 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniCompress: Enhancing Multi-Data Medical Image Compression with Knowledge Distillation
May 27, 2024In the field of medical image compression, Implicit Neural Representation (INR) networks have shown remarkable versatility due to their flexible compression ratios, yet they are constrained by a one-to-one fitting approach that results in lengthy encoding times. Our novel method, ``\textbf{UniCompress}'', innovatively extends the compression capabilities of INR by being the first to compress multiple medical data blocks using a single INR network. By employing wavelet transforms and quantization, we introduce a codebook containing frequency domain information as a prior input to the INR network. This enhances the representational power of INR and provides distinctive conditioning for different image blocks. Furthermore, our research introduces a new technique for the knowledge distillation of implicit representations, simplifying complex model knowledge into more manageable formats to improve compression ratios. Extensive testing on CT and electron microscopy (EM) datasets has demonstrated that UniCompress outperforms traditional INR methods and commercial compression solutions like HEVC, especially in complex and high compression scenarios. Notably, compared to existing INR techniques, UniCompress achieves a 4$\sim$5 times increase in compression speed, marking a significant advancement in the field of medical image compression. Codes will be publicly available.
CPT-Interp: Continuous sPatial and Temporal Motion Modeling for 4D Medical Image Interpolation
May 24, 2024Motion information from 4D medical imaging offers critical insights into dynamic changes in patient anatomy for clinical assessments and radiotherapy planning and, thereby, enhances the capabilities of 3D image analysis. However, inherent physical and technical constraints of imaging hardware often necessitate a compromise between temporal resolution and image quality. Frame interpolation emerges as a pivotal solution to this challenge. Previous methods often suffer from discretion when they estimate the intermediate motion and execute the forward warping. In this study, we draw inspiration from fluid mechanics to propose a novel approach for continuously modeling patient anatomic motion using implicit neural representation. It ensures both spatial and temporal continuity, effectively bridging Eulerian and Lagrangian specifications together to naturally facilitate continuous frame interpolation. Our experiments across multiple datasets underscore the method's superior accuracy and speed. Furthermore, as a case-specific optimization (training-free) approach, it circumvents the need for extensive datasets and addresses model generalization issues.
A Compact Implicit Neural Representation for Efficient Storage of Massive 4D Functional Magnetic Resonance Imaging
Nov 30, 2023Functional Magnetic Resonance Imaging (fMRI) data is a kind of widely used four-dimensional biomedical data, demanding effective compression but presenting unique challenges for compression due to its intricate temporal dynamics, low signal-to-noise ratio, and complicated underlying redundancies. This paper reports a novel compression paradigm specifically tailored for fMRI data based on Implicit Neural Representation (INR). The proposed approach focuses on removing the various redundancies among the time series, including (i) conducting spatial correlation modeling for intra-region dynamics, (ii) decomposing reusable neuronal activation patterns, and using proper initialization together with nonlinear fusion to describe the inter-region similarity. The above scheme properly incorporates the unique features of fMRI data, and experimental results on publicly available datasets demonstrate the effectiveness of the proposed method, surpassing state-of-the-art algorithms in both conventional image quality evaluation metrics and fMRI downstream tasks. This work in this paper paves the way for sharing massive fMRI data at low bandwidth and high fidelity.
