 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$π^{*}_{0.6}$: a VLA That Learns From Experience
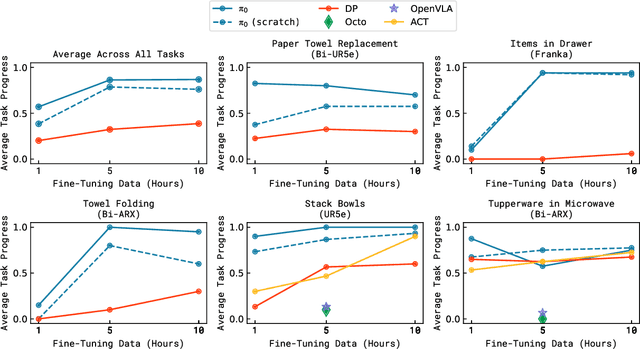
Nov 19, 2025We study how vision-language-action (VLA) models can improve through real-world deployments via reinforcement learning (RL). We present a general-purpose method, RL with Experience and Corrections via Advantage-conditioned Policies (RECAP), that provides for RL training of VLAs via advantage conditioning. Our method incorporates heterogeneous data into the self-improvement process, including demonstrations, data from on-policy collection, and expert teleoperated interventions provided during autonomous execution. RECAP starts by pre-training a generalist VLA with offline RL, which we call $π^{*}_{0.6}$, that can then be specialized to attain high performance on downstream tasks through on-robot data collection. We show that the $π^{*}_{0.6}$ model trained with the full RECAP method can fold laundry in real homes, reliably assemble boxes, and make espresso drinks using a professional espresso machine. On some of the hardest tasks, RECAP more than doubles task throughput and roughly halves the task failure rate.
Automatic classification of stop realisation with wav2vec2.0
May 29, 2025



Modern phonetic research regularly makes use of automatic tools for the annotation of speech data, however few tools exist for the annotation of many variable phonetic phenomena. At the same time, pre-trained self-supervised models, such as wav2vec2.0, have been shown to perform well at speech classification tasks and latently encode fine-grained phonetic information. We demonstrate that wav2vec2.0 models can be trained to automatically classify stop burst presence with high accuracy in both English and Japanese, robust across both finely-curated and unprepared speech corpora. Patterns of variability in stop realisation are replicated with the automatic annotations, and closely follow those of manual annotations. These results demonstrate the potential of pre-trained speech models as tools for the automatic annotation and processing of speech corpus data, enabling researchers to `scale-up' the scope of phonetic research with relative ease.
$π_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Apr 22, 2025



In order for robots to be useful, they must perform practically relevant tasks in the real world, outside of the lab. While vision-language-action (VLA) models have demonstrated impressive results for end-to-end robot control, it remains an open question how far such models can generalize in the wild. We describe $\pi_{0.5}$, a new model based on $\pi_{0}$ that uses co-training on heterogeneous tasks to enable broad generalization. $\pi_{0.5}$\ uses data from multiple robots, high-level semantic prediction, web data, and other sources to enable broadly generalizable real-world robotic manipulation. Our system uses a combination of co-training and hybrid multi-modal examples that combine image observations, language commands, object detections, semantic subtask prediction, and low-level actions. Our experiments show that this kind of knowledge transfer is essential for effective generalization, and we demonstrate for the first time that an end-to-end learning-enabled robotic system can perform long-horizon and dexterous manipulation skills, such as cleaning a kitchen or bedroom, in entirely new homes.
Hi Robot: Open-Ended Instruction Following with Hierarchical Vision-Language-Action Models
Feb 26, 2025Generalist robots that can perform a range of different tasks in open-world settings must be able to not only reason about the steps needed to accomplish their goals, but also process complex instructions, prompts, and even feedback during task execution. Intricate instructions (e.g., "Could you make me a vegetarian sandwich?" or "I don't like that one") require not just the ability to physically perform the individual steps, but the ability to situate complex commands and feedback in the physical world. In this work, we describe a system that uses vision-language models in a hierarchical structure, first reasoning over complex prompts and user feedback to deduce the most appropriate next step to fulfill the task, and then performing that step with low-level actions. In contrast to direct instruction following methods that can fulfill simple commands ("pick up the cup"), our system can reason through complex prompts and incorporate situated feedback during task execution ("that's not trash"). We evaluate our system across three robotic platforms, including single-arm, dual-arm, and dual-arm mobile robots, demonstrating its ability to handle tasks such as cleaning messy tables, making sandwiches, and grocery shopping.
$π_0$: A Vision-Language-Action Flow Model for General Robot Control
Oct 31, 2024

