 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLazy Incremental Search for Efficient Replanning with Bounded Suboptimality Guarantees
Oct 23, 2022



We present a lazy incremental search algorithm, Lifelong-GLS (L-GLS), along with its bounded suboptimal version, Bounded L-GLS (B-LGLS) that combine the search efficiency of incremental search algorithms with the evaluation efficiency of lazy search algorithms for fast replanning in problem domains where edge-evaluations are more expensive than vertex-expansions. The proposed algorithms generalize Lifelong Planning A* (LPA*) and its bounded suboptimal version, Truncated LPA* (TLPA*), within the Generalized Lazy Search (GLS) framework, so as to restrict expensive edge evaluations only to the current shortest subpath when the cost-to-come inconsistencies are propagated during repair. We also present dynamic versions of the L-GLS and B-LGLS algorithms, called Generalized D* (GD*) and Bounded Generalized D* (B-GD*), respectively, for efficient replanning with non-stationary queries, designed specifically for navigation of mobile robots. We prove that the proposed algorithms are complete and correct in finding a solution that is guaranteed not to exceed the optimal solution cost by a user-chosen factor. Our numerical and experimental results support the claim that the proposed integration of the incremental and lazy search frameworks can help find solutions faster compared to the regular incremental or regular lazy search algorithms when the underlying graph representation changes often.
GPU Parallelization of Policy Iteration RRT#
Mar 10, 2020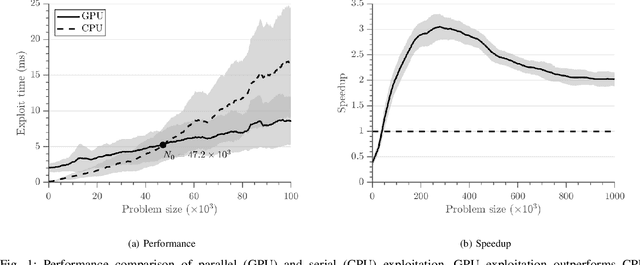
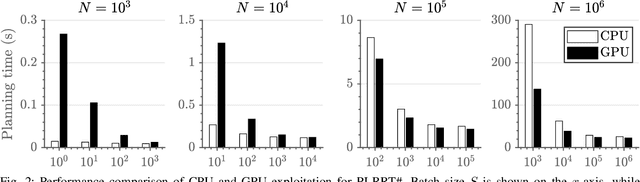
Sampling-based planning has become a de facto standard for complex robots given its superior ability to rapidly explore high-dimensional configuration spaces. Most existing optimal sampling-based planning algorithms are sequential in nature and cannot take advantage of wide parallelism available on modern computer hardware. Further, tight synchronization of exploration and exploitation phases in these algorithms limits sample throughput and planner performance. Policy Iteration RRT# (PI-RRT#) exposes fine-grained parallelism during the exploitation phase, but this parallelism has not yet been evaluated using a concrete implementation. We first present a novel GPU implementation of PI-RRT#'s exploitation phase and discuss data structure considerations to maximize parallel performance. Our implementation achieves 2-3x speedup over a serial PI-RRT# implementation for a 52.6% decrease in overall planning time on average. As a second contribution, we introduce the Batched-Extension RRT# algorithm, which loosens the synchronization present in PI-RRT# to realize independent 11.3x and 6.0x speedups under serial and parallel exploitation, respectively.