 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPU Parallelization of Policy Iteration RRT#
Paper and Code
Mar 10, 2020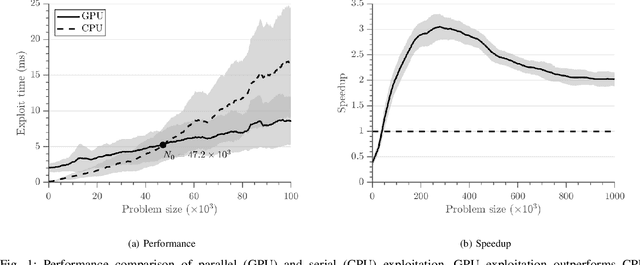
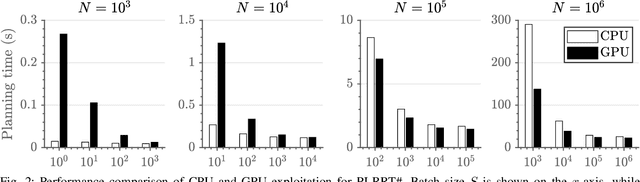
Sampling-based planning has become a de facto standard for complex robots given its superior ability to rapidly explore high-dimensional configuration spaces. Most existing optimal sampling-based planning algorithms are sequential in nature and cannot take advantage of wide parallelism available on modern computer hardware. Further, tight synchronization of exploration and exploitation phases in these algorithms limits sample throughput and planner performance. Policy Iteration RRT# (PI-RRT#) exposes fine-grained parallelism during the exploitation phase, but this parallelism has not yet been evaluated using a concrete implementation. We first present a novel GPU implementation of PI-RRT#'s exploitation phase and discuss data structure considerations to maximize parallel performance. Our implementation achieves 2-3x speedup over a serial PI-RRT# implementation for a 52.6% decrease in overall planning time on average. As a second contribution, we introduce the Batched-Extension RRT# algorithm, which loosens the synchronization present in PI-RRT# to realize independent 11.3x and 6.0x speedups under serial and parallel exploitation, respectively.