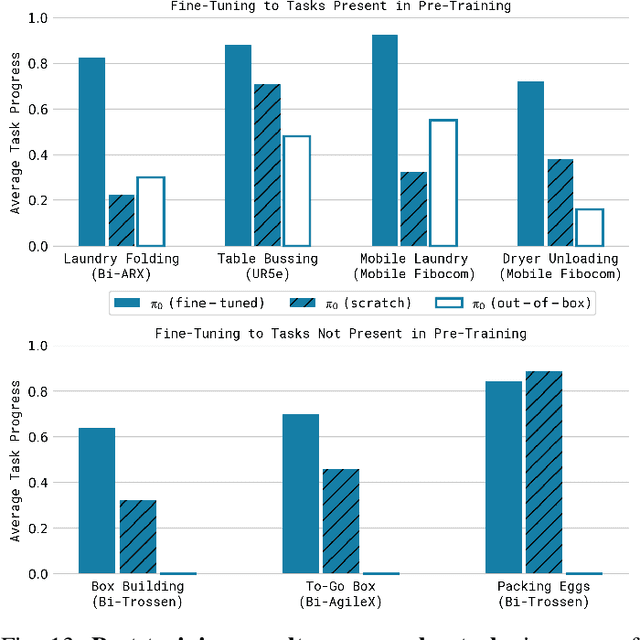
Robot learning holds tremendous promise to unlock the full potential of flexible, general, and dexterous robot systems, as well as to address some of the deepest questions in artificial intelligence. However, bringing robot learning to the level of generality required for effective real-world systems faces major obstacles in terms of data, generalization, and robustness. In this paper, we discuss how generalist robot policies (i.e., robot foundation models) can address these challenges, and how we can design effective generalist robot policies for complex and highly dexterous tasks. We propose a novel flow matching architecture built on top of a pre-trained vision-language model (VLM) to inherit Internet-scale semantic knowledge. We then discuss how this model can be trained on a large and diverse dataset from multiple dexterous robot platforms, including single-arm robots, dual-arm robots, and mobile manipulators. We evaluate our model in terms of its ability to perform tasks in zero shot after pre-training, follow language instructions from people and from a high-level VLM policy, and its ability to acquire new skills via fine-tuning. Our results cover a wide variety of tasks, such as laundry folding, table cleaning, and assembling boxes.
Exploring the anatomy of articulation rate in spontaneous English speech: relationships between utterance length effects and social factors
Aug 13, 2024



