were clustered on the basis of their emotional polarities. Furthermore, we performed a linear transformation that projected high dimensional embedded vectors into an emotion space. Based on NRC Emotion Lexicon (EmoLex), we visualized the entanglement of emotions in the lexicon by using both projected and raw GloVe word vectors. We showed that, in the proposed emotion space, we were able to better disentangle emotions than using raw GloVe vectors alone. In addition, we found that the sum vectors of different pairs of emotion words successfully captured expressed human feelings in the EmoLex. For example, the sum of two embedded word vectors expressing Joy and Trust which express Love shared high similarity (similarity score .62) with the embedded vector expressing Optimism. On the contrary, this sum vector was dissimilar (similarity score -.19) with the the embedded vector expressing Remorse. In this paper, we argue that through the proposed emotion space, arithmetic of emotions is preserved in the word vectors. The affective representation uncovered in emotion vector space could shed some light on how to help machines to disentangle emotion expressed in word embeddings.
* 9 pages, submitted and accepted by NLP conference 2019