Lightweight High-Speed Photography Built on Coded Exposure and Implicit Neural Representation of Videos
Nov 22, 2023The compact cameras recording high-speed scenes with high resolution are highly demanded, but the required high bandwidth often leads to bulky, heavy systems, which limits their applications on low-capacity platforms. Adopting a coded exposure setup to encode a frame sequence into a blurry snapshot and retrieve the latent sharp video afterward can serve as a lightweight solution. However, restoring motion from blur is quite challenging due to the high ill-posedness of motion blur decomposition, intrinsic ambiguity in motion direction, and diverse motions in natural videos. In this work, by leveraging classical coded exposure imaging technique and emerging implicit neural representation for videos, we tactfully embed the motion direction cues into the blurry image during the imaging process and develop a novel self-recursive neural network to sequentially retrieve the latent video sequence from the blurry image utilizing the embedded motion direction cues. To validate the effectiveness and efficiency of the proposed framework, we conduct extensive experiments on benchmark datasets and real-captured blurry images. The results demonstrate that our proposed framework significantly outperforms existing methods in quality and flexibility. The code for our work is available at https://github.com/zhihongz/BDINR
SHoP: A Deep Learning Framework for Solving High-order Partial Differential Equations
May 17, 2023Solving partial differential equations (PDEs) has been a fundamental problem in computational science and of wide applications for both scientific and engineering research. Due to its universal approximation property, neural network is widely used to approximate the solutions of PDEs. However, existing works are incapable of solving high-order PDEs due to insufficient calculation accuracy of higher-order derivatives, and the final network is a black box without explicit explanation. To address these issues, we propose a deep learning framework to solve high-order PDEs, named SHoP. Specifically, we derive the high-order derivative rule for neural network, to get the derivatives quickly and accurately; moreover, we expand the network into a Taylor series, providing an explicit solution for the PDEs. We conduct experimental validations four high-order PDEs with different dimensions, showing that we can solve high-order PDEs efficiently and accurately.
CUTS: Neural Causal Discovery from Irregular Time-Series Data
Feb 15, 2023Causal discovery from time-series data has been a central task in machine learning. Recently, Granger causality inference is gaining momentum due to its good explainability and high compatibility with emerging deep neural networks. However, most existing methods assume structured input data and degenerate greatly when encountering data with randomly missing entries or non-uniform sampling frequencies, which hampers their applications in real scenarios. To address this issue, here we present CUTS, a neural Granger causal discovery algorithm to jointly impute unobserved data points and build causal graphs, via plugging in two mutually boosting modules in an iterative framework: (i) Latent data prediction stage: designs a Delayed Supervision Graph Neural Network (DSGNN) to hallucinate and register unstructured data which might be of high dimension and with complex distribution; (ii) Causal graph fitting stage: builds a causal adjacency matrix with imputed data under sparse penalty. Experiments show that CUTS effectively infers causal graphs from unstructured time-series data, with significantly superior performance to existing methods. Our approach constitutes a promising step towards applying causal discovery to real applications with non-ideal observations.
* https://openreview.net/forum?id=UG8bQcD3Emv
DarkVision: A Benchmark for Low-light Image/Video Perception
Jan 16, 2023



Imaging and perception in photon-limited scenarios is necessary for various applications, e.g., night surveillance or photography, high-speed photography, and autonomous driving. In these cases, cameras suffer from low signal-to-noise ratio, which degrades the image quality severely and poses challenges for downstream high-level vision tasks like object detection and recognition. Data-driven methods have achieved enormous success in both image restoration and high-level vision tasks. However, the lack of high-quality benchmark dataset with task-specific accurate annotations for photon-limited images/videos delays the research progress heavily. In this paper, we contribute the first multi-illuminance, multi-camera, and low-light dataset, named DarkVision, serving for both image enhancement and object detection. We provide bright and dark pairs with pixel-wise registration, in which the bright counterpart provides reliable reference for restoration and annotation. The dataset consists of bright-dark pairs of 900 static scenes with objects from 15 categories, and 32 dynamic scenes with 4-category objects. For each scene, images/videos were captured at 5 illuminance levels using three cameras of different grades, and average photons can be reliably estimated from the calibration data for quantitative studies. The static-scene images and dynamic videos respectively contain around 7,344 and 320,667 instances in total. With DarkVision, we established baselines for image/video enhancement and object detection by representative algorithms. To demonstrate an exemplary application of DarkVision, we propose two simple yet effective approaches for improving performance in video enhancement and object detection respectively. We believe DarkVision would advance the state-of-the-arts in both imaging and related computer vision tasks in low-light environment.