Speech rate has been shown to vary across social categories such as gender, age, and dialect, while also being conditioned by properties of speech planning. The effect of utterance length, where speech rate is faster and less variable for longer utterances, has also been shown to reduce the role of social factors once it has been accounted for, leaving unclear the relationship between social factors and speech production in conditioning speech rate. Through modelling of speech rate across 13 English speech corpora, it is found that utterance length has the largest effect on speech rate, though this effect itself varies little across corpora and speakers. While age and gender also modulate speech rate, their effects are much smaller in magnitude. These findings suggest utterance length effects may be conditioned by articulatory and perceptual constraints, and that social influences on speech rate should be interpreted in the broader context of how speech rate variation is structured.
Reconciling saliency and object center-bias hypotheses in explaining free-viewing fixations
Mar 30, 2015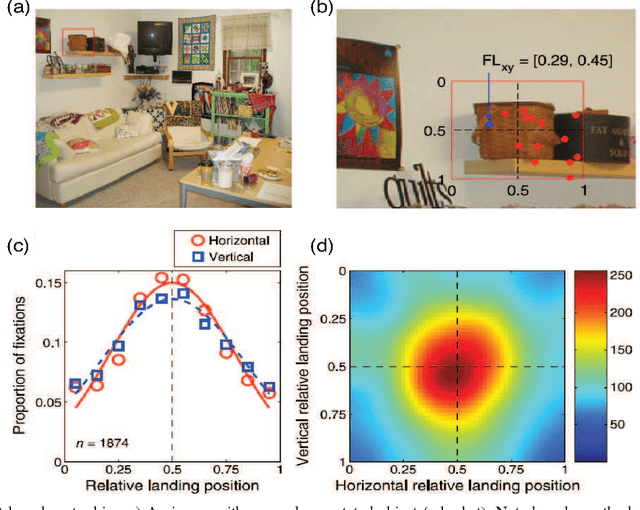

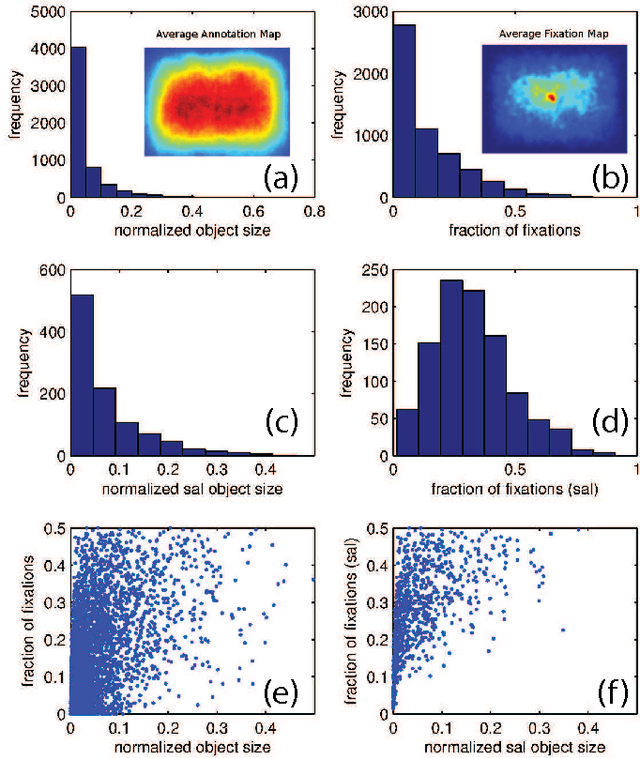

Predicting where people look in natural scenes has attracted a lot of interest in computer vision and computational neuroscience over the past two decades. Two seemingly contrasting categories of cues have been proposed to influence where people look: \textit{low-level image saliency} and \textit{high-level semantic information}. Our first contribution is to take a detailed look at these cues to confirm the hypothesis proposed by Henderson~\cite{henderson1993eye} and Nuthmann \& Henderson~\cite{nuthmann2010object} that observers tend to look at the center of objects. We analyzed fixation data for scene free-viewing over 17 observers on 60 fully annotated images with various types of objects. Images contained different types of scenes, such as natural scenes, line drawings, and 3D rendered scenes. Our second contribution is to propose a simple combined model of low-level saliency and object center-bias that outperforms each individual component significantly over our data, as well as on the OSIE dataset by Xu et al.~\cite{xu2014predicting}. The results reconcile saliency with object center-bias hypotheses and highlight that both types of cues are important in guiding fixations. Our work opens new directions to understand strategies that humans use in observing scenes and objects, and demonstrates the construction of combined models of low-level saliency and high-level object-based information.