 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Who Said What to Who They Are: Modular Training-free Identity-Aware LLM Refinement of Speaker Diarization
Sep 18, 2025Speaker diarization (SD) struggles in real-world scenarios due to dynamic environments and unknown speaker counts. SD is rarely used alone and is often paired with automatic speech recognition (ASR), but non-modular methods that jointly train on domain-specific data have limited flexibility. Moreover, many applications require true speaker identities rather than SD's pseudo labels. We propose a training-free modular pipeline combining off-the-shelf SD, ASR, and a large language model (LLM) to determine who spoke, what was said, and who they are. Using structured LLM prompting on reconciled SD and ASR outputs, our method leverages semantic continuity in conversational context to refine low-confidence speaker labels and assigns role identities while correcting split speakers. On a real-world patient-clinician dataset, our approach achieves a 29.7% relative error reduction over baseline reconciled SD and ASR. It enhances diarization performance without additional training and delivers a complete pipeline for SD, ASR, and speaker identity detection in practical applications.
UM_FHS at TREC 2024 PLABA: Exploration of Fine-tuning and AI agent approach for plain language adaptations of biomedical text
Feb 19, 2025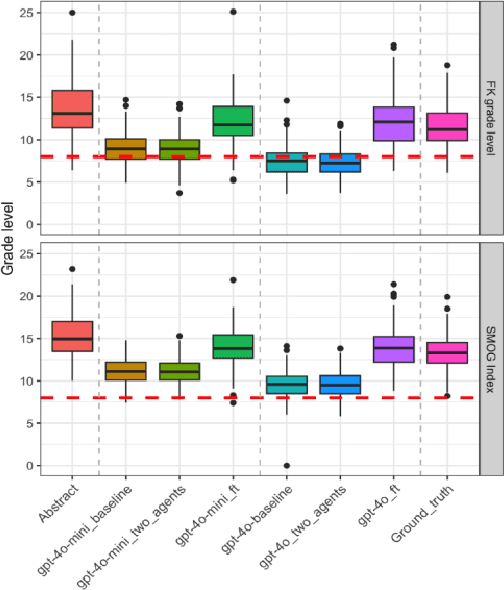
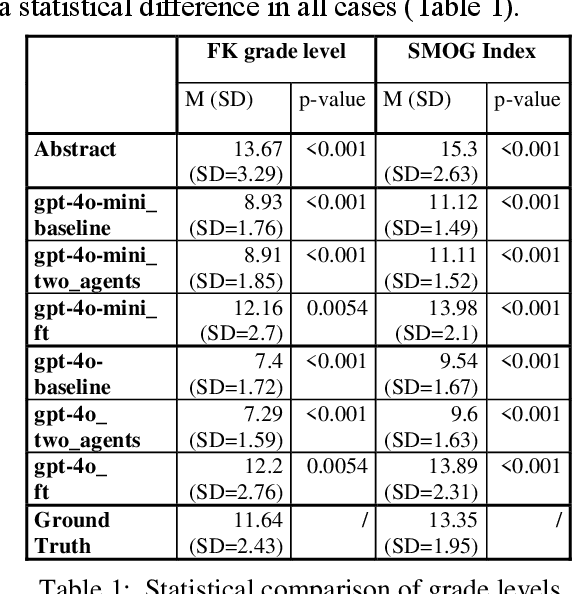
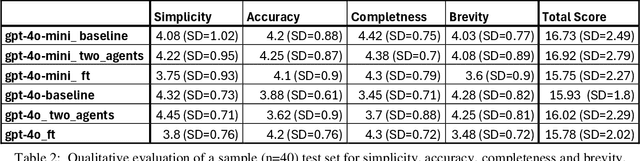
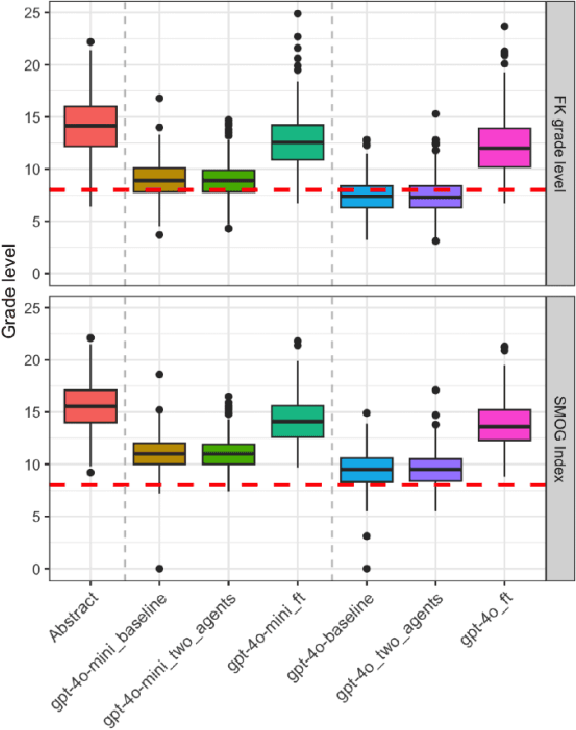
This paper describes our submissions to the TREC 2024 PLABA track with the aim to simplify biomedical abstracts for a K8-level audience (13-14 years old students). We tested three approaches using OpenAI's gpt-4o and gpt-4o-mini models: baseline prompt engineering, a two-AI agent approach, and fine-tuning. Adaptations were evaluated using qualitative metrics (5-point Likert scales for simplicity, accuracy, completeness, and brevity) and quantitative readability scores (Flesch-Kincaid grade level, SMOG Index). Results indicated that the two-agent approach and baseline prompt engineering with gpt-4o-mini models show superior qualitative performance, while fine-tuned models excelled in accuracy and completeness but were less simple. The evaluation results demonstrated that prompt engineering with gpt-4o-mini outperforms iterative improvement strategies via two-agent approach as well as fine-tuning with gpt-4o. We intend to expand our investigation of the results and explore advanced evaluations.