TINC: Tree-structured Implicit Neural Compression
Nov 17, 2022Implicit neural representation (INR) can describe the target scenes with high fidelity using a small number of parameters, and is emerging as a promising data compression technique. However, INR in intrinsically of limited spectrum coverage, and it is non-trivial to remove redundancy in diverse complex data effectively. Preliminary studies can only exploit either global or local correlation in the target data and thus of limited performance. In this paper, we propose a Tree-structured Implicit Neural Compression (TINC) to conduct compact representation for local regions and extract the shared features of these local representations in a hierarchical manner. Specifically, we use MLPs to fit the partitioned local regions, and these MLPs are organized in tree structure to share parameters according to the spatial distance. The parameter sharing scheme not only ensures the continuity between adjacent regions, but also jointly removes the local and non-local redundancy. Extensive experiments show that TINC improves the compression fidelity of INR, and has shown impressive compression capabilities over commercial tools and other deep learning based methods. Besides, the approach is of high flexibility and can be tailored for different data and parameter settings. All the reproducible codes are going to be released on github.
SCI: A spectrum concentrated implicit neural compression for biomedical data
Sep 30, 2022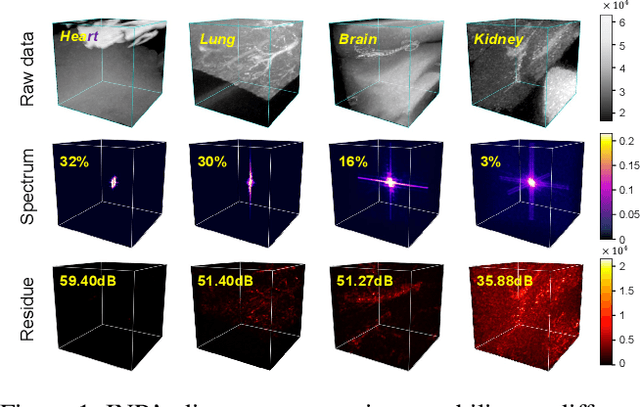
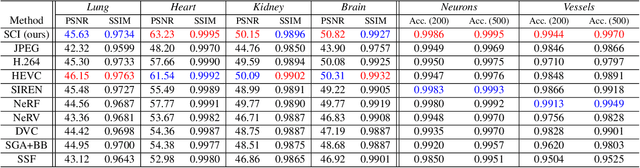
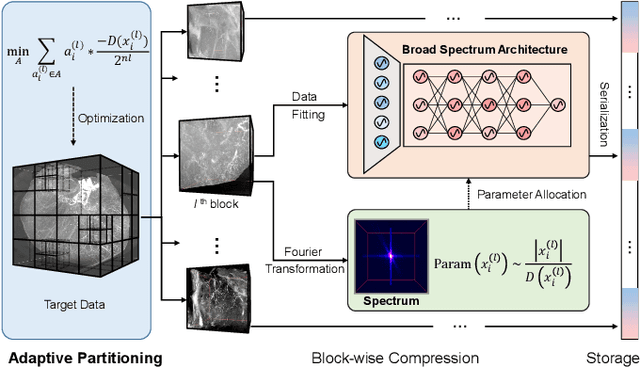
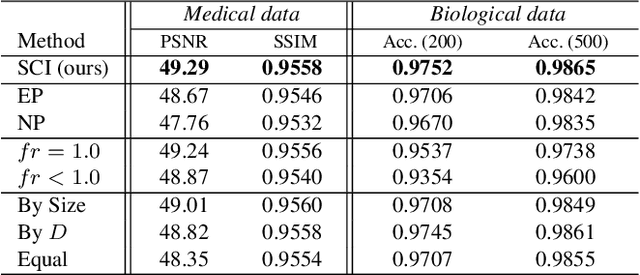
Massive collection and explosive growth of the huge amount of medical data, demands effective compression for efficient storage, transmission and sharing. Readily available visual data compression techniques have been studied extensively but tailored for nature images/videos, and thus show limited performance on medical data which are of different characteristics. Emerging implicit neural representation (INR) is gaining momentum and demonstrates high promise for fitting diverse visual data in target-data-specific manner, but a general compression scheme covering diverse medical data is so far absent. To address this issue, we firstly derive a mathematical explanation for INR's spectrum concentration property and an analytical insight on the design of compression-oriented INR architecture. Further, we design a funnel shaped neural network capable of covering broad spectrum of complex medical data and achieving high compression ratio. Based on this design, we conduct compression via optimization under given budget and propose an adaptive compression approach SCI, which adaptively partitions the target data into blocks matching the concentrated spectrum envelop of the adopted INR, and allocates parameter with high representation accuracy under given compression ratio. The experiments show SCI's superior performance over conventional techniques and wide applicability across diverse medical data.
A Dual Sensor Computational Camera for High Quality Dark Videography
Apr 11, 2022

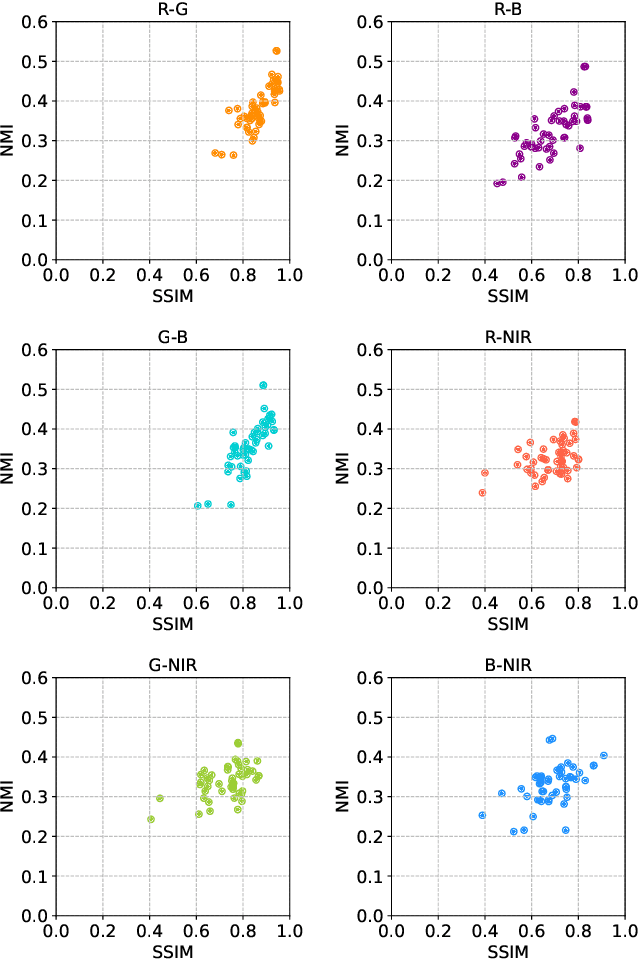
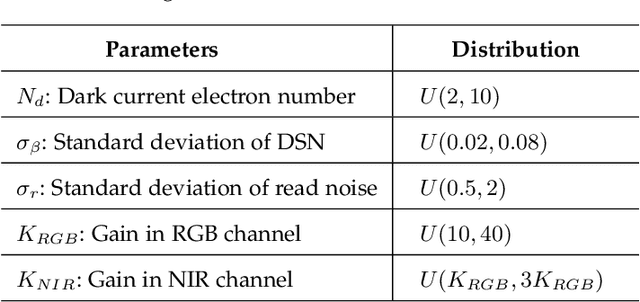
Videos captured under low light conditions suffer from severe noise. A variety of efforts have been devoted to image/video noise suppression and made large progress. However, in extremely dark scenarios, extensive photon starvation would hamper precise noise modeling. Instead, developing an imaging system collecting more photons is a more effective way for high-quality video capture under low illuminations. In this paper, we propose to build a dual-sensor camera to additionally collect the photons in NIR wavelength, and make use of the correlation between RGB and near-infrared (NIR) spectrum to perform high-quality reconstruction from noisy dark video pairs. In hardware, we build a compact dual-sensor camera capturing RGB and NIR videos simultaneously. Computationally, we propose a dual-channel multi-frame attention network (DCMAN) utilizing spatial-temporal-spectral priors to reconstruct the low-light RGB and NIR videos. In addition, we build a high-quality paired RGB and NIR video dataset, based on which the approach can be applied to different sensors easily by training the DCMAN model with simulated noisy input following a physical-process-based CMOS noise model. Both experiments on synthetic and real videos validate the performance of this compact dual-sensor camera design and the corresponding reconstruction algorithm in dark